
- Software
- A
Understanding what S3 is and creating a simple object storage on Go
Hello, tekkix! Matvey Mochalov from cdnnow! is with you again, and in this post, we will not be dealing with FFmpeg - this time our "Eeeeeexperiments!" section will cover object storage. We will figure out how S3 differs from S3, and why not everything that is called S3 is actually S3. And for the sake of experiment, we will create our own simple object storage in the favorite language of all DevOps and SRE engineers - Go.
What are object storages anyway?
Object storages are a way of storing data designed to work with large volumes of unstructured information. Unlike regular file systems, where files are structured into folders, they can refer to each other in various ways, have different access levels and owners, and generally have a strict hierarchy. Object storages are as simple as possible and are represented solely by "objects," where each is a minimal set of metadata, the main one being a unique identifier for the object.
An object can be anything: an image, a video, or a text document. In addition to the identifier, the metadata also contains additional information about the object, such as creation date, file type, author, and other attributes that hardly affect the properties of the object itself, unlike similar attributes in a file system (for example, the same author), which hardly affect the properties.
The difference between object storages and traditional file systems
Traditional file systems like NTFS, EXT4, etc., organize files in a hierarchical folder structure. This model works well for small amounts of data and simple use cases where the number of files is relatively small, for example, on a personal device or a home file server. However, when the data volume starts to exceed terabytes, and the number of users is not just a few family members connecting via WiFi to a NAS to watch a movie in the evening, flip through photos, or download scanned passports, noticeable difficulties in speed and resource consumption for operations begin to arise.
Without a rigid hierarchical structure, all data access operations are reduced to simply using a key to find the desired object: no long searches through subfolders of subfolders and access rights checks. Moreover, when the main requirement for an object is its unique identifier, the system easily scales: just keep adding objects as long as there is space on the storage. And if there is not enough space, expand on the fly—no whims like with file systems, which often require formatting or at least unmounting the partition for such a trick.
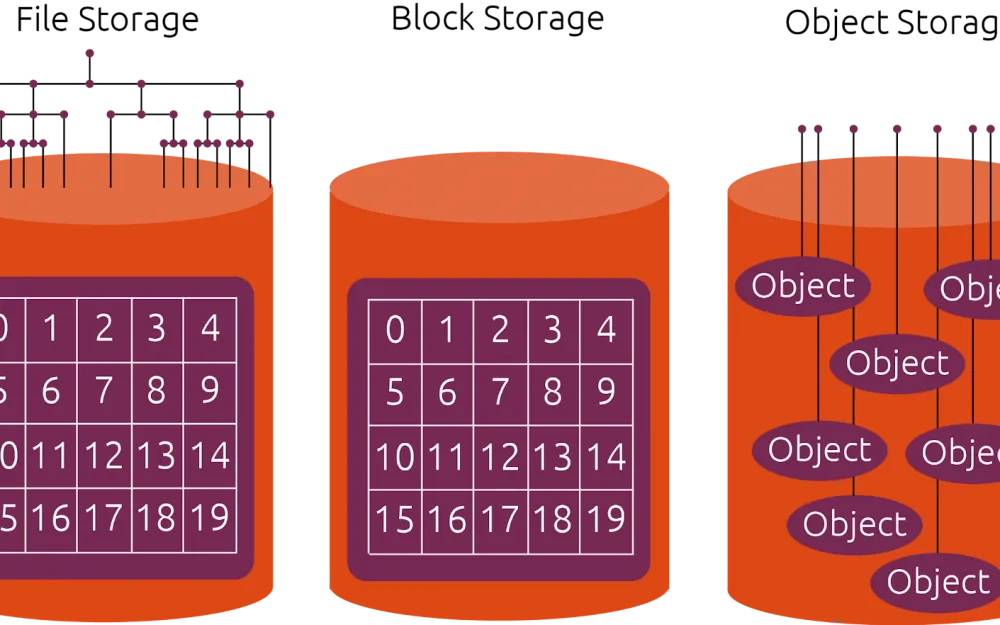
Features of Object Storage
Advantages include:
Scalability. As mentioned earlier, it easily scales horizontally by adding new nodes and increasing storage capacity. Just keep bringing new disks or storage racks to the server room.
Flexibility. Object storage can store any type of data: from small text files to large videos of cutting water from a tap with scissors for 24 hours. Everything is equally easy and simple to control through the API.
Simplicity of management. No hassle with hierarchy. Folders, subfolders, author, access rights configured through chmod — this is not about object storage. Metadata is stored together with objects, which allows them to be easily and quickly indexed.
Reliability and availability. Object storage is quite easy to decentralize on physically remote devices, where data is replicated on multiple nodes, forming a single system. This guarantees high reliability and availability even in the event of a failure of one or more nodes.
But object storage also has disadvantages — where maximum fast execution of operations or working with a large number of small files is required, it is better to look at block storage.
In addition, object storage is by definition not suitable for working with data where a strict hierarchy, various access rights, links, etc. are needed. However, this does not stop anyone from hammering nails with a microscope and turning object storage into file systems. Why — history is silent.
Application of object storage
Object storage is widely used in various cloud services and platforms, where it is often necessary to store and perform operations with large amounts of information:
Backup and Archiving. Object storage is ideal for long-term data storage, such as backups and archives. Especially when there are many backups, and they need to be made and forgotten until the next system crash.
Media Storage. If you need to create a dump for your online cinema, where you just want to throw all the files without worrying, object storage is your friend.
Cloud Applications. Cloud services and applications in the SaaS or PaaS model often use object storage to store user data, logs, reports, and other unstructured data that will generally lie idle until the second coming.
Containers and Microservices. In containerized microservice environments, object storage is used to store and transfer data between different services, ensuring the portability and decentralization of the system architecture.

What is S3?
We have dealt with the basics, and now let's talk about S3 — a service, protocol, and technology that has essentially become synonymous with the term "object storage".
S3 offers users a simple and scalable way to store data through a web interface. It supports various access protocols, including REST API, and integrates with other AWS services such as EC2, Lambda, and RDS. Due to its reliability, availability, and flexibility, S3 has become the de facto standard for cloud data storage.
It is interesting to note that, having appeared on March 14, 2006, S3 eventually became not just another service from AWS, but a benchmark for all object storage. This led to many companies and developers creating their solutions compatible with the S3 API to provide users with the ability to use the same tools and applications as with S3, but on other platforms.
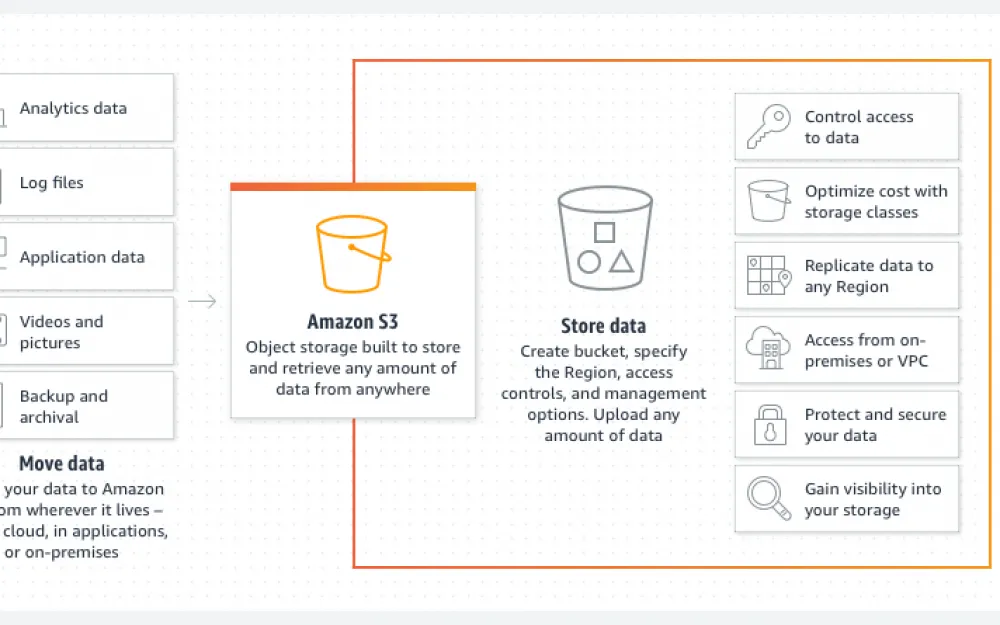
Like S3, but not S3
When we say "S3", we most often do not mean the service from AWS. S3 has gradually turned into what "xerox" has become for scanners or "google" for search engines — a household name. The term "S3" has come to denote an entire class of object storage compatible with the original API standard from Amazon.
The reason is simple: S3 appeared quite a long time ago, 18 years have already passed, that is, it played the role of a pioneer. And to top it all off, the pioneer in the person of Amazon: not only is it one of the richest megacorporations, but it also tirelessly claims to dominate the entire cloud market. The advantage for ordinary mortals is that the S3 API turned out to be extremely simple and easy to master, which contributed to its wide adaptation. As a result, the S3 API has become a kind of universal language for interacting with object storage.
However, compared to "xerox", where the term simply became synonymous with any scanner, in the case of S3, the situation is more complicated. S3-compatible storages follow a common standard. They implement the same API as the original from Amazon. That is, being familiar with the original in the AWS ecosystem, you can easily work with any other S3-compatible storages, be it Ceph, MinIO, etc.

As a result, this standardization of object storages according to the S3 template has led to an interesting effect on the market. Companies that did not want to be completely dependent on Amazon, which, it seems, even Amazon itself does not want, or looking for more economical alternatives, which also, it seems, Amazon itself wants, began to develop their own object storages compatible with S3, but which are simply called S3 storages. Although, if it were not about IT, but about food products, such a story would rather be called an S3 product identical to the natural one, or an S3 product imitation. It's as if scanner manufacturers were not just called "xeroxes", but largely relied on the documentation and standards used in the originals from Xerox itself.
Ceph, for example, through its RADOS Gateway (RGW) so well imitates S3 that most applications originally designed for AWS can easily work with Ceph as native. MinIO went even further and made compatibility with the S3 API its main advantage, making migration from AWS to its own self-hosted solution or to a provider using MinIO for S3 storages even more seamless.
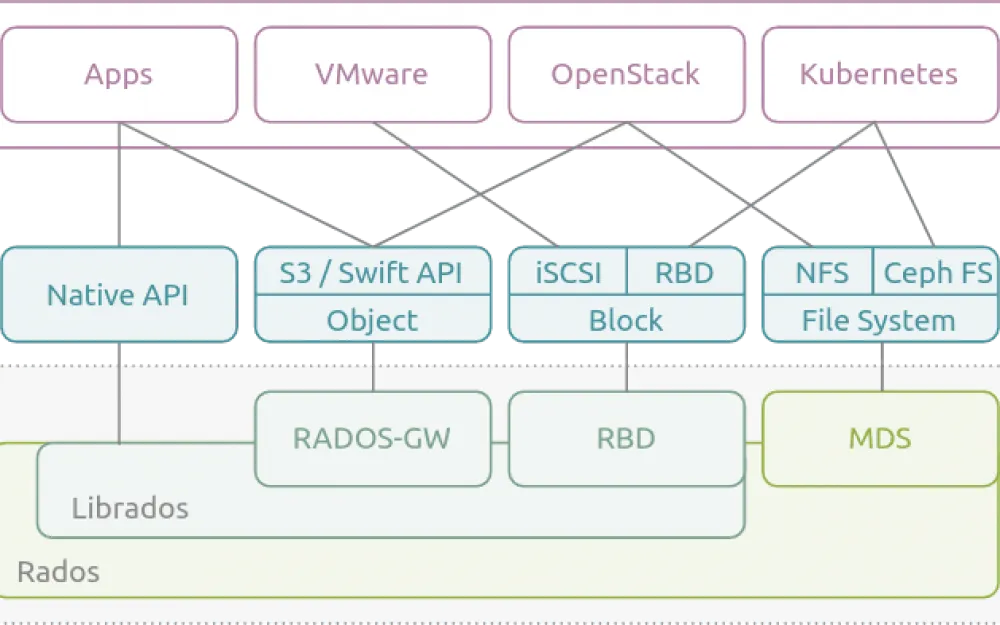
But it is worth understanding that although all these imitations use the common API and S3 standard, they can differ significantly in their backend. Ceph and MinIO are two completely different stories, with at least different performance and resource consumption levels.
Experiments Section
Theory is, of course, great, but let's move on to practice and try to write our own object storage in Go. Why? Why not?

Step 1: Creating and setting up the project
Let's start with the basics. Create a directory for our project and initialize the Go module:
'''bash
mkdir go-object-storage
cd go-object-storage
go mod init go-object-storage
'''Step 2: Writing the code
Now the most interesting part. Create a main.go file and start writing the code:
Application Architecture
Our application is a simple object storage. Let's break down its key components:
1 — Storage Structure:
'''
type Storage struct {
mu sync.Mutex
files map[string][]byte
}
'''This is the core of our storage. It uses a hash table (map) to store objects in memory, where the key is the file name and the value is its content in bytes. Mutex (sync.Mutex) ensures thread safety during concurrent access.
2 — Save and Load Methods:
'''go
func (s *Storage) Save(key string, data []byte)
func (s *Storage) Load(key string) ([]byte, bool)
'''These methods are responsible for saving and loading objects. Save stores data both in memory and on the file system, ensuring data persistence. Load first loads data from memory, and if not found there, from the disk.
-
In the current version, the application saves data to disk, but when the server is restarted, it does not load back into memory. So this is just a placeholder for future implementation.
3 — HTTP handlers:
'''go
func HandleUpload(w http.ResponseWriter, r *http.Request, storage *Storage)
func HandleDownload(w http.ResponseWriter, r *http.Request, storage *Storage)
func HandleList(w http.ResponseWriter, r *http.Request, storage *Storage)
'''These functions handle HTTP requests for uploading, downloading, and listing objects:
-
HandleUpload uploads data to the server and saves it to storage.
-
HandleDownload provides the client with data from storage upon request.
-
HandleList returns a list of all objects stored in the system.
4 — Main function:
'''go
func main() {...}
'''Initializes storage and starts the HTTP server.
The application itself
'''go
package main
import (
"encoding/json"
"fmt"
"io/ioutil"
"log"
"net/http"
"os"
"sync"
)
const (
STORAGE_DIR = "./storage" // DIRECTORY FOR STORING OBJECTS
UPLOAD_PREFIX_LEN = len("/upload/") // LENGTH OF THE PREFIX FOR THE UPLOAD ROUTE
DOWNLOAD_PREFIX_LEN = len("/download/") // LENGTH OF THE PREFIX FOR THE DOWNLOAD ROUTE
)
// Storage — structure for storing objects in memory
type Storage struct {
mu sync.Mutex // Mutex for thread safety
files map[string][]byte // Hash table for storing object data
}
// NewStorage — constructor for creating a new storage
func NewStorage() *Storage {
return &Storage{
files: make(map[string][]byte),
}
}
// Save — method for saving an object in storage
func (s *Storage) Save(key string, data []byte) {
s.mu.Lock() // Lock the mutex before writing
defer s.mu.Unlock() // Unlock the mutex after writing
// Save data in memory
s.files[key] = data
// Also save data to disk
err := ioutil.WriteFile(STORAGE_DIR+"/"+key, data, 0644)
if err != nil {
log.Printf("Error saving file %s: %v", key, err)
}
}
// Load — method for loading an object from storage
func (s *Storage) Load(key string) ([]byte, bool) {
s.mu.Lock() // Lock the mutex before reading
defer s.mu.Unlock() // Unlock the mutex after reading
// Check for the object in memory
data, exists := s.files[key]
if exists {
return data, true
}
// If the object is not found in memory, try to load it from disk
data, err := ioutil.ReadFile(STORAGE_DIR + "/" + key)
if err != nil {
return nil, false
}
// If loading from disk is successful, cache the object in memory
s.files[key] = data
return data, true
}
// HandleUpload — handler for uploading objects
func HandleUpload(w http.ResponseWriter, r *http.Request, storage *Storage) {
if r.Method != http.MethodPost {
http.Error(w, "Method not supported", http.StatusMethodNotAllowed)
return
}
// Get the key (object name) from the URL
key := r.URL.Path[UPLOAD_PREFIX_LEN:]
// Read the request body (object data)
data, err := ioutil.ReadAll(r.Body)
if err != nil {
http.Error(w, "Error reading data", http.StatusInternalServerError)
return
}
// Save the object in storage
storage.Save(key, data)
// Send response to the client
w.WriteHeader(http.StatusOK)
fmt.Fprintf(w, "Object %s successfully saved", key)
}
// HandleDownload — handler for downloading objects
func HandleDownload(w http.ResponseWriter, r *http.Request, storage *Storage) {
if r.Method != http.MethodGet {
http.Error(w, "Method not supported", http.StatusMethodNotAllowed)
return
}
// Get the key (object name) from the URL
key := r.URL.Path[DOWNLOAD_PREFIX_LEN:]
// Load the object from storage
data, exists := storage.Load(key)
if !exists {
http.Error(w, "Object not found", http.StatusNotFound)
return
}
// Send the object data to the client
w.WriteHeader(http.StatusOK)
w.Write(data)
}
// HandleList — handler for listing all objects
func HandleList(w http.ResponseWriter, r *http.Request, storage *Storage) {
if r.Method != http.MethodGet {
http.Error(w, "Method not supported", http.StatusMethodNotAllowed)
return
}
// Lock the mutex for accessing the hash table of objects
storage.mu.Lock()
defer storage.mu.Unlock()
// Create a list of keys (object names)
keys := make([]string, 0, len(storage.files))
for key := range storage.files {
keys = append(keys, key)
}
// Encode the list of keys in JSON format and send to the client
w.Header().Set("Content-Type", "application/json")
json.NewEncoder(w).Encode(keys)
}
func main() {
// Check for the existence of the directory for storing objects
if _, err := os.Stat(STORAGE_DIR); os.IsNotExist(err) {
err := os.Mkdir(STORAGE_DIR, 0755)
if err != nil {
log.Fatalf("Error creating directory %s: %v", STORAGE_DIR, err)
}
}
// Create new storage
storage := NewStorage()
// Set up routes for handling HTTP requests
http.HandleFunc("/upload/", func(w http.ResponseWriter, r *http.Request) {
HandleUpload(w, r, storage)
})
http.HandleFunc("/download/", func(w http.ResponseWriter, r *http.Request) {
HandleDownload(w, r, storage)
})
http.HandleFunc("/list", func(w http.ResponseWriter, r *http.Request) {
HandleList(w, r, storage)
})
// Start the HTTP server on port 8080
log.Println("Server started on port 8080")
log.Fatal(http.ListenAndServe(":8080", nil))
}
'''Compiling and testing
Now let's compile our application:
'''bash
go build -o object-storage
'''And let's run our freshly baked server:
'''bash
./object-storage
'''
Let's check how our creation works. Use curl for testing:
-
Uploading an object:
'''bash
curl -X POST -d "Hello, World!" http://localhost:8080/upload/hello.txt
'''-
Downloading an object:
'''bash
curl -O http://localhost:8080/download/hello.txt
'''-
Getting a list of all objects:
'''bash
curl http://localhost:8080/list
'''Voila! We have created a simple object storage in Go. Of course, this is just a basic implementation, and in the real world, you will need much more additional functionality on top. But this is a good starting point for further experiments and learning about object storage in a pet project.
P.S. As you may notice, the project actively uses the Linux file system, although earlier in the post I was ranting about how object storage is different from file systems and generally "It's different" (tm). The thing is, there's a nuance here. That was the theory, but in practice, object storage is *drum roll* – an abstraction. Yes, again. And if you look into their essence, foundation, and base, at the zero level they will use file systems to store information.
Conclusion
The history of S3 and object storage in general clearly shows the old and regularly recurring story of how technology, due to its emergence at the right time and in the right company, due to the pioneer effect and coupled with the monstrous size of the market, becomes an industry standard and a household name for its peers in the industry.
However, this would be an understatement of S3's achievements. The success of both the service and the standard was also largely ensured by the simplicity and comprehensible API and ecosystem as a whole, which allowed even beginners to easily and quickly integrate it into the infrastructure of their services and applications on the fly. As a result, further strengthening S3's position as the de facto standard for cloud storage.
In cdnnow!, as you can guess after reading this article, we provide clients with access to various storages, including S3-compatible ones, based on our implementation using Ceph. This allows flexible data management using familiar tools and processes. And also not to be afraid that due to the next package of sanctions you will have to say “goodbye” to your S3 storage within the AWS ecosystem.

Write comment