- AI
- A
How to Win Kaggle Competitions: LLM Analysis of Winning Solutions
About a year ago, a Kaggle enthusiast named Darek Kłeczek conducted an interesting experiment: he collected all available descriptions of winning solutions on Kaggle from recent years, passed them through an LLM, and compiled general statistics on which mechanics and algorithms are the most successful
The guy's report turned out to be quite voluminous, interesting, and sometimes unpredictable. This article is a free author's retelling of his essay. Let Darek's quote serve as a prologue to it:
"I love to win. When I join a competition, I study the winning solutions from past similar contests. It takes a lot of time to read and comprehend them, but it's an incredible source of ideas and knowledge. But what if we could learn from all the competitions? It seems impossible, as there are so many! Well, it turns out that with LLM we can do it..."
Mechanics
First, let's figure out how it was all implemented. At the heart of Darek's analysis is the GPT-4 API from OpenAI. He used this model in two stages: first to extract structured data from the solution descriptions, and then to clean the extracted lists of methods from noise. This dataset was used as input data.
At the first step, each description is fed into the LLM so that the model extracts a list of mentioned machine learning methods from it. It would seem that this should be enough. However, it turns out that we get a rather noisy list at the output, so we move on to the next stage. Here, all the extracted methods are combined and sent back to the LLM, whose task is to standardize this list, that is, to match each method with a cleaner category or, if you like, a cluster. For example, "blurring" and "rotation" are combined into a single category "augmentation".
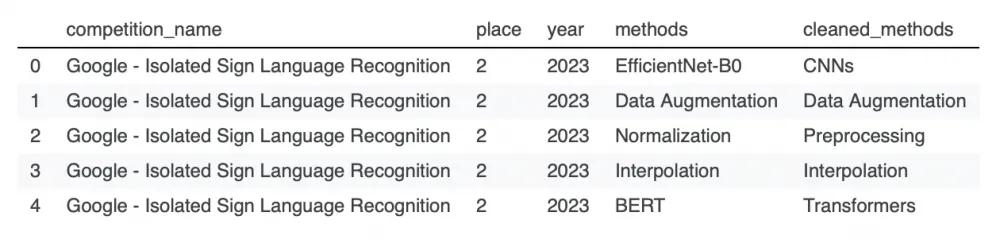
The author mentions that he also conducted additional manual data cleaning: during which he corrected some LLM hallucinations and removed noise that the model could not handle. Darek posted all the code here. He also shared the resulting dataset, by the way. So you can experiment with it yourself :)
The most popular methods and techniques
Well, now let's move on to the most interesting part - let's see what techniques and methods Kaggle competition winners use most often. By the way, if some of the methods presented in the graph below are unfamiliar to you, subscribe to our tg-channel Data Secrets: there we post daily reviews of fresh articles, useful materials, and news from the world of ML.
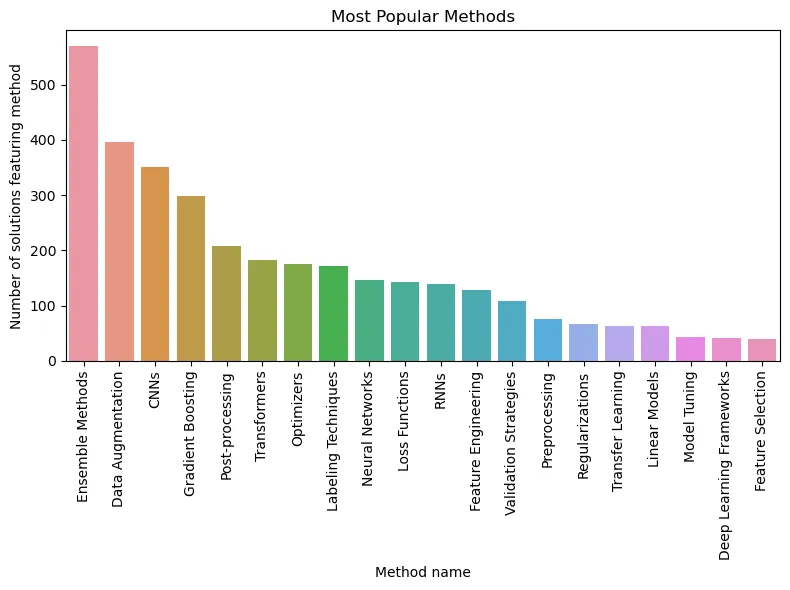
So, the histogram above illustrates that the confident first place in our ranking is occupied by ensembles (Ensemble Methods). Perhaps, it's not surprising. Well, really, who among us hasn't tried to stack or blend 100500 models?
Next – more interesting. The second place in the ranking of applied techniques was taken by... augmentation. And everyone's favorite boosting dropped to the fourth position, overtaken by convolutional neural networks.
Is augmentation important?
Or maybe we shouldn't be so surprised that augmentation took an honorable second place? In real life, the most important aspect of building a good model is the data. On Kaggle, the data is already given to us, and the main way to diversify it and make the dataset larger is augmentation. If we look at this category "under a microscope", we get the following picture:
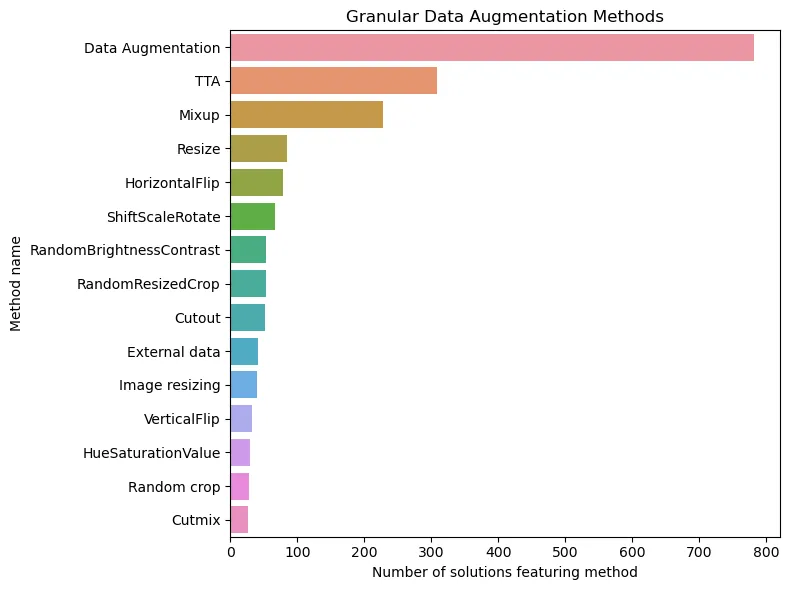
Here, in addition to the general category, we see the popular TTA (test-time augmentation) approach, a whole bunch of methods for image transformation, and finally, the addition of data from external sources. Yes, yes, this should not be shy about either. Especially now, when LLM is at hand.
By the way, about Deep Learning
What about CNN? Did we forget about convolutions in third place? It is important to remember that computer vision competitions were incredibly popular on Kaggle from 2018 to 2023. Therefore, they may have simply dominated the initial dataset on which the analysis was based. Nevertheless, the author was also intrigued by such statistics, and he decided to compare the popularity dynamics of the three main neural network architectures: convolutions, recurrent networks, and transformers, which are now considered by default to be the best architecture for almost any task. Here is what came out:
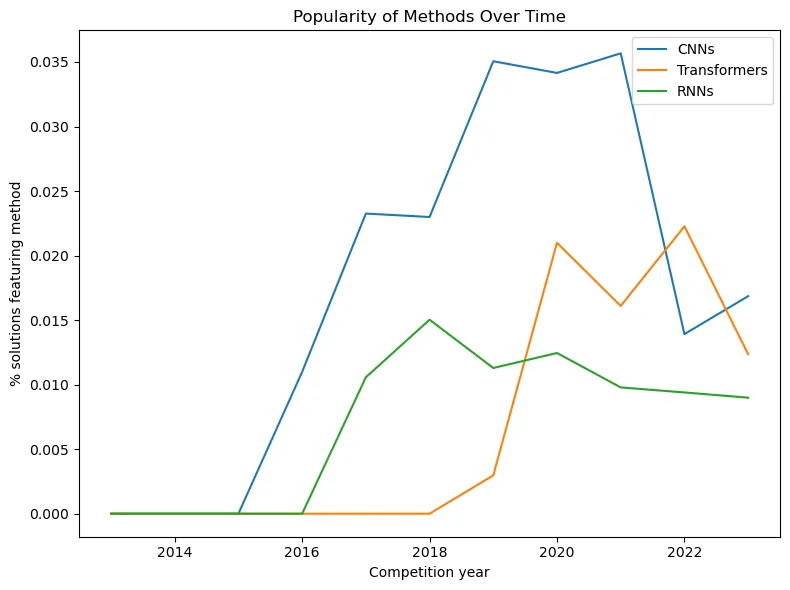
The graph shows how deep learning takes the stage on Kaggle in 2016. First, we got hooked on CNNs, and soon after, RNNs followed. Transformers were invented in 2017, started appearing on Kaggle in 2019, and reached their peak by 2022. As the popularity of transformers grew, the love for RNNs noticeably declined, but CNNs initially continued to thrive. Only in 2022, when the transformer gained real fame, did their popularity begin to fall.
Gradient Boosting
Here is another graph where our Deep Learning trio is joined by gradient boosting:
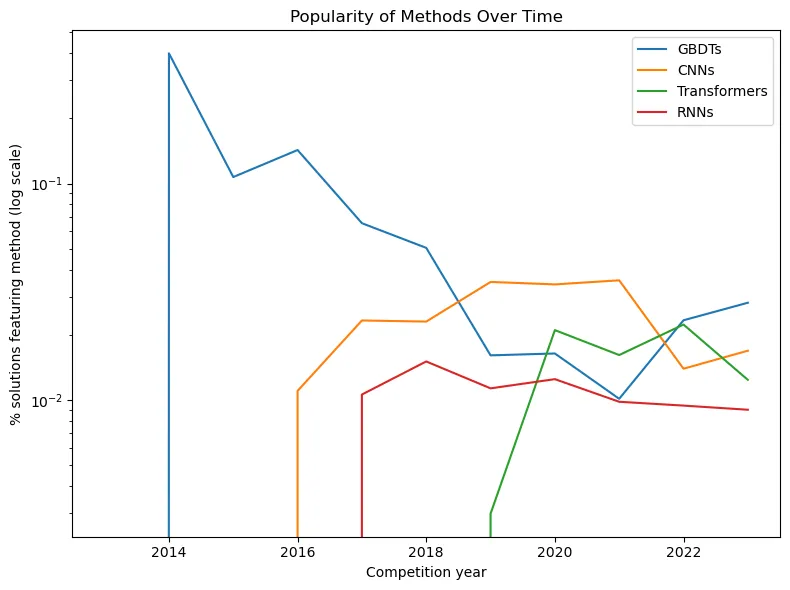
What can I say, a real dramatic fall. The dominance of gradient boosting before the deep learning era is probably not surprising, especially considering the popularity of tabular competitions at that time. Of course, then, as Kaggle added more and more CV and NLP competitions, the method ceased to be so widespread.
But pay attention to 2022 – at this time the popularity of boosting begins to grow again (by the way, the diagram has a logarithmic scale). The fact is that many participants have adapted to using GBDT in combination with transformers or other DL architectures. For example, in NLP competitions. If you want to see how such collaborations are implemented in practice, you can dive into the dataset above and use this script:
combined_methods = df.groupby(['year', 'competition_name', 'place', 'link']).agg({'cleaned_methods' : list}).reset_index()
combined_methods['both'] = combined_methods.cleaned_methods.apply(lambda x: 'Gradient Boosting' in x and ('Transformers' in x or 'CNNs' in x or 'RNNs' in x))
sample = combined_methods[combined_methods.both == True].sample(n=5, random_state=1)
for i, (_, row) in enumerate(sample.iterrows()):
print(f'[{14 + i}] {row.place}st place in {row.competition_name} ({row.year}): {row.link}')Losses and Optimizers
What else is important when we talk about training a quality model for a competition? Of course, the ability to tune it well. Hyperparameter optimization is one of the most important components of victory. In his analysis, Darek presented two interesting graphs on this topic: the most "winning" losses and optimizers.
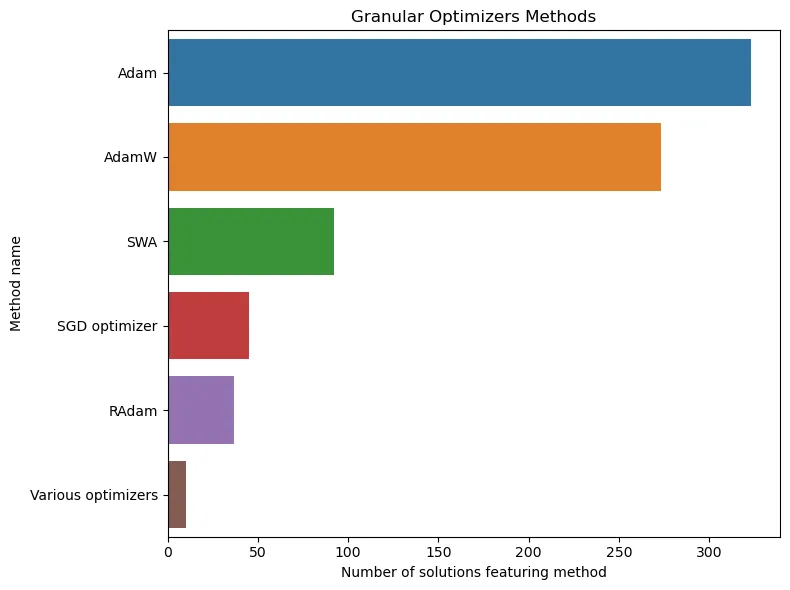
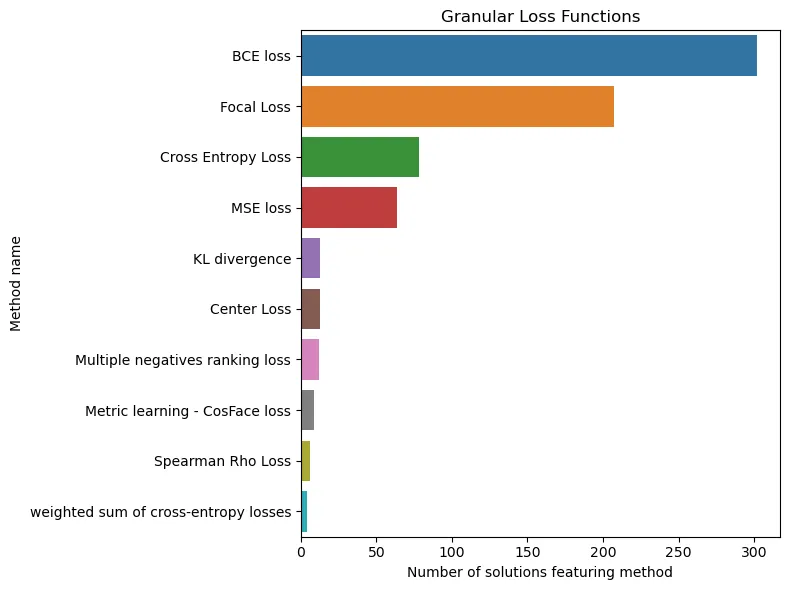
The picture turns out to be quite interesting: default losses and optimizers turn out to be the most reliable! Probably, it is not for nothing that they are considered default :) Thus, the Adam family has completely taken over the world of optimizers. The same is true for losses: with the exception of focal loss (you can read about it here), most solutions use standard CE/BCE/MSE.
Labeling and Post-Processing
The author did not analyze these sections separately for nothing: it is believed that all the magic of victory lies in them. In any case, here are the top methods that you should keep in your arsenal:
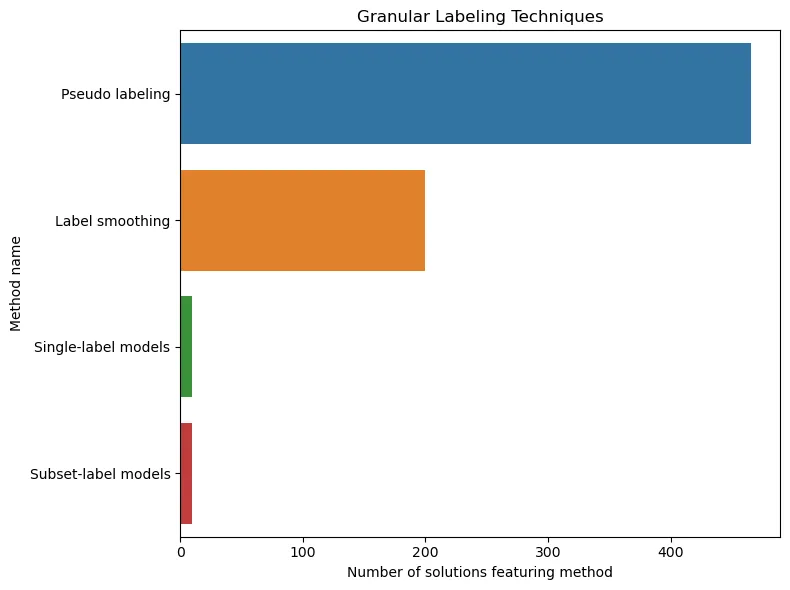
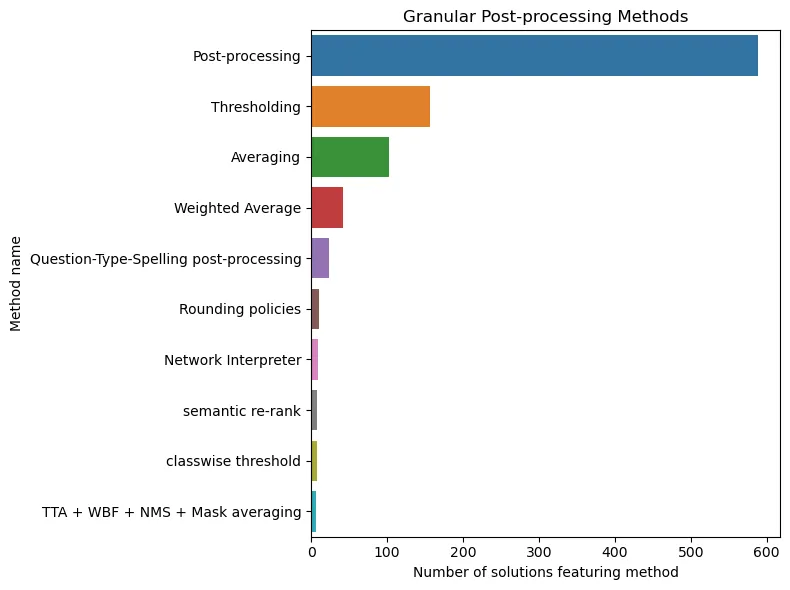
It is not surprising that the most favorite trick of the winners turns out to be pseudo-labeling and label smoothing. They really work well. As for post-processing, there is definitely magic in this top: threshold, averaging, weighted averaging – all this is definitely worth keeping in mind.
Conclusions
So. Here is what all of the above teaches us AKA your checklist for the next Kaggle competition:
Data is the key: process it correctly and supplement it competently
Don't forget about GBDT, CNN, and RNN! You will always have time to remember transformers :)
Do not ignore default configs (optimizers, loss functions)
Try pseudo-labeling
Spend a lot of time and effort on post-processing
And, of course, use good old ensembles!
More news, memes, and Easter eggs from the world of ML in our TG channel. Subscribe so you don't miss anything!









Write comment