
- AI
- A
Sapiens: fundamental CV model for tasks with people
Almost two weeks ago, a new cool computer vision model emerged from the depths of one of the most breakthrough AI laboratories in the world, but this news seemed to pass without enthusiasm in the Russian-speaking internet. And in vain — the thing is quite good.
So, we have a family of models that will help solve "four fundamental human tasks in CV" (quote from the authors) out of the box, and let's see what is there and how it works.
I will say right away that I wanted to write a rather reminder-review post about the fact that such a model has generally been released and what to expect from it in the future. We have not yet used this in live projects (but we definitely will) and it is too early to write our big review, but I played with the demos and yes — the results are repeatable. There will be a minimum of technical details — the paper is good and it is worth reading it in full yourself, especially if you are engaged in similar tasks.
So, Sapiens.
The authors aimed to provide tools for the following tasks: pose estimation, body part segmentation, depth estimation, and surface normal prediction. It seems that Meta deliberately aimed to reduce the cost of everything related to virtual reality.
Instead of words — a video demonstration from the authors.
Dataset and pretrain
The dataset is closed and where Meta got such volumes of images with people can only be guessed シ. The initial version consisted of 1B images, which were subjected to double filtering: first filtered for the presence of inappropriate elements (text, watermarks, heavily processed photos, and so on), then passed through a bbox detector for people and removed those photos where there were no people or they occupied a small part of the photo. Only those where the box itself is larger than 300px and the confidence in it is 0.9 were left. Then everything was reduced to a square size.
As a result, a dataset of 300M photos was obtained, on which the model was trained: masked autoencoders (MAE), where the model learns to restore the original image from partially visible segments.

As a result, they got a model that "understands people well", and all other tasks were solved by fine-tuning it, mixing real data with synthetic ones. And this is something the authors are very proud of and for good reason.
The model was trained at 1k quality, which allowed for a quality leap and found many new details. If the data is of lower quality, the model predictably degrades, but according to the authors, they aimed for a certain quality level and did not have the task of maintaining lower quality.
Adjustment for specific tasks
Pose estimation
In such tasks, keypoints ("skeleton") are used to highlight body parts, resulting in understanding the pose it is in, and as the next step - understanding what exactly it is doing. This thing is used, for example, in sports, virtual reality, and in video stream analysis for specific actions (e.g., strange behavior or falling).
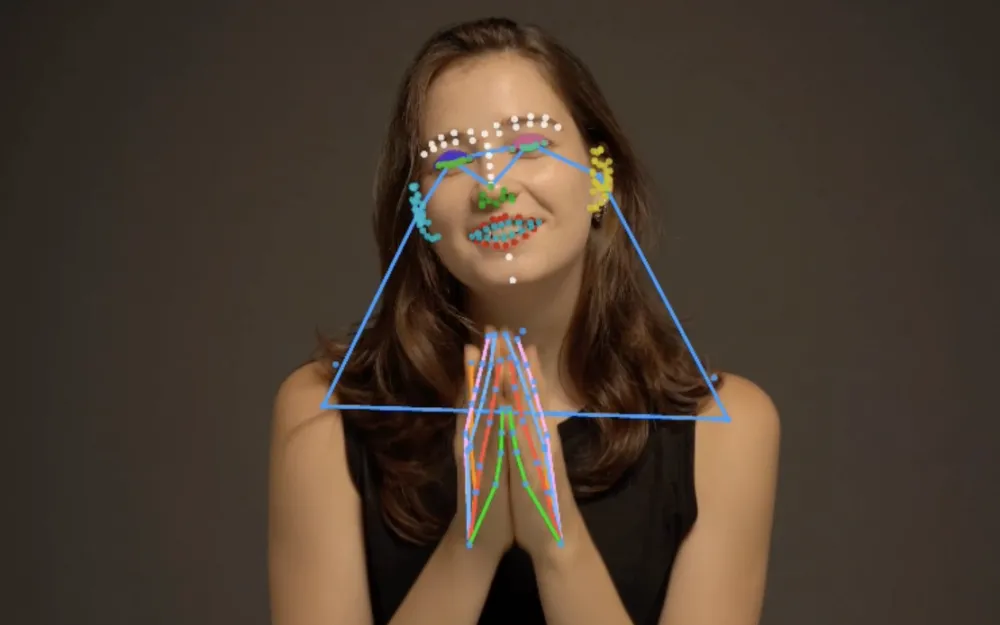
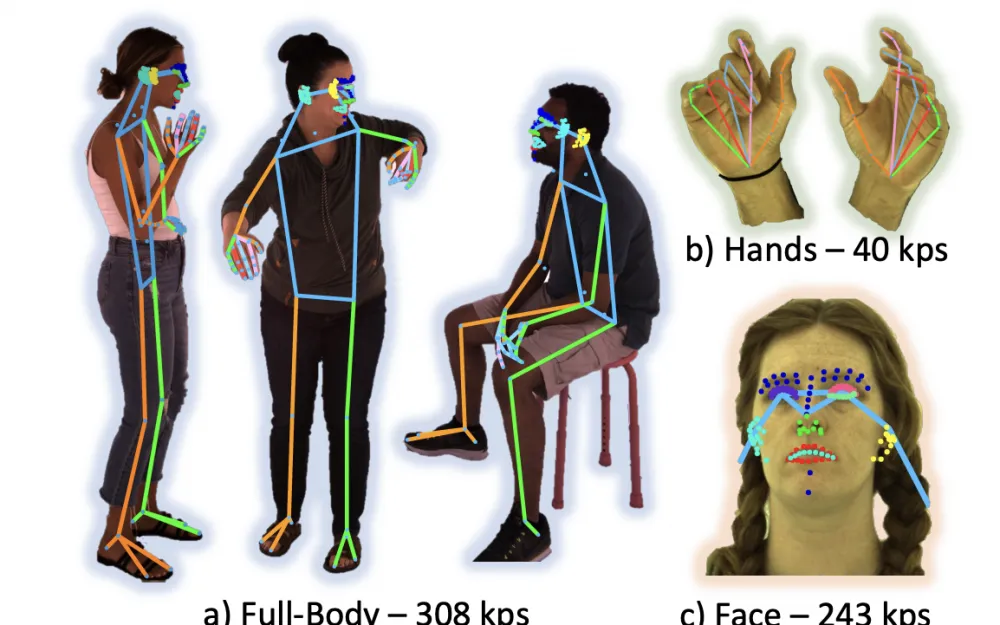
Here the authors introduced as many as 308 keypoints for pose estimation. 243 were allocated to the face (not just eyes/nose/lips/tongue, etc., but everything that can affect "facial expression") and 40 to the hands. And that's really quite good.
Interestingly: the model places points even for occluded objects, "guessing" their location.

Segmentation of body parts ("human parsing")
Such tasks allow highlighting specific body parts and analyzing them. This is used in virtual fittings, medicine, AR, sports, and for applying various filters on top.
Here too, there is a wide dictionary of body parts (and with a breakdown into right/left!): for example, a leg/arm consists of several parts that can be worked on separately.

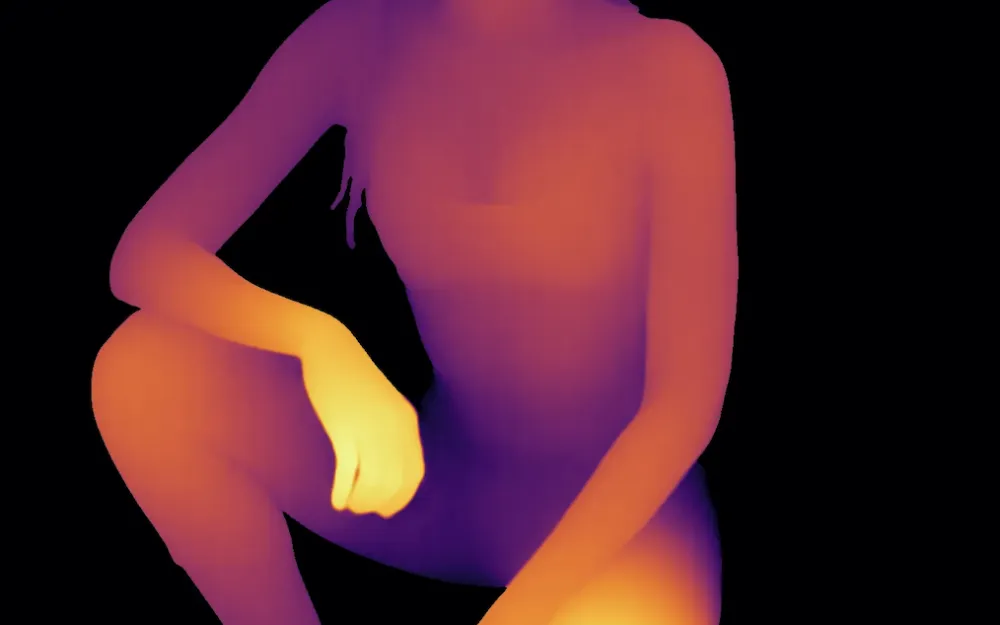
Depth estimation
The task of estimating the distance to an object. The brighter the object, the closer it is to the lens and vice versa. Application areas: autonomous transport, AR/VR, 3D modeling from 2D, medicine, gesture control of devices, and various other things.
Surface normal estimation
Such tasks are used for the reconstruction of 3D objects and subsequent analysis of their geometry, for example, to understand their physical shape, which is used in robotics, graphics, and virtual reality, of course.

Conclusions and links
The model is good! The authors claim that fine-tuning for your further needs is easy, but at the moment there is an instruction only for normals, but very soon they promise all the rest. But it is worth adding here that the model is built exclusively on people and only on them.
The code and weights are posted, including demo scripts to play with locally (to avoid problems, it is better to deploy through conda). But the dataset is not and will not be posted.
I also attach a detailed wrapper over the segmentation to run in a few steps. Or you can look at the demos on your data right on hugginface.
Useful:
Code and weights
Publication (paper)
Hugginface demos
Ready notebook for local use
My other articles:
Analysis of SAM2 through the knee to the head or a revolution in video markup
Apple office in Moscow: how I became an expert from scratch and got to a private party for developers
Thank you and good research to everyone!









Write comment