- AI
- A
How we built a model for predicting hard drive failures
Unexpected HDD failure is an unpleasant situation for a server. Identifying the causes and replacing the hard drive almost always means system downtime. At the same time, the HDD does not give any hints about its condition, specialists can only rely on the disk's operating time and their experience.
An unexpected HDD failure is an unpleasant situation for the server. Finding out the reasons and replacing the hard drive (this cannot always be done "hot") almost always means system downtime. At the same time, the HDD does not give any hints about its condition, specialists can only rely on the disk's operating time and their experience.
My name is Vladislav Markin, I am an AI software development engineer at YADRO. Together with my colleague, expert Andrey Sokolov, we decided to apply AI capabilities to predict HDD problems. The task is not trivial: the model needs data for training and practice, and where to find it is a separate question.
In the article, I will tell you what we managed to do, what became the basis of our predictive model prototype, and what results it showed when applied to disks in YADRO servers.
On what data can HDD failure be predicted
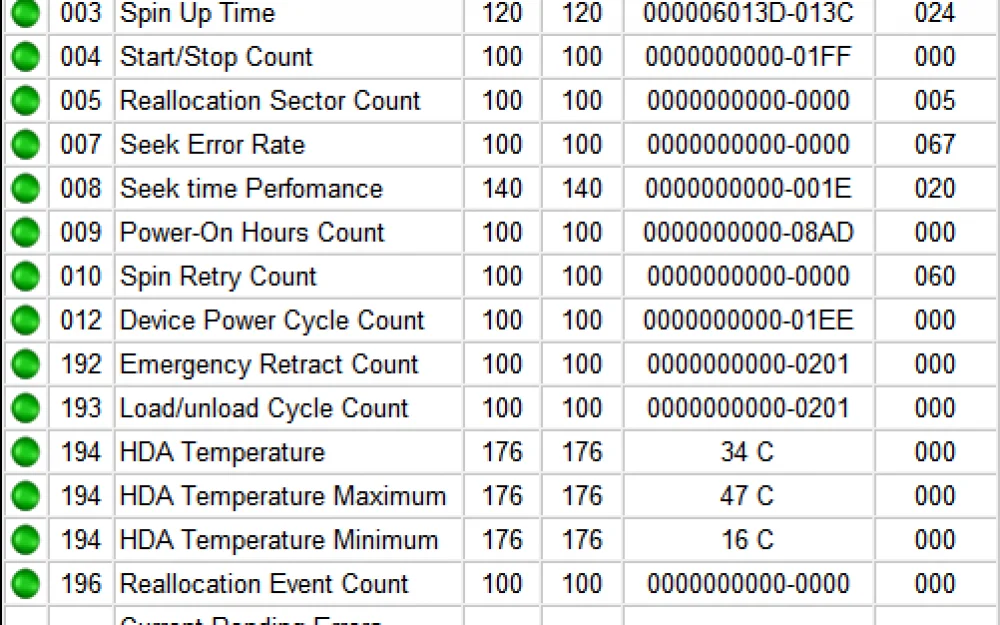
There is a fairly well-known way to diagnose the condition of hard drives - S.M.A.R.T. testing (self-monitoring, analysis, and reporting technology). As a result of the test, we get diagnostic information in the form of a set of numerical attributes. These include error counters, temperature sensor readings, and others.
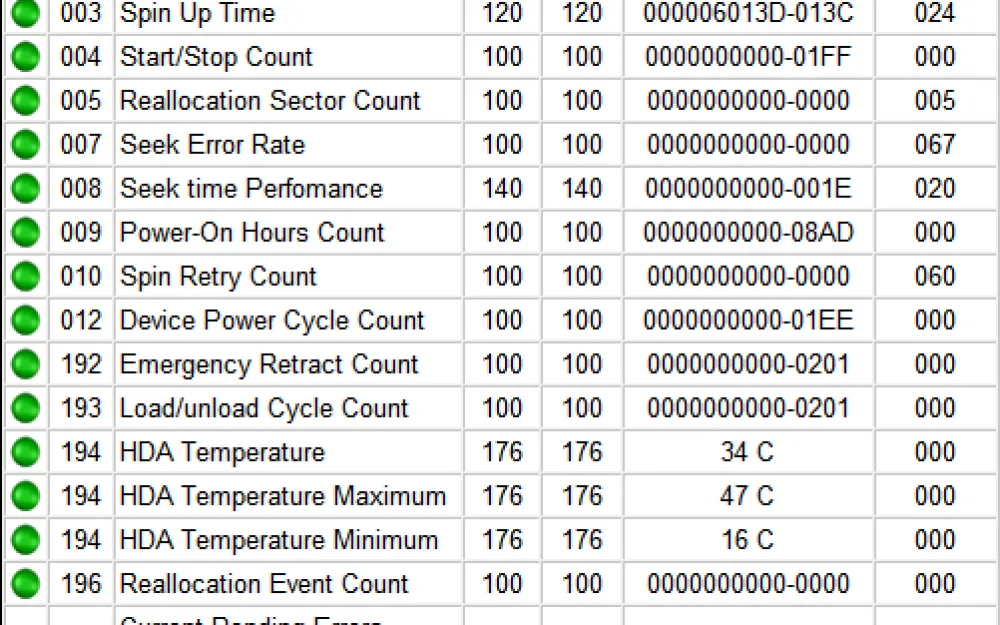
If there is a deviation from the norm in some value, it will be highlighted in red. Perhaps this is where the problem of abnormal HDD operation lies.
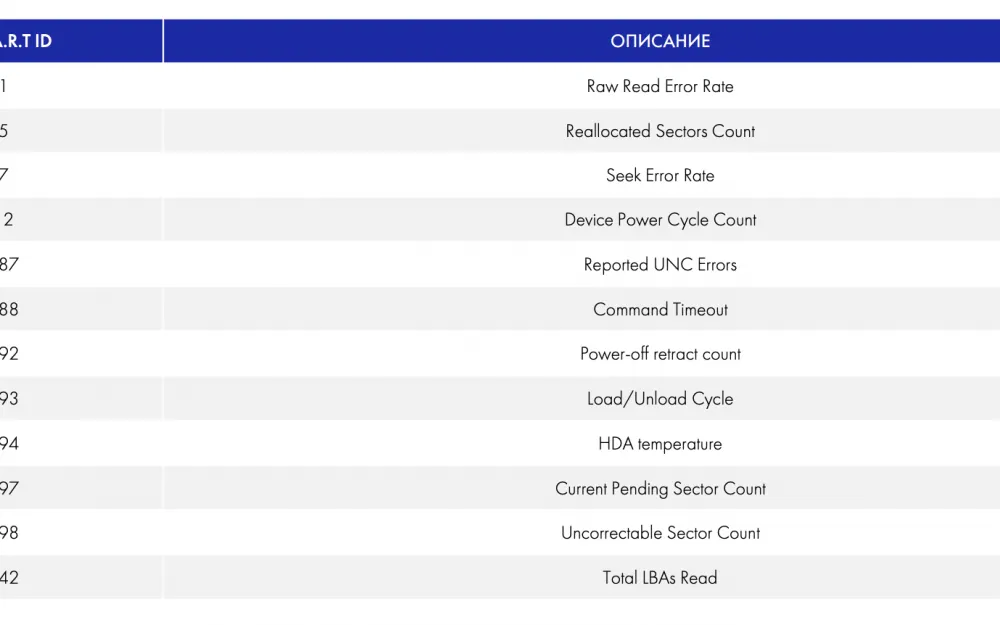
There are about 255 identifiers in total, including operating hours, the frequency of errors when positioning the magnetic head block, the number of spindle restarts after a failed first attempt, the number of defective sectors, and many others. Different disk models may have different numbers and lists of attributes — essentially, the manufacturer determines what information about the disk they consider necessary to present. On average, the disk reports up to 20 attributes.
With sufficient SMART data from a number of disks and historical data on their actual failures, it is possible to build a model that would predict whether the hard drive will fail in the near future or not.
Where to get a set of SMART data
The American cloud storage and backup company Backblaze has been publishing SMART data collected in its own data centers since 2013. In fact, at the moment, this is the most well-known public dataset with such data. For 2020 and 2023, there are SMART data collected from 85 models of disks connected via the SATA interface. Data was collected for more than 10,000 individual representatives of 14 of these models. So there is actually a lot of data.
And most importantly, this dataset is labeled. There is a Failure column, and a unit in this column means the last day of the disk's life.
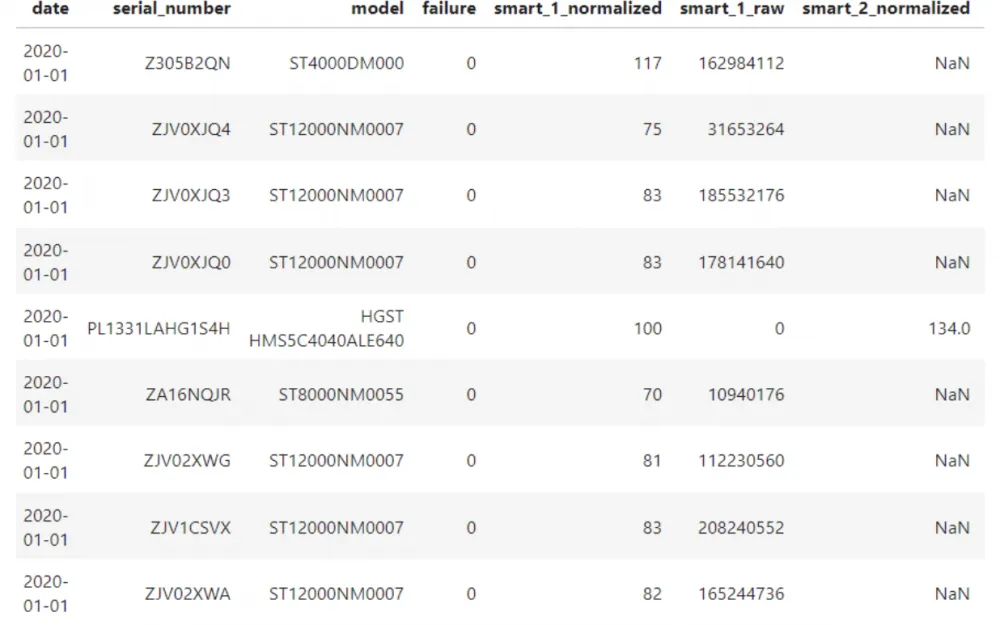
Besides this dataset, we found the results of the PAKDD2020 Alibaba AI Ops Competition from Alibaba Cloud. The participants faced essentially the same task. They needed to build an ML model that would make predictions like "will the disk fail within 30 days or not". The prediction had to be made once a day for each disk.
The dataset used by the participants is similar to the data from BackBlaze - the same records with SMART attributes. SMART data snapshots were taken from each disk once a day, and the data is presented for two disk models. Unfortunately, according to the competition rules, information about the manufacturer and disk models was closed.
The dataset used in the competition was also labeled, but the failure information was presented in a separate file in the form of failure tickets. There was the disk identifier and the time of its failure.
We found the code of the participants who took third place - here is their Jupyter Notebook. We took it as the basis of our prototype. The competition organizers also proposed metrics for evaluating the quality of ML models, we adopted these criteria, refining them.
We are looking for colleagues of various specialties to work with AI software. You may be interested in the vacancies:
→ Senior Developer (Full-Stack)
→ AI Tech Lead (LLM)
→ DevOps Engineer
ML model quality metrics for predicting HDD failure
We named the metrics k-window in honor of one of the parameters, which I will talk about below. In general, these are "classic" Precision, Recall, and F1, but with some reservations.
Precision — is the accuracy, the proportion of true positive predictions among all positive predictions of the model. In our case, the prediction is considered to be the answer to the question of whether a particular disk will fail in the near future or not. Thus, a Precision of 0.7 would mean the following: if the model predicted the failure of 100 disks, then in reality only 70 of them will actually fail in the near future.
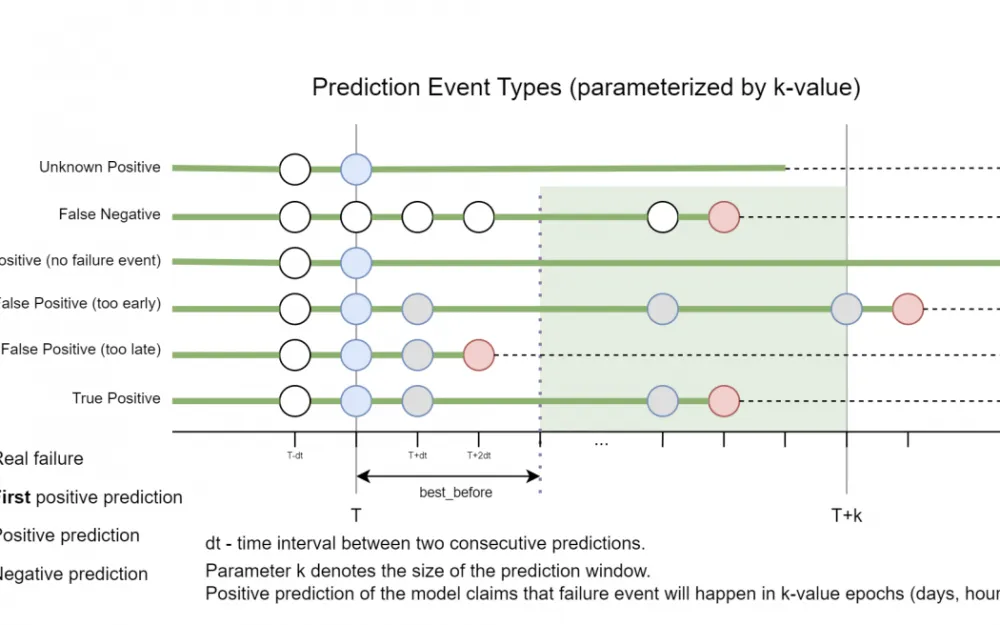
What scenarios of predictions we may have
Let's consider, based on the timeline, starting from the bottom.
Timely predicted disk failure. At a certain point in time (value
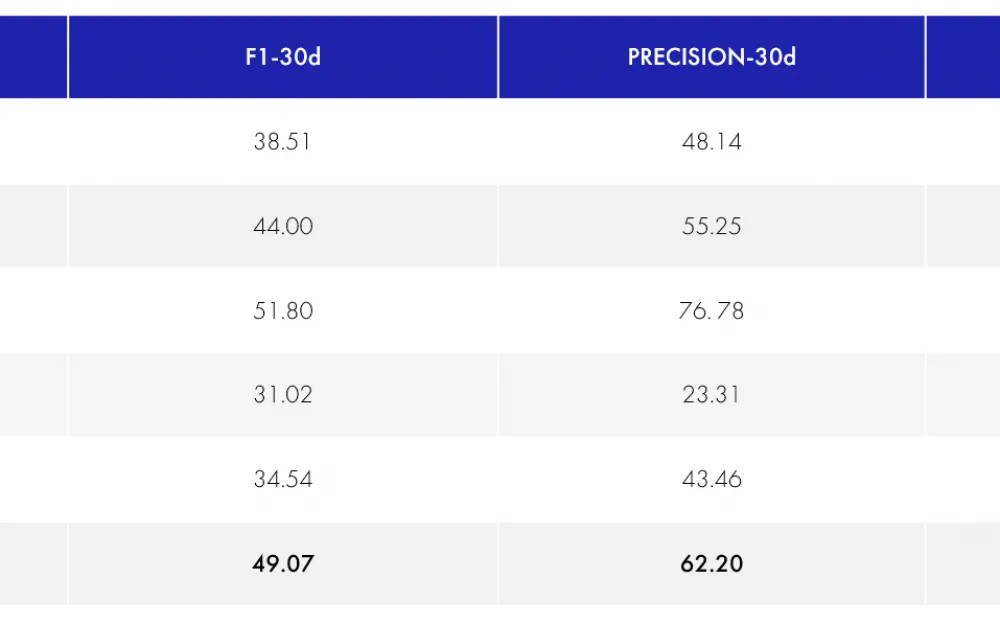
Earlier we already wrote that the model they developed formed the basis of our prototype. Therefore, we expected to get results as close as possible to these figures. Spoiler: in reality, it turned out differently. Nevertheless, this is a certain baseline from which we started. In terms of the previously described k-window metrics
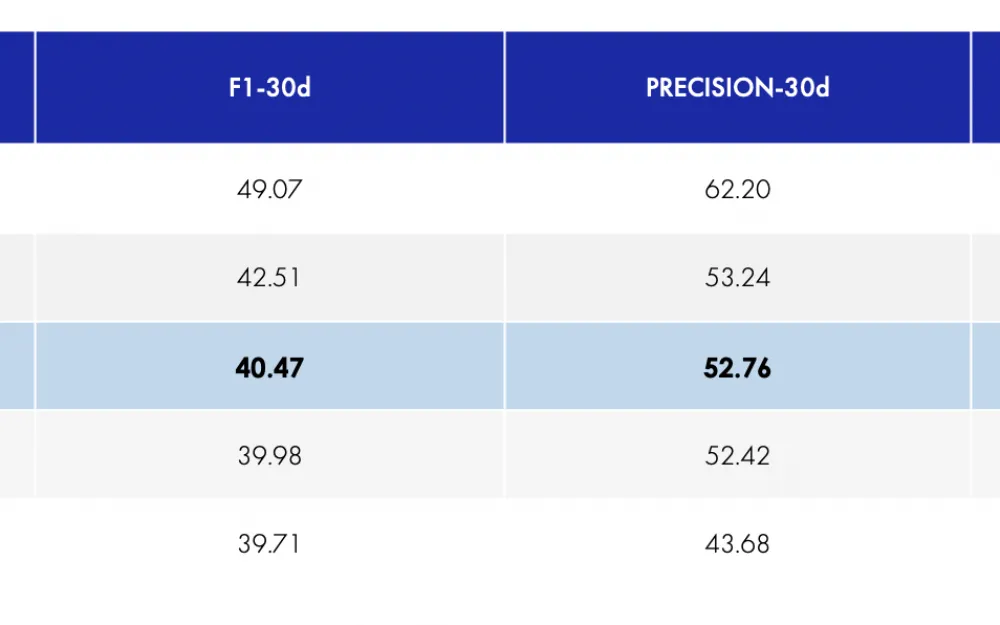
The prediction results were quite close to the baseline set by us — the figures of the team that took third place in the Alibaba competition. Recall that this is F1 — 40.47, Precision — 52.76, Recall — 32.82.
For even greater illustration, in the last line we indicated the indicators of the winning team PAKDD2020.
It is clear that we have achieved quite high accuracy with the ST14000 model. But the same Recall does not exceed 50%, which means that at least half of the failures cannot be caught.
We also received a Test Report in the form of graphs for each HDD model. Let's see what data we got for the Seagate Exos X16 hard drive (model ST14000NM001G).
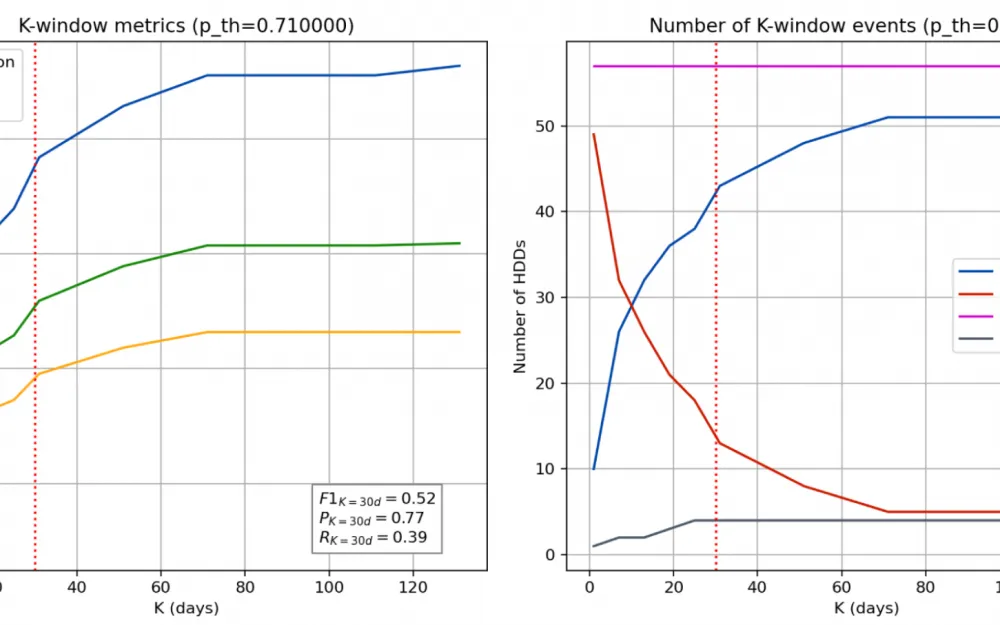
These two graphs show what the values of the Precision, Recall, and F1 metrics would be at a different value of
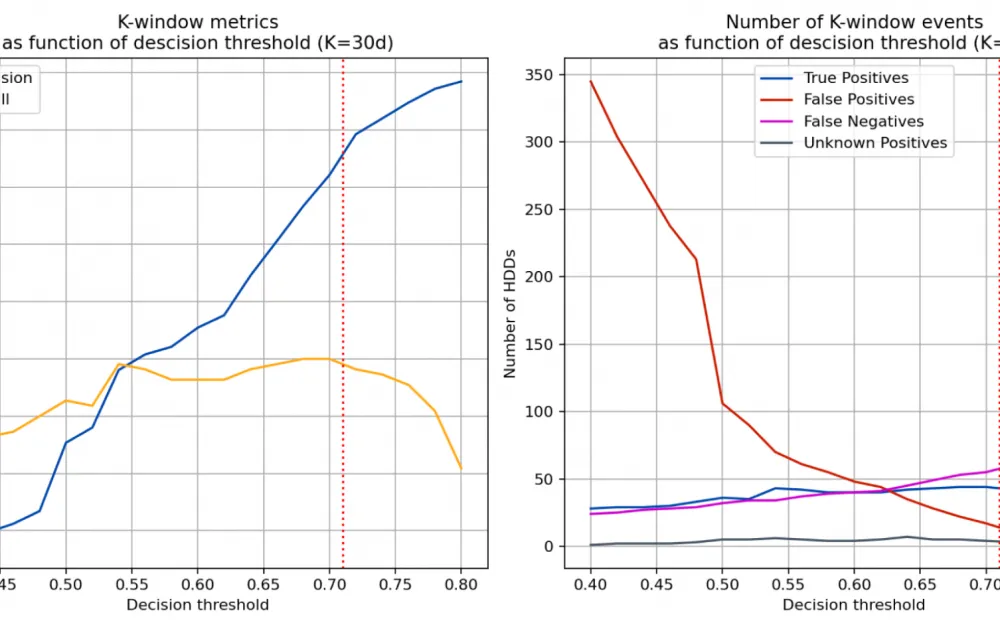
In these graphs, again, the metrics we selected, but at a fixed value of
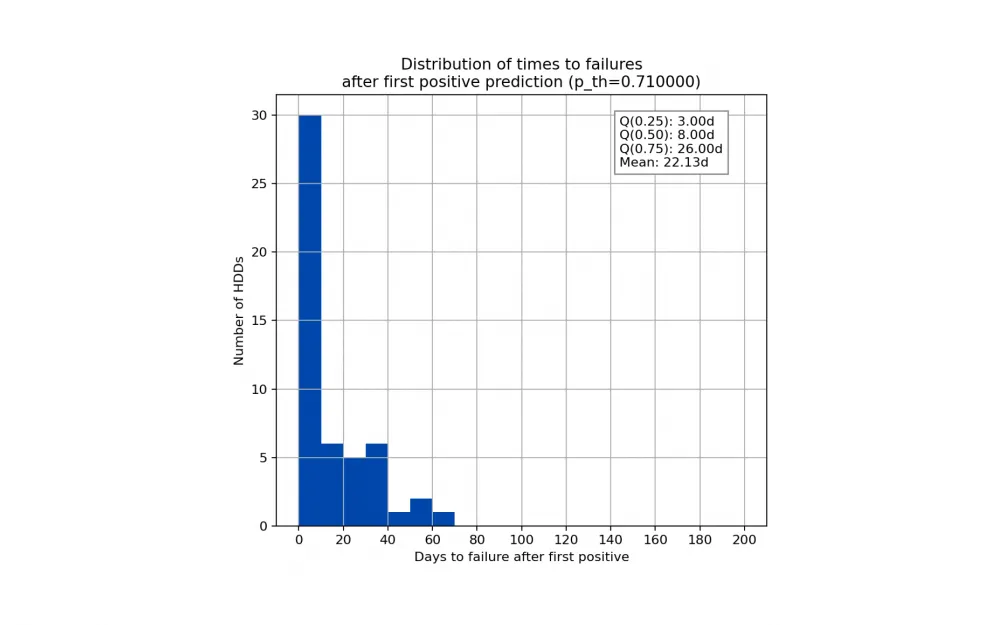
This histogram is the so-called survival time histogram. It shows the distribution of time between the first positive prediction of the model and the actual failure of the disk. Again, specifically for the selected hard drive model.
For the ST14000, it can be said that after the first positive prediction, half of the disks will fail within 8 days. For other disk models, there were single outliers in the range of 100-200 days. This suggests that some signs of failure appear in the SMART data quite early, but nevertheless do not indicate an imminent failure.
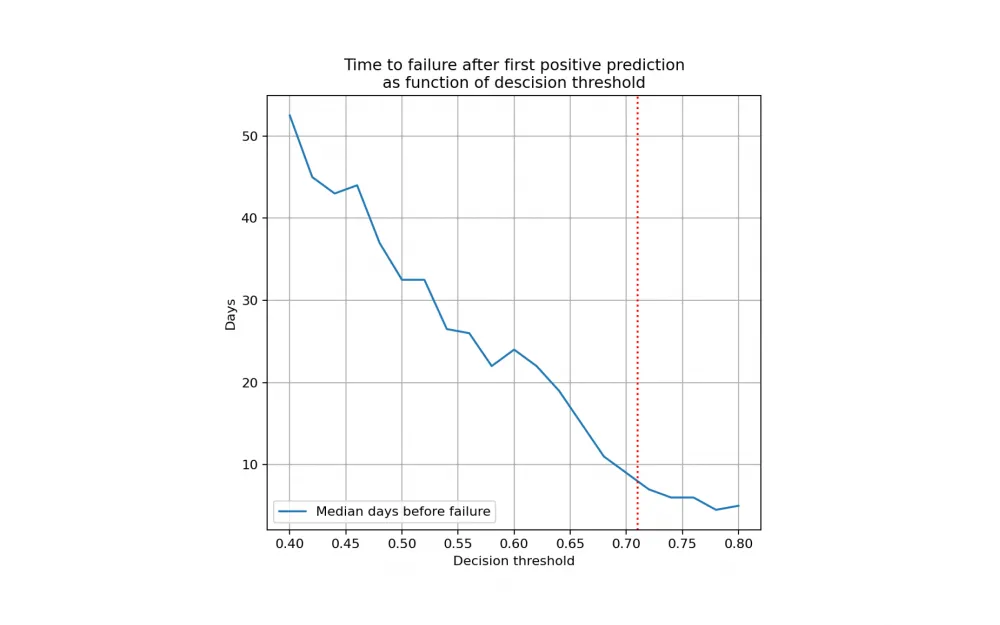
This graph shows the median disk survival time depending on the decision threshold. Previously, we gave an example where you can increase the threshold value and thereby win Precision, sacrificing the Recall metric. This will be reflected in the median survival time by a linear decrease.
At the current threshold, you can expect that there will be about one week left before failure. And by reducing the probability threshold to 0.6, we get about 20 days to react, but we sacrifice the accuracy of the forecast.
Conclusions
We managed to build a prototype model that does not depend on the execution time and the specific instance of the disks. Our test sample included disk instances with serial numbers that were not in the training, but this practically did not affect the quality of the prediction. Therefore, we believe that we have obtained a fairly universal model - there is no critical dependence on the SMART disk data used in a particular company. This means that our model does not require a complex system for the regular collection of SMART data and disk failure events. This is its main value.
However, there is a nuance: it will not be possible to write a single universal model for predicting HDD failure that is applicable to different disk models. For each disk model, you will still have to train a separate model. At least because each disk model may have a different set of SMART attributes. In addition, wear in SMART attributes manifests itself individually for each disk model.
The models we have developed so far can provide fairly high accuracy. In some cases, Precision reaches 70%, but at the same time, a significant number of failures cannot be predicted by these models. The Recall metric has never exceeded 50%, meaning that half of the disks fail for reasons that the model does not understand. These failures can be called "sudden deaths". It is likely that such a large number of "sudden deaths" indicates that SMART data is simply insufficient. And the fact that the winners of the Alibaba competition have a Recall of only 40% confirms this hypothesis.
Therefore, to develop this project, we plan to look for new data.









Write comment