
- AI
- A
How we researched the energy efficiency of neural network inference on a tablet
Modern gadgets are unimaginable without AI functions. But they come at a cost that the end consumer has to "pay", including faster battery drain and device overheating. As a result, electronics manufacturers face a dilemma: features are needed, many of them, but without significant damage to the battery.
Modern gadgets are unimaginable without AI functions. Blurring the background during a teleconference, suppressing noise from passing colleagues, removing "red eyes" in photos — all these have long been basic functionalities of any device with a camera and microphone. Now consumer device vendors are staging a real "arms race," offering new AI features that will make the device stand out among its "peers".
But all AI functions have a price that the end consumer has to "pay" — faster battery drain and device overheating. As a result, electronics manufacturers face a dilemma: features are needed, and many of them, but without significant damage to the battery.
My name is Pavel Burovsky, I am a software engineer for artificial intelligence. Together with Yana Bulina, an engineer in the new generation technology stack design department of the AI department at YADRO, we measured the energy efficiency of some AI functions of the KVADRA_T tablet. In the article, we will tell you how we organized the necessary experiments and show many graphs with the results of runs on CPU, GPU, and NPU.
Anatomy of AI functions: what's under the hood
Let's consider a typical scenario of blurring the background behind the user during a video conference. The application receives a high-resolution image from the camera and, using a convolutional neural network, determines where the person's face is in the image. Then it processes the picture: where the background is, it blurs the picture, where the face is, it leaves it unchanged (or feeds it to the input of the next neural network if necessary).
For neural networks, the input image needs to be prepared. Usually, they work on small-sized images with a specific color encoding. So at this stage, the video conferencing application must:
scale the image to the size of the neural network input data,
rearrange the color channels,
convert the integer color intensities of the pixels in each color channel to floating-point numbers (if the neural network inference is performed in floating-point numbers),
calibrate the intensities to the interval [0,1].
The inference result should be processed in a similar way before background blurring: return the color channel encoding, resize to the original resolution, and so on.
Which computational devices are involved
Now let's see which computational devices (in an ideal scenario) are involved and how the data moves between them.
Step 1. First, the device's camera forms the current frame. At this moment, raw data from the camera sensor goes to the ISP (Image Signal Processor). There, the primary processing of the sensor data into an image and the cleaning of this image from visual artifacts takes place. The image is ready and is transferred from the ISP to the CPU memory space, to the running video conferencing application. Some devices can transfer data from the ISP directly to the NPU, but we are describing the general case and will not go into such details.
Step 2. Frame preprocessing stage: the application prepares the image for inference. GPUs were originally designed for working with images. But the decision to use a graphics card depends on the amount of work, which, in turn, depends on the AI function. If the work is relatively small, applications can process everything on the CPU without transferring images to the GPU for a short chain of transformations.
Step 3. Inference stage: the processed image is sent to the NPU (Neural Processing Unit). This is a specialized neural network inference accelerator, which in theory should perform it faster and more energy-efficiently than other devices (we will check this in practice a little later). If we do not want to send the image for processing to the NPU or it is not available in the device, the inference will have to be performed on what is available.
Step 4. The post-processing stage of inference results. The result is sent to the CPU memory space, where the application again performs a chain of image transformations, choosing between CPU or GPU.
Step 5. Only at this stage, the final image with background blur is finally sent to the GPU video memory for rendering the picture on the screen.

Here we have examined under a "magnifying glass" perhaps the simplest AI scenario. There are also more complex cases of processing a single video frame.
For example, in a frame, it is necessary to determine the location of people's faces and check each one for authenticity: is it real or drawn on paper? Or even a photorealistic face shown on the screen of another device? Are there red eyes and where are they? Or maybe we will smooth out facial imperfections and apply makeup?
In addition, there is an audio stream simultaneously with the video stream. It may contain echo from a microphone near the speaker, the sound of a passing airplane, a moving car, or that very "indescribable" sound of a drill in concrete ceilings.
In all cases, data can run back and forth between computing devices (CPU, GPU, NPU) many times, and the number of simultaneously involved neural networks can approach a couple of dozen.
Above, we wrote that for relatively simple image processing, the application can choose between two computing devices - CPU or GPU. It won't get any easier if you consider that neural network inference can be performed on any computing device. And since inference software is written once for the entire "zoo" on the market, this software must ensure efficient execution of neural networks on all supported devices.
So, there is NNAPI — a standard API for neural network inference in Android/AOSP up to version 13. Depending on the specific tablet or phone and installed drivers, it can offer 2-4 computing devices to choose from. This can be CPU, GPU, NPU, and even DSP (Digital Signal Processor). The latter often goes in tandem with NPU, and in some devices, it can be used as an independent computing unit.
Inference Frameworks and Their Impact on Performance
So, neural network inference can be performed on different computing devices. For this, special frameworks are used, which implement inference not only on a single device but also support heterogeneous execution. The performance of inference on CPU, GPU, or NPU depends not only on the characteristics of the computing device but also on the quality of the software for it.
On devices with Android or derivative OS based on AOSP, the most commonly used inference framework is TFLite. It has a mechanism of "delegates" — software layers supporting various computing devices. Thanks to this, it is easy to run inference on CPU or built-in GPU by selecting the appropriate delegate. The performance of such inference will depend not only on the hardware characteristics but also on the quality of optimizations in a specific delegate.
Support for NPU is slightly more difficult for several reasons:
There is no framework that supports all necessary NPUs.
For CPU there is C/C++, for GPU — OpenCL/Vulkan. For NPU, there is no single programming language to make the compiler of this language responsible for supporting NPU hardware and focus in such a framework on inference logic in a unified delegate for all NPUs.
Each NPU has its own architecture and supports its own subset of neural network computational layers. NPU vendors often provide runtime for their hardware in binary form, opening only the API and some amount of documentation.
All this makes effective support for the performance of each specific NPU a non-trivial task, often requiring a dedicated team to solve.
For the KVADRA_T tablet, the built-in NPU comes with its own vendor framework, which includes an open API and a closed runtime. The performance of such an NPU for effective use in AI workloads is being studied in the department of designing new generations of YADRO's technology stack. In addition to supporting the NPU, entire teams optimize neural network inference on the CPU and GPU — from software optimization of specific layer execution to the use of tensor compilers.
Earlier, our colleague explained how to develop a tensor compiler for a processor based on the open RISC-V architecture using OpenVINO and MLIR.
How to measure computational energy efficiency
We just talked about performance — read, the runtime of a specific workload on a specific computing device among those available. But ultimately, what matters is not performance per se, but the maximum functionality for minimal battery consumption. Performance affects this: if the computation is completed faster, there is a chance that the device will go to sleep faster and not "eat" the battery. But the choice of device for inference also matters.
Which of the available devices of the KVADRA_T tablet — CPU, GPU, or NPU — is more advantageous to use for neural network inference in real scenarios? Let's find out.
To do this, we will conduct an experiment excluding the background power consumption of other tablet subsystems. However, it is impossible to measure the energy efficiency of individual chip subsystems. Reliable data requires hardware support for measuring the energy consumption level of each computational block on the chip, and it is often not available. Therefore, we will have to conduct a series of indirect experiments.
Benchmarking methodology
We will conduct experiments on a regular KVADRA_T tablet from a mass production batch. It has a debug firmware kvadraOS installed, which is as close as possible to the public version of kvadraOS 1.8.0. It allows running console applications in adb shell with root privileges, which we will use.
Now let's describe what we take into account in the experiments.
Let's switch the device to airplane mode. As a device with a radio module, the tablet works a lot even in "idle", without active user involvement. Depending on the radio pollution, it wakes up more or less frequently to process incoming signals. To eliminate uncontrolled power consumption by the radio module, we will switch the tablet to airplane mode. An integral study of the tablet's battery life with the radio module on in typical user scenarios is a separate research topic.
We will keep the screen always on. From the user's point of view, when actively using the tablet, the screen is on, and during idle periods, it is off. When the screen is off, the mobile device based on kvadraOS goes to sleep and does not perform useful work. So, when conducting experiments, the tablet should be left with the screen always on. The energy consumption for it can be considered a constant, the same for all experiments regardless of the load on the computing devices. We will disable the automatic screen off in the corresponding settings: Settings → Display & Brightness → Screen Timeout and select the Never option.
To assess the constant load from the screen being on, we will conduct two simple tests.
First, we will charge the tablet to 100%, unplug the USB cable, and let the tablet sit with the screen off for exactly 2 hours. Our tablet discharged by 1% in two hours. This way, we obtained the device's consumption level in standby mode. Therefore, all the energy consumption we measure later will likely be related to additional loads.
Then, we will prevent the screen from turning off, charge the tablet to 100% again, unplug the USB cable, and let the tablet sit with the screen on for exactly 2 hours. This time, the tablet discharged by 9%. If the first test, with the screen off, checked that there were no catastrophic hardware anomalies, this test indicates that these 9% are, in fact, the overhead from the screen being on and the active CPU running the OS of this version.
To calibrate our measurements, we will refer to a specialized measurement stand from colleagues in the kvadraOS team. The colleagues assembled it for a detailed study of how much energy various components of the tablet consume under load. The stand consists of a tablet (mass production), measuring equipment, and test lines from the measuring device to the connection points on the tablet's motherboard.

Colleagues who develop kvadraOS confirm that our measurements correspond to the observations on the stand.
Disclaimer: future updates to kvadraOS may significantly change the obtained values. During the experiments, colleagues improved parts of the operating system affecting energy efficiency, and work on improving kvadraOS will naturally continue. But for our experiment, this measurement is sufficient.
Method of conducting launches. For experiments, we will use a console application. But how to run in adb shell if the tablet is in airplane mode? For this, you will have to connect to the tablet via USB. But there is also a problem: connecting via USB additionally charges the battery.
With each application launch we:
Start with a full charge so that the USB connection at the time of launch does not add uncontrolled battery charge.
Set a persistent process to run for 2 hours using the
nohuputility and quickly pull out the USB cable.Then come back after two hours, reconnect via USB and inspect the logs.
The conditional 5 seconds that the tablet was still connected via USB at the beginning of the experiment gives a negligible error in power consumption measurements against the background of 2 hours of one test run. And if at the beginning of the experiment you put sleep 5 – in the script, the test application will not even start when we pull out the USB cable. During this time, the CPU will not have time to spin up to full speed, and power consumption when connected via USB will be minimal.
A small digression about the "scientific nature of the method" of data collection
Usually, performance benchmarking methodology involves detailed control of CPU clock speeds, binding processes to specific CPU cores, and eliminating all external "irritants". Otherwise, it is impossible to reliably distinguish the actual load under study from the "background" one. After all, the application under study does not live in a vacuum, but in an operating system that activates various background processes. Moreover, in reality, the user can (and will) run several applications at the same time.
Here we will try to navigate between two extremes.
On the one hand, we do not have microbenchmarking. We will not be able to reproduce a strictly controlled, scientific approach to benchmarking. Our workloads are complex, large applications consisting of several frameworks. And the application being launched together with all the libraries pulls on half a gigabyte of binary files. We will not be able to implement workloads similar to a realistic user scenario in the form of isolated microbenchmarks. And, trying to make the launch process close to the user scenario, we should not limit the CPU clock frequencies and the environment. The end user will not do this either. Therefore, our measurements will inevitably "float" - the only question is how much.
On the other hand, we do not do integral user testing, which is often seen in reviews of new gadgets: a tech blogger walks around with a device under his arm to work and in the sauna for a week, trying to use all the features. We have an isolated task: to evaluate whether it is possible to confidently choose a specific computing device (CPU, GPU or NPU) for the KVADRA_T tablet for a certain class of workloads.
Since we conduct a relative comparison, not a measurement of absolute indicators, in our experiment we only do uniform launches of repeated calculations and look at the battery discharge. Did the OS wake up more or less? Has the CPU clock frequency increased here and there? If you do uniform launches for several hours, the "vibrations" of the hardware and software will level out and smooth out, and the influence of "external irritants" will become more or less similar to a constant. For the experiments described in the article, we chose two hours as the minimum test run time to average the "noisy" indicators (and the maximum for our patience).
Battery discharge control method. We will control the consumption using logcat. In adb shell we will run:
logcat -d | grep healthd | grep = | tail -n 2 We will get lines like:
08-29 02:35:11.959 485 485 W healthd : battery l=81 v=8110 t=34.5 h=2 st=3 c=-512000 fc=9000000 chg=
08-29 02:36:41.815 485 485 W healthd : battery l=81 v=8104 t=34.5 h=2 st=3 c=-512000 fc=9000000 chg=Here we are interested in:
date
08-29 02:35:11.959(month, day, hour, minutes, seconds),l = 81— 81% battery charge,c = –512000: negative value — battery is discharging, positive — battery is charging, zero — battery is fully charged.
We will monitor the values from logcat at the beginning and end of the persistent process, launched using nohup. As a result, we will look at the difference in battery charge.
The script to start the load test will look something like this:
echo "sleep 5s"
sleep 5s
echo "Fingerprint:"
getprop ro.vendor.build.fingerprint
echo "time before benchmarking"
date
echo ${EXPERIMENT_NAME}
echo
echo "energy before benchmarking: "
logcat -d | grep healthd | grep = | tail -n 2
echo
export RUN="./${APP} ${RUN_OPTIONS} ${THREADING_OPTIONS}"
echo ${RUN} ${LIMIT}
${RUN} ${LIMIT}
echo "time after benchmarking:"
date
echo
echo "energy after benchmarking:"
logcat -d | grep healthd | grep = | tail -n 2We will run it like this:
nohup ./run_script.sh &Test application for load testing
For experiments, we will take a demonstration face recognition application, functionally equivalent to the scenario of unlocking a tablet by an image from the camera (face unlock). Processing each image from the incoming stream consists of three stages:
Face detection — searching for faces in the image.
Face recognition — for each found face: recognition relative to prepared samples.
Face anti-spoofing — for each found face: protection against counterfeiting, authenticity check. The tablet should be able to determine that the true owner approached it, and not an intruder with his portrait.
Each stage of processing the incoming image consists of:
image preprocessing (strictly on the CPU),
inference itself (on CPU, GPU, or NPU),
post-processing (strictly on the CPU).
Pre- and post-processing of images is done entirely on the CPU. In our application, these stages of frame processing take insignificant time (the figures and graphs proving this will be in the results section), and using the GPU will rather make them slower.
But the inference for each stage in this application can be sent to any of the available devices. TFLite 2.17.0 is used for inference on CPU and GPU, and the vendor framework works on NPU (for specificity, we will denote it with the abbreviation VFNPU below). The frame processing stages use public topology models blaze_face, ghostfacenet, and minifasnet in .tflite formats and binary VFNPU format (the result of our conversion of .tflite models to this format using the model converter from the VFNPU package). There were problems with ghostfacenet support in general, which we will describe later.
Model size and depth (in .tflite format):
blaze_face: data volume about a megabyte, 353 hidden layers,
ghostfacenet: 15.5MB, 241 layers,
minifasnet: 1.7 MB, 361 layers.
At the same time, the "complexity" of inference varies significantly from layer to layer. Also, for each type of layer, it depends on the meta-parameters of this layer: convolution dimensions, the presence of non-trivial strides, and so on.
In different inference frameworks, each neural network layer for each type of computing device is optimized differently. Therefore, it is almost never possible to accurately predict inference performance by network depth or its architecture (network topology, used layers) in advance.
There is a nuance in data types. Models for TFLite are executed in exact fp32, but this data type is not natively supported by NPU hardware — for it, models are converted to fp16 by the vendor's framework.
As part of the experiment, we did not compare the inference of models "quantized" by us into various data types (fp16, int16, int8, ...). This would require additional verification of the quantization quality. Roughly speaking, to check that a model originally calculated for inference in fp32 to detect cats in an image, after quantization to int8 still detects cats. And this is beyond the scope of the article.
Nevertheless, TFLite allows the most computationally intensive parts of the computation to be performed in fp16 with an input model with weights in fp32. This is a kind of compromise. The user does not need to perform preliminary manipulations with the input model, converting it from fp32 to fp16. At the same time, TFLite performs conversion between fp32 and fp16 "on the fly", achieving double speedups on those CPUs that already support fp16. More details — here.
The application chosen for the test is a console one. It should maximally load computing devices with work in a scenario close to real, but at the same time exclude the influence of related devices and libraries. For example, we do not want to take into account the time to capture a frame from the camera and copy the data of this frame between various HW devices and API layers in the OS. Therefore, we have prepared a selection of photos with a different number of faces on each (on average, one face per image) in advance and will cycle through it during the runs.
The application accepts command line arguments, with which you can:
Set the experiment duration (for example, 2 hours).
For each of the three stages separately: whether to perform inference on CPU, GPU, or NPU,
For each of the three stages separately: how many threads to use on the selected device. You can also not specify, then the default settings are used.
Example of launch
Before moving on to the experimental results, let's show how we obtained them. As an example, let's consider the detailed log of one of the runs. This file is the content of the nohup.out file, which can be found in the launch directory after the command nohup ./run_script.sh &.
Detailed log of one of the runs
sleep 5s
Fingerprint:
Kvadra/ts11_consumer/ts11:12/kvadraOS_Nightly_Release_2024-08-21/builduser08210506:userdebug/release-keys
time before benchmarking
Sat Aug 24 21:12:05 MSK 2024
Running inferences on: CPU (blazeface, tflite, 4cores), NPU (ghostfacenet, auto), NPU (minifasnet, auto)
energy before benchmarking:
08-25 15:44:58.686 485 485 W healthd : battery l=100 v=8650 t=27.5 h=2 st=3 c=320000 fc=9000000 chg=
08-25 15:45:01.358 485 485 W healthd : battery l=100 v=8518 t=28.0 h=2 st=3 c=-256000 fc=9000000 chg=
./face_recognition_demo_omit-frame-pointer -dfd CPU -dreid NPU -das NPU --nthreads_fd=4 -i data/images --loop --noshow --detailed_report --db data_base.json --time 7200
[ INFO ] Create face detection model
[ INFO ] Inference adapter: TFLite 2.17.0
[ INFO ] Loading model to CPU device
[ INFO ] Preparing inputs/outputs for model
[ INFO ] Model inputs:
[ INFO ] input: FP32 [1,192,192,3]
[ INFO ] Model outputs:
[ INFO ] reshaped_classifier_face_4: FP32 [1,2304,1]
[ INFO ] reshaped_regressor_face_4: FP32 [1,2304,16]
[ INFO ] Create face recognition model
[ INFO ] Loading model to NPU device
[ INFO ] Model inputs:
[ INFO ] serving_default_input_5:0: FP16 [1,112,112,3]
[ INFO ] Model outputs:
[ INFO ] StatefulPartitionedCall:0: FP16 [1,512]
[ INFO ] Initialize antispoof model
[ INFO ] Loading model to NPU device
[ INFO ] Model inputs:
[ INFO ] input: FP16 [1,3,80,80]
[ INFO ] Model outputs:
[ INFO ] Identity: FP16 [1,3]
[ INFO ] Time limit: 7200 sec
[ INFO ]
[ INFO ] Total elapsed time: 7200.1 s
[ INFO ] Total processed frames: 125471
[ INFO ] Total metrics report:
[ INFO ] Latency: 56.1 ms
[ INFO ] FPS: 17.4
[ INFO ]
[ INFO ] Face Detection Stage
[ INFO ] ---------------------
[ INFO ] Total Latency: 9.99 ms
[ INFO ] Average Detections Count: 1.0
[ INFO ] BlazeFace metrics report:
[ INFO ] Average Latency: 9.92 ms
[ INFO ] Pre-processing : 1.73 ms
[ INFO ] - Color Convert : 0.15 ms
[ INFO ] - Create Tensor : 0.45 ms
[ INFO ] - Interop : 0.14 ms
[ INFO ] - Normalize : 1.60 ms
[ INFO ] - Resize : 1.43 ms
[ INFO ] Inference : 8.16 ms
[ INFO ] Post-processing: 0.02 ms
[ INFO ]
[ INFO ] Antispoofing Stage
[ INFO ] ---------------------
[ INFO ] Total Latency: 5.03 ms
[ INFO ] Average Inferences Count: 1.0
[ INFO ] MiniFASNetV2 metrics report:
[ INFO ] Average Latency: 4.80 ms
[ INFO ] Pre-processing : 0.97 ms
[ INFO ] - Create Tensor : 2.55 ms
[ INFO ] - Crop : 425.97 ms
[ INFO ] - Interop : 3.16 ms
[ INFO ] - Resize : 157.63 ms
[ INFO ] - Transpose : 35.88 ms
[ INFO ] Inference : 3.83 ms
[ INFO ] Post-processing: 0.00 ms
[ INFO ]
[ INFO ] Face Recognition Stage
[ INFO ] ----------------------
[ INFO ] Total Latency: 14.97 ms
[ INFO ] Average Inferences Count: 1.0
[ INFO ] GhostFaceNet metrics report:
[ INFO ] Average Latency: 14.31 ms
[ INFO ] Pre-processing : 1.00 ms
[ INFO ] - Color Convert : 14.95 ms
[ INFO ] - Create Tensor : 5.88 ms
[ INFO ] - Interop : 1.83 ms
[ INFO ] - Warp Affine : 618.56 ms
[ INFO ] Inference : 13.31 ms
[ INFO ] Post-processing: 0.00 ms
[ INFO ]
[ INFO ] Re-ID Stage
[ INFO ] ----------------------
[ INFO ] Total Latency: 0.04 ms
[ INFO ] Number of faces in data base: 2
[ INFO ]
[ INFO ] Resources usage:
[ INFO ] Mean core utilization: 11.7% 8.8% 8.9% 6.2% 17.7% 32.5% 14.7% 32.0%
[ INFO ] Mean CPU utilization: 16.6%
[ INFO ] Memory mean usage: 2.0 GiB
[ INFO ] Mean swap usage: 0.0 GiB
time after benchmarking:
Sat Aug 24 23:12:06 MSK 2024
energy after benchmarking:
08-25 17:44:49.835 485 485 W healthd : battery l=72 v=7952 t=33.0 h=2 st=3 c=-512000 fc=9000000 chg=
08-25 17:44:58.637 485 485 W healthd : battery l=72 v=7930 t=33.0 h=2 st=3 c=-512000 fc=9000000 chg=Let's consider this log from top to bottom:
We see the so-called
fingerprint, that is, the string identifier of the tablet's operating system build. This is useful for tracking logs during the experiment (while we were preparing the article, several kvadraOS firmware versions changed).The current date of the experiment — note the difference in date and time from the
datecommand and in thehealthdlogs (we shrug and move on).Then the log specifies how exactly the stress test was run. face detection — on the CPU in 4 threads using the TFLite framework, face recognition and antispoof — on the NPU using the vendor's framework in automatic load distribution settings across the NPU cores.
Next is a fragment of the
healthddaemon log, launched before the stress test: the log shows that the launch starts with 100% battery charge, but the battery discharge has already begun (the valuec = –256000is negative).Then we see a large block of the stress test launch, followed by another output of the
datecommand and a fragment of thehealthdlog collected immediately after the calculation.From the last lines of the log, it is clear that the calculation ended at 23:12:06 (starting at 21:12:05 and taking two hours) and the battery discharged to 72%.
Note that the binary name of the console application contains omit-frame-pointer. We compiled the applications in two ways, including with the -fno-omit-frame-pointer option, which is useful for profiling the application and unwinding the stack. During the "trial" runs, we checked with the profiler that during the run, a negligible amount of time was spent on system calls and OS activity. The runs included in the experiment results were conducted without the profiler and using the build without the -fno-omit-frame-pointer option.
The test outputs a detailed log at startup, showing, for example, the following:
the launch was limited to 7200 seconds,
during this time 125,471 frames were processed,
the metric value
then there is a detailed launch for three stages of frame processing; it follows that, for example, in the case of face detection preprocessing was 1.73 ms, postprocessing — 0.02 ms, inference dominated the launch at 8.16 ms.
the average CPU load during the launch did not exceed 17%, which is logical given the relatively large time spent on inference on the NPU.
Note that the launch of the ghostfacenet model dominates compared to the inference of the other two models. It would be great to explain this with the neural network architecture, but here begins the plot of another article. It is also interesting that the total delay for frame processing (Latency value 56.1 ms in the Total metrics report section) is greater than the sum of the delays of the three stages of frame processing: somewhere "disappeared" 56.1 − 9.99 − 5.03 − 14.97 = 26.11 ms. In fact, they went to read the frame, copy data, render the image, and other overheads.
We are not surprised: every computation has overheads, they are also space/opportunities for optimizations. The selected application does not claim optimal performance, it is rather a mock functionality of unlocking the tablet by face. When implementing the considered AI function in some other application, the overheads will be different. However, in our experiment, such additional delays make the connection between the performance of individual computation stages and the final energy consumption less obvious.
Results
We conducted application launches in the following combinations:
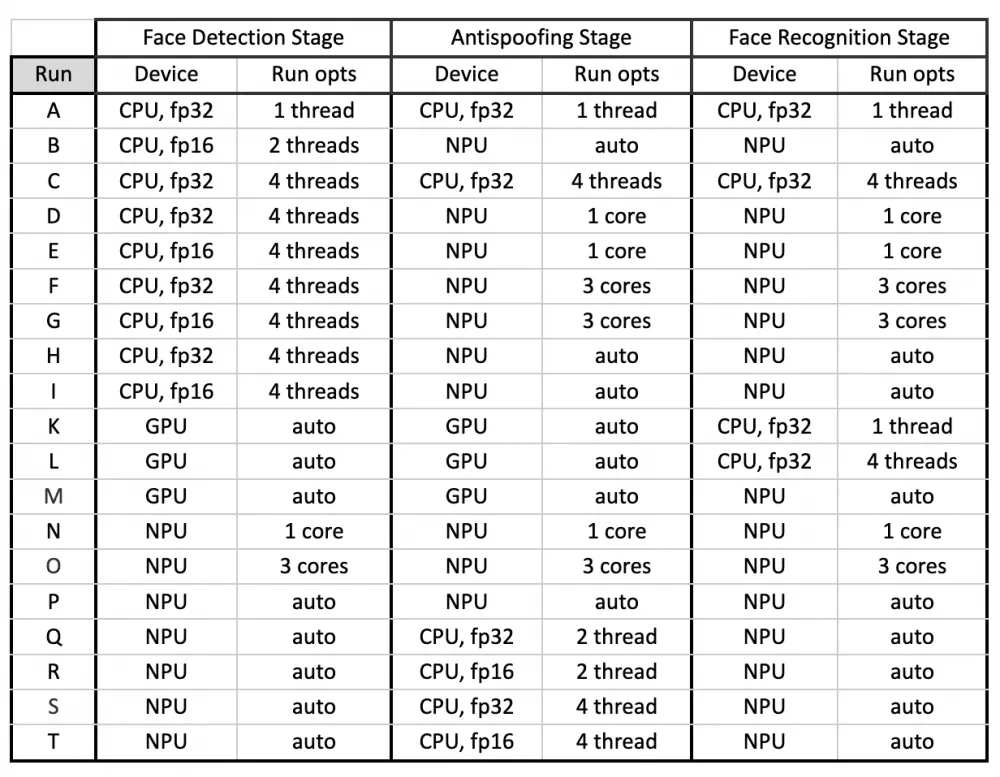
We conducted launches on the CPU for 1, 2, and 4 threads. We did not control clock frequencies and thread binding to cores, because the user will not do this.
We are aware that in a final high-load application with a large number of AI functions, these loads may be placed on completely different cores. Moreover, during the execution of the application, they could migrate from one core to another (remember that modern mobile big.LITTLE devices usually have CPU cores of different performance). We do not aim to consider all possible scenarios within the framework of the article.
Also, for CPU runs, we compared inference in fp32 — the native precision of the original model — and in fp16. For fp16, we did not quantize the model but used the parameter of our console application to call the XNNPACK delegate TFLite, which provides the ability to force inference in fp16 regardless of the model metadata. In this case, the data is converted from fp32 to fp16 "on the fly".
When choosing parameters for our runs, we encountered several problems related to the limited support of the ghostfacenet model for the face recognition stage. Inference for it crashes in two cases:
when running with the GPU delegate TFLite,
when running with XNNPACK as the CPU delegate TFLite in fp16 precision.
Investigating the causes of crashes and fixing them is not the topic of this article. We simply discarded all combinations of unsuccessful runs. Therefore, when running other models on the GPU, we will perform inference of this particular model on the CPU or NPU. And for CPU runs, we use the reference CPU delegate.
For GPU runs, we used the default settings. We did not engage in optimal parameter selection for GPU runs for two reasons. First, it is a separate large task. Second, as we have already written, for this article, we were interested in the support of computing devices by frameworks "out of the box", without fine-tuning.
When inferring on the NPU, we distinguished the following runs:
in the default setting,
running the entire inference on one NPU core,
running on three cores at once.
Explanation. The vendor's framework distinguishes four types of flow control: automatic, where the load distribution between the three NPU cores is determined by the framework, and three modes of load distribution between one, two, and three cores at once. Here we tested three out of four options.
Processing time of one frame
First, let's see where the time is spent in the process of processing one frame. Using the example of running H, the log of which we have already provided in the previous section:
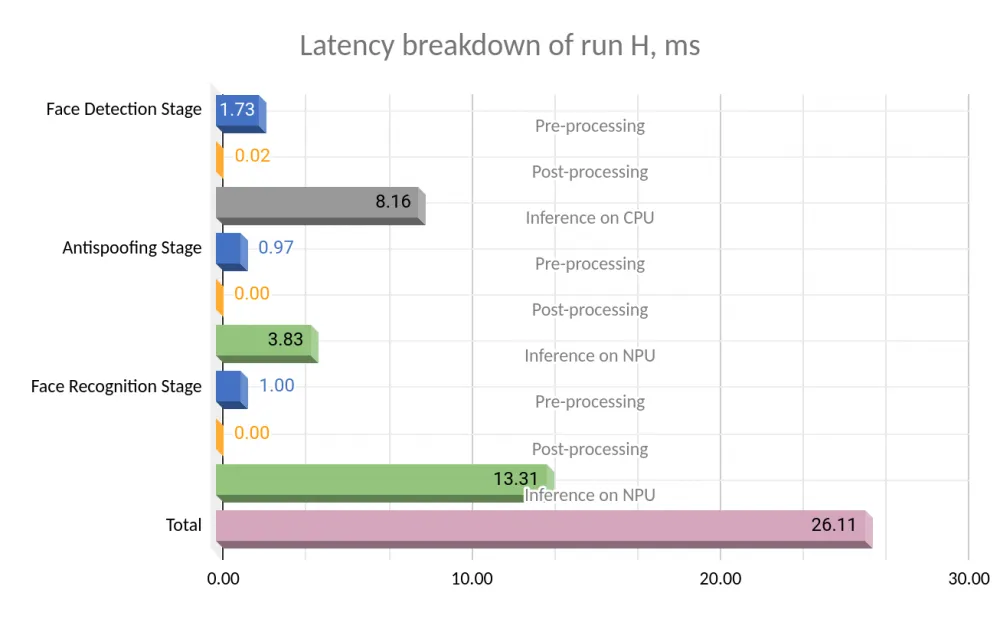
Here the color scheme (blue, orange, gray, green) corresponds to the color scheme of the diagrams given in the next section:
green denotes inference on NPU,
gray — inference on CPU,
other colors (blue, orange) — execution of various preparatory and other calculations on CPU.
pink — total overhead for frame processing specific to this demo application, which we discussed in the previous section.
Comparison of inference performance on different devices
The following three graphs for each stage of frame processing (face detection, face recognition, antispoof) compare the inference performance on different computing devices (CPU, GPU, and NPU). For clarity, in addition to the inference time, we also added the preprocessing and postprocessing time of the corresponding frame processing stage.
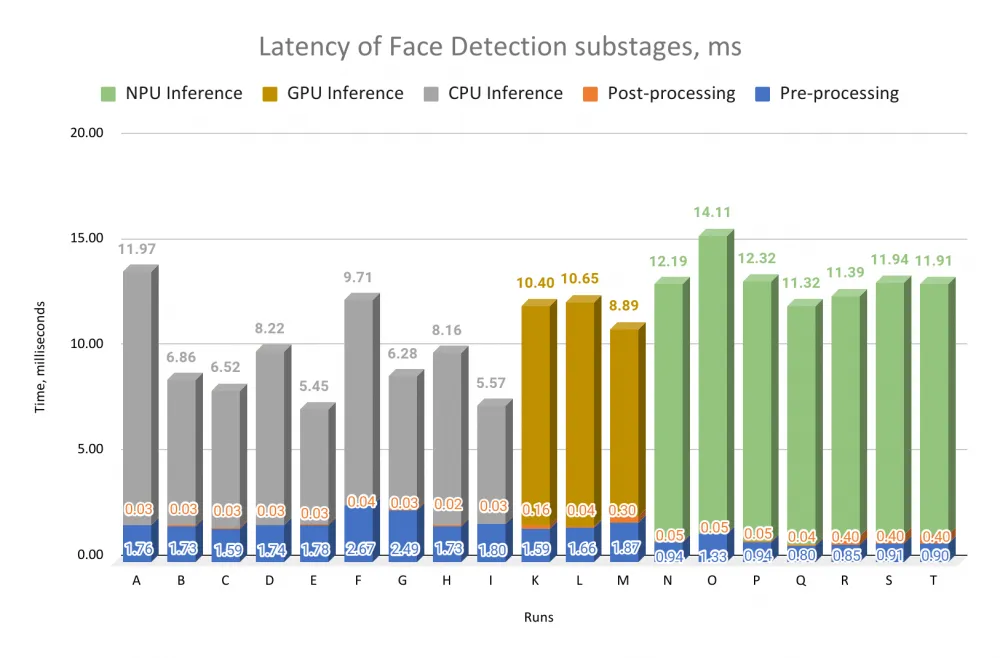
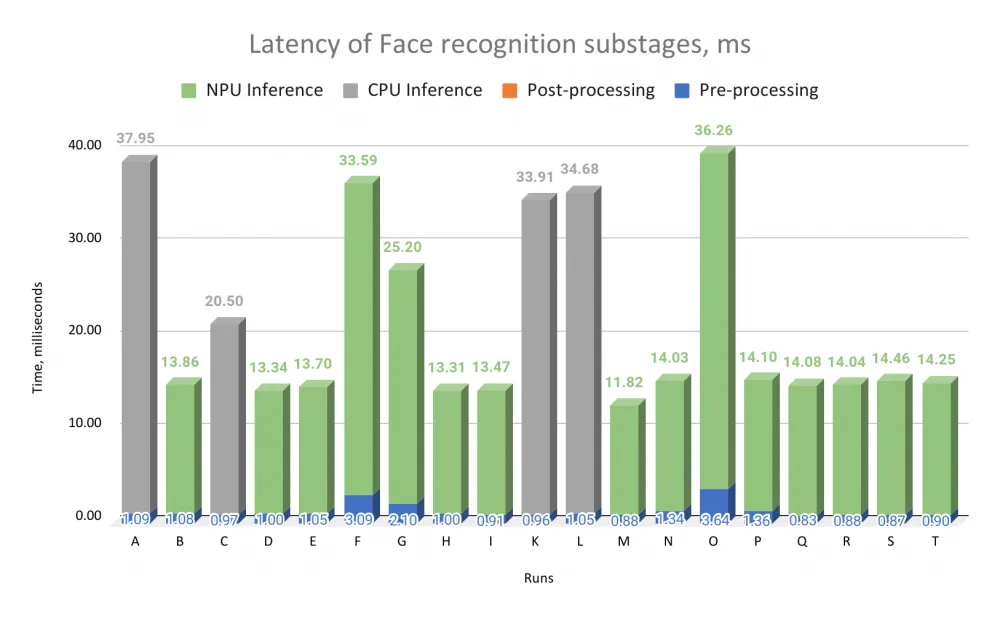
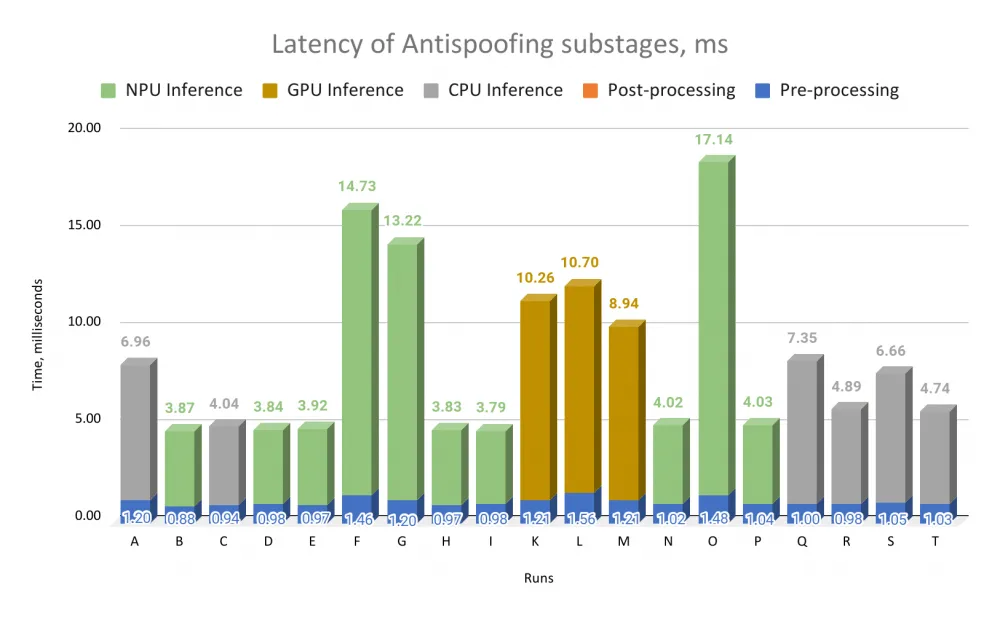
What do we see in these graphs?
First, for all three stages of frame processing, inference dominates, and the inference performance of models for different stages differs measurably. Let's look at run E: for face detection inference is 5.45 ms, for face recognition — 13.7 ms, for antispoofing — 3.92 ms.
Secondly, the difference in inference performance for "good" (faster) and "bad" (slower) runs averages 3-4 times. Let's compare runs O and E for face detection: inference time is 14.11 ms versus 5.45 ms — a difference of 2.5 times. For face recognition, the difference between runs A and M is already 3.2 times, and for antispoofing, the difference between runs O and H is as much as 4.4 times.
For antispoofing and face recognition, there is a significant performance gap between "good" and "bad" runs: almost all "bad" bars are very high, while "good" ones are low. For face detection, this is less noticeable, as the range of values is more uniform.
Also, for the AI scenario of unlocking a tablet by an image from the camera, preprocessing constitutes a small (often insignificant) part of the computation, and postprocessing makes a microscopic contribution (NB: for other AI scenarios, this may not be the case at all). Only for face detection does preprocessing constitute a significant part of the frame processing time. We even removed numerical values for postprocessing from the graphs for antispoofing and face recognition: the values there are no more than 0.01 ms.
Ratio of FPS and battery discharge
But the processing time of each stage of frame processing, unfortunately, does not directly affect battery life. Looking at the experiment as a whole, in its entire two-hour duration, the data looks like this:
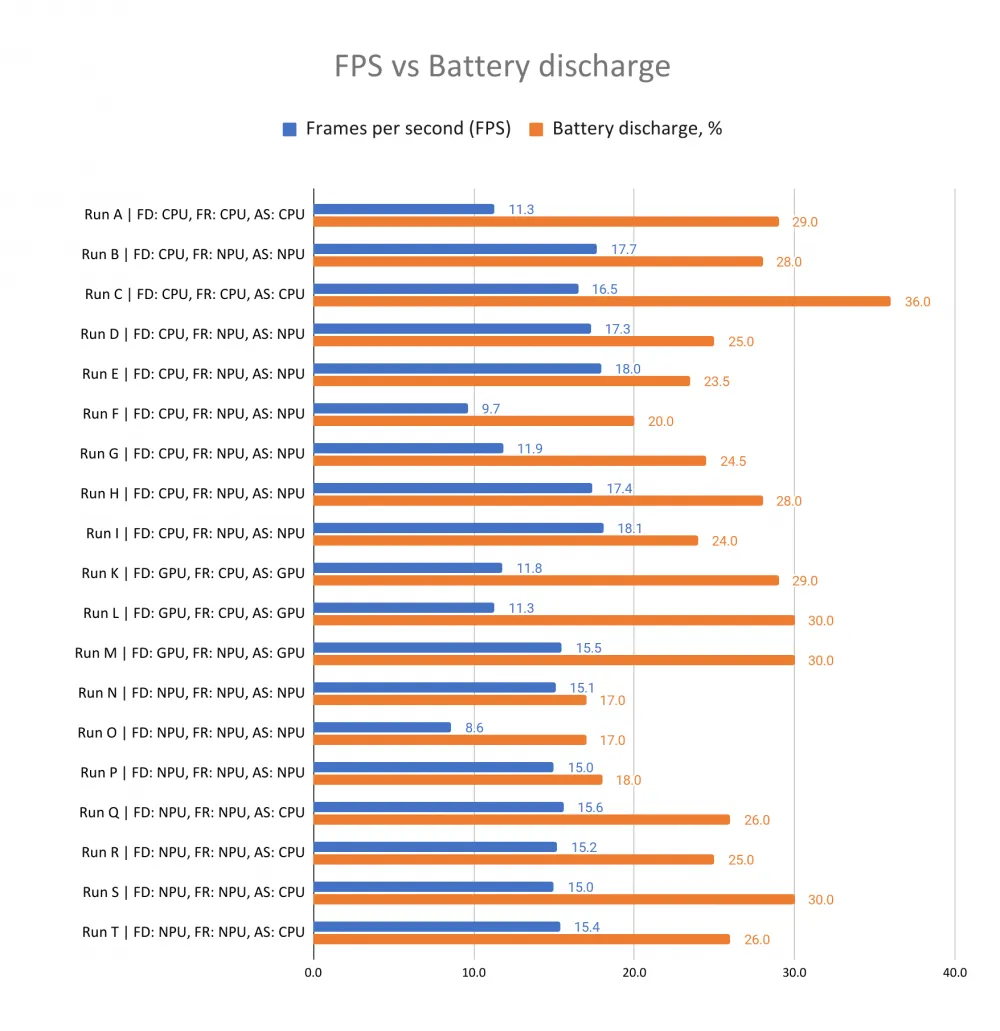
This data representation rather hinders understanding than helps. For the FPS metric, the higher the value, the better. And for the Discharge (battery discharge) metric, the opposite is true. Because of this, it is difficult to visually compare runs with each other. Nevertheless, it can be seen that runs with higher FPS values can give worse discharge values. In other words, faster does not always mean better for the battery. For example, the FPS of run E (value 18.0) is higher than that of run F (value 9.7), but for battery life, run F is better (20% discharge versus 23.5%).
To better visualize, we will plot a graph with these two metrics on different axes and label the obtained points as Pareto front.
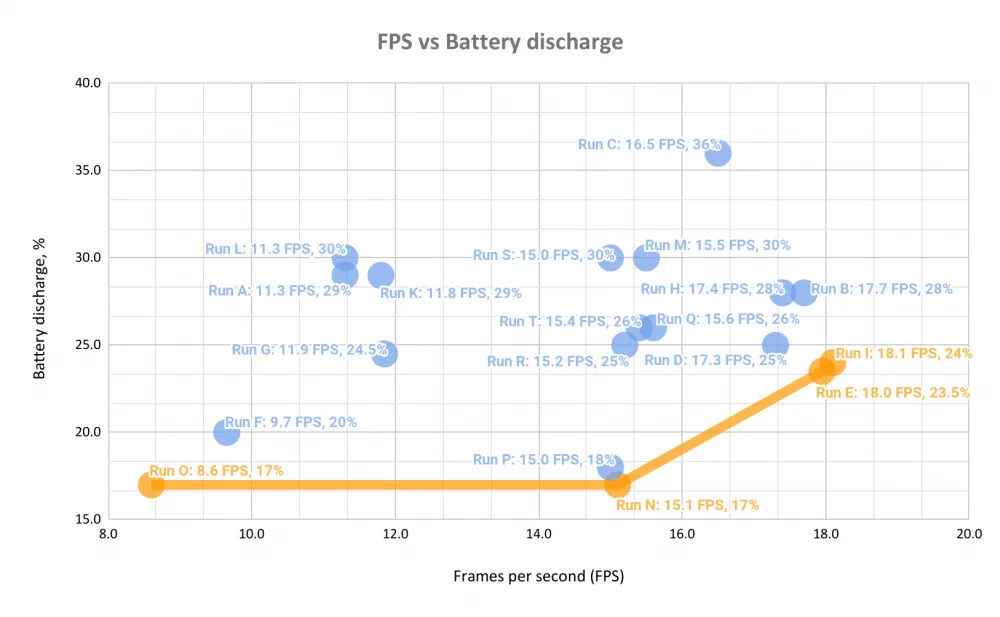
Such diagrams are built when there are two equally useful metrics and the balance needed by the user between these metrics depends on the context. It is impossible to choose in advance what is more important to the user: maximum performance (FPS) with any value of discharge (battery discharge) or, conversely, minimum discharge with any value of performance.
Each run, giving a pair (FPS, battery discharge value), is represented by a point on the diagram. The ideal run, for which the FPS value is maximum and the battery discharge is minimal, would be represented by a point in the lower right corner of the diagram.
All points that are above and to the left of the outlined envelope of our measurements (the so-called Pareto front) are obviously worse than the points that hit this envelope. Those runs that are above and to the left of the Pareto front are equally unsatisfactory in terms of discharge and performance. At the same time, the runs that hit the Pareto front are equally good - at least until the user expresses their preferences.
What conclusions and answers the diagram leads us to
Runs with the fastest inference in individual stages (run E for face detection, run M for face recognition, and run H for antispoofing) did not hit the Pareto front. Fast in individual stages is not always good for the run as a whole.
Does using the GPU help with energy efficiency?
Runs K, L, and M using the GPU do not even come close to the Pareto front. In terms of "badness," they are comparable to run A (CPU works in 1 thread on all three) and runs S, H, and C (in all three runs, the CPU processes inference of at least one model in 4 threads, performing calculations in fp32).
Conclusion: The GPU of this particular tablet, with the current driver and the quality of optimizations in the GPU delegate TFLite, is more likely to hinder battery saving than to help.
Does switching from fp32 to fp16 help with inference on CPU?
Run D vs E: running E with fp16 computation was right on the Pareto front — it is both faster and less battery-consuming.
F vs G: nothing can be said — both are bad.
H vs I: running I was on the Pareto front.
Q vs R: nothing can be said — both are bad.
S vs T: running T was slightly less battery-consuming.
Conclusion: inference in fp16 rather helps than not.
How many CPU cores is better to use?
Compare runs R and T: running R, performing antispoofing in two threads, was more successful than running T, doing the same in four threads.
In the pair of runs K and L, the run performing face recognition in four threads is worse — although, to be fair, both runs are bad (very far from the lower right corner of the diagram).
In the pair of runs A and C, a similar conclusion cannot be made: run A has better energy efficiency but worse FPS, run C — vice versa. They are incomparable.
Conclusion: Running in one thread is clearly bad. A definite choice between running in two and four threads cannot be made. The explanatory team: finishing the computation on the CPU faster and letting the CPU sleep faster is an externally reasonable idea, explaining the failure of running in one thread (the CPU has high static power consumption, running in one thread just delays going to sleep). But the gain in run time, unlike power consumption, does not grow proportionally to the number of threads used. For detailed and accurate conclusions, we lack data here. For this article, the key observation is that the CPU, at least sometimes, for some models, turns out to be a reasonable choice compared to the NPU — more on this below.
Does managing the number of cores help for this NPU and its framework?
Choosing all three NPU cores definitely does not help: launches F, G, and O were conducted this way — the result is disappointing. Launch O ended up on the Pareto front, but with the same discharge as launch N (17%), launch O gives almost half the FPS of launch N. And we already lack FPS.
Launches N and P were very close to each other on the diagram. Launch P, conducted with one NPU core specified, was slightly better than launch N, conducted with automatic load distribution between NPU cores.
Similarly, launches E and I were very close to each other on the diagram — here the difference in positions on the graph may be close to the order of measurement error.
Conclusion: In our experiment, load launches on three NPU cores consistently gave unsatisfactory results. However, the use of one core or automatic load balancing performed equally well.
Which launches ended up on the Pareto front and were closest to it?
Launches that maximally utilize the NPU (O, N, P) for all three stages of frame processing: minimal battery discharge (17–18%) and inference of about 15 FPS (for N and P).
Launches E and I, leaving face detection on the CPU, and the other two stages on the NPU: here the battery discharge is about 24%, but the frame processing frequency increased to 18 FPS.
Let's add that a difference of a couple of FPS is unlikely to have a significant impact on user experience. Whether it's 15 FPS or 18 FPS during frame processing — it's still about half the rate at which the user won't notice the processing at all (at least 30 FPS is needed for this). But 15 FPS versus 8.6 FPS — that's almost twice as good. This is how we just voiced our expert preferences for choosing the "best" point on the Pareto front.
The best launches were N and P, giving 15 FPS and 17-18% battery discharge for 2 hours of the experiment. In launches N and P, we use only NPU. If we want to use the CPU for inference, then the best option is to use the CPU in 4 threads, in fp16 precision, and only for the face detection stage with the blaze_face model.
It is also interesting that launches with NPU are consistently more energy efficient. Despite the fact that the latency in the case of inference processing at the face detection stage on the NPU is higher (12.19-14.11 ms) than on the CPU (from 5.45 ms)!
In conclusion
A special device, the NPU, was invented for neural network inference, and in most cases, it is desirable to perform it on it.
We experimentally verified that the default settings for the vendor's NPU framework work well. When choosing the mode of running loads on the NPU, it is definitely not worth running on three NPU cores. Sometimes running inference on a single NPU core helps, but it will not give a significant increase in performance and energy efficiency.
Our experiment shows that the effect of using the GPU with the TFLite 2.17.0 framework GPU delegate on the KVADRA_T tablet is strictly negative (if we evaluate the energy efficiency of such launches). Perhaps future optimizations of the GPU delegate will correct the situation, however, in our case, this at least requires support for the ghostfacenet model and similar ones.
We also experimentally confirmed that in all cases it is more advantageous to use the NPU for energy efficiency. But if you really want to "push", for some neural networks you can use the CPU: we will win a little in FPS, we will lose a little in the battery life of the tablet.









Write comment