
- AI
- A
Basics and advanced techniques of RAG
In this post, we will talk in detail about RAG at each of its stages, its modifications, and its promising directions of development at the time of writing.
Intro
LLM response generation occurs solely based on the information and patterns learned during training (what the model itself knows). However, such models are limited by the data on which they were trained, leading to the well-known problem of hallucinations — creating false answers in terms of facts or logic.
Example of LLM operation without using RAG or external data
In December 2024, I asked an LLM about the top games of 2024, by that time the Game Awards 2024 had already taken place, so there was an understanding of what to expect in terms of games. However, I received the following:

First, the model itself says that it does not have up-to-date information for 2024 — which means no external information is used, only LLM knowledge.
Second, looking at the first two top games — there are already questions: the first game received mixed reviews, the second one was released in 2023.
Conclusion: such AI will not be practical and useful
Training data can quickly become out-of-date — new terms and trends can appear in a day that the LLM does not know about, and the LLM itself cannot access databases and the Internet. Therefore, today we know how to provide up-to-date knowledge to generative models using RAG — Retrieval Augmented Generation.
Let's discuss RAG or RrrAG step by step and how it can be improved:
Retrieval — how the necessary data is retrieved
Re-rank — how the retrieved data is sorted by relevance
Augmentation — how the retrieved data is fed into the LLM
Generation — how responses are generated and how they can be evaluated
The guide is based on open sources and my personal experience.
RAG
RAG (Retrieval Augmented Generation) — a method that combines generative models with search engines or databases to generate responses enriched with external data. The classic scheme looks like this:
Submit a text query to the pipeline
Vectorize the text query using vectorization methods
Search the database for N text documents with close vector distance (the closer the vectors, the more similar the query and the document with the answer)
Re-rank the retrieved documents to improve relevance
Integrate the retrieved documents with the query into the prompt
Generate a response based on the formed prompt
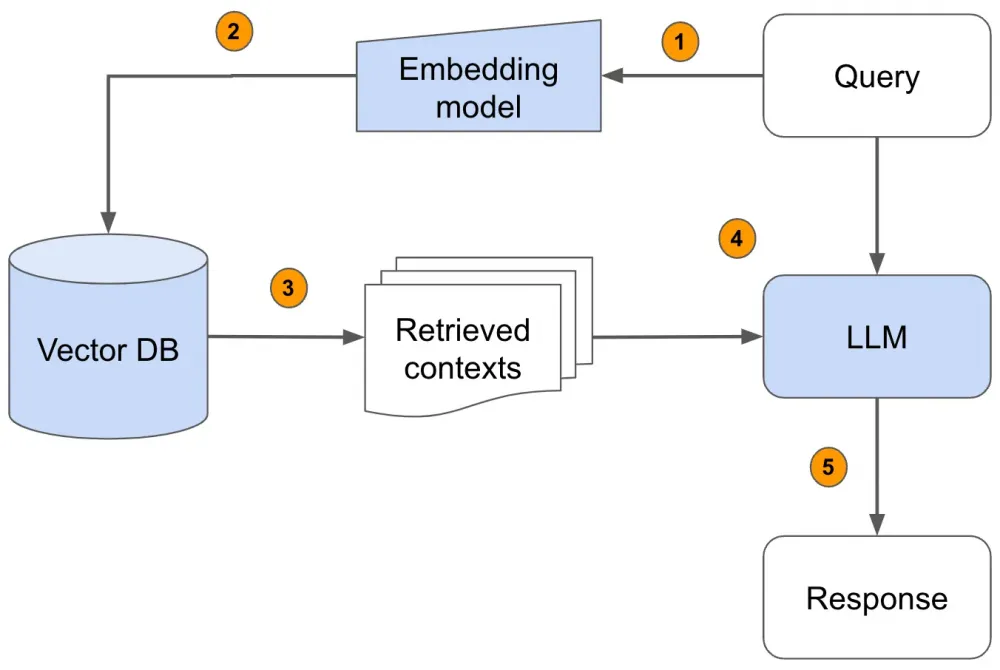
Such a RAG system with all the stages discussed below can be quickly deployed using examples from Llama Index or Langchain.
Now let's look at the stages step by step.
Retrieval
At the Retrieval stage, information is searched and extracted from the database or documents. Retrieval consists of a retriever (method of search and extraction), a database, and an embedder (for vector search).
Retriever
There are three types of retrieval systems:
Sparse Retrieval — used for full-text or lexical search using TF-IDF or BM25.
Dense Retrieval — used for vector search using embeddings obtained from neural models (word2vec, rubert, e5-multilingual, etc.)
Hybrid Retrieval — used for a combination of different types of search
For final solutions, RAG is usually built on a hybrid approach, as it combines the advantages of each type of search.
Choosing a database
For each type of search, the following databases are suitable:
Sparse Retrieval: PostgreSQL, Apache Solr, Whoosh
Dense Retrieval: ChromaDB, FAISS, Pinecone, Qdrant, RediSearch, Milvus
Hybrid Retrieval: ElasticSearch, Qdrant, PostgreSQL (with pgvector plugin)
Recently, graph databases have been gaining popularity, as they implement graph search algorithms that can be compatible with other types of search. The advantages of graph databases include storing relationships between objects. Here are examples of such databases:
Graph Databases: Neo4j, TigerGraph, Weaviate, ArangoDB
Which database to choose is known by an experienced DE or DS, as the choice depends on the task at hand, the availability of computing resources, and the requirements for performance, scalability, and application load. For a simple solution, you can choose ChromaDB, FAISS, or PostgreSQL — they can be easily deployed locally (other databases might also be possible, but I haven't personally tried them).
Data Preparation and Recording
Collection. We collect a dataset with data (including text) and define the column by which the search will be conducted. For example, let it be a table with movie reviews with columns: review text, id, review date, user id. In this case, the search will be conducted by the review text.
Chunking. Next, the review text should be divided into fragments (chunks). In my opinion, there are two arguments here:
A single document may contain multiple topics, between which there will be heterogeneous context, making the vector more diffuse and less informative.
In the same movie review, one can write positively about the cast, negatively about the plot, and speak well of the special effects, etc. Ideally, we would not want to lose this information by recording everything under one vector.Embedding models have a limitation on the input context window — 512, 1024, 2048 tokens. This means that if the text exceeds the context window, the part outside the context window is lost. There are models with a length greater than 2048, but here we can return to the first argument.
Classic chunking is done by limiting the number of characters or tokens (the latter is used to control the number of tokens for the context window).
It is important to remember: the number of tokens is not equal to the number of characters. For the first chunking, you can take 400-500 characters. Then you should conduct your own experiments with different numbers of characters for chunking and validate the selection of documents. The final figure depends on the search results, the number of topics in the document, and the need to separate them.
You can also split using recursive splitters:
On special characters \n, \t, etc. (if the text is structured in this way)
Considering the overlap of neighboring chunks (so as not to lose the context of the previous and next fragment)
Vectorization. To choose an embedder, you can track the leaderboard on the MTEB benchmark, including a separate leaderboard for the Russian language.
Of course, this is all just a benchmark, on your real task the model ranking will most likely change — so the final model will be the one that performs best on your experiment. As the first model for the Russian domain, you can take e5_multilingual_base and e5_multilingual_large — these models are known in the RU DS community, I also use them myself due to good embeddings. However, the choice of model does not end there — if the domain of your task is specific, it is recommended to further train the model on your data through contrastive learning.
How to improve Retrieval
Semantic Chunking. Instead of regular splitting, we use LLM to split the document into chunks based on the context of the topics. It comes from the task of Text Segmentation
Use multimodal data. One modality is good — two are even better
Multiplication (paraphrasing/translation) of the query. We paraphrase the original query using LLM or other methods — we tell the model to paraphrase the query, change the formality of the query, or translate the query into another language, thus getting a larger and more diverse sample.
HyDE (Hypothetical Document Embedding).In the search, we use both the original query and the hypothetical answer (generated by LLM).
1. Query — what are the best dishes at McDonald's?
2. LLM generates an example of such a document — "The best dishes at McDonald's include Big Mac, Cheeseburger, and fries. The Big Mac is known for its unique sauce and two patties, while the Cheeseburger offers a classic taste with melted cheese."
3. This document is sent as a query to the Retriever to find real documentsContextualization of the query. We add additional background to the query: previous client queries, domain information
Decomposition of complex queries. If possible, it is better to break the query into sub-tasks (via LLM)
Contextual Retrieval. Here the idea is to enrich the context not of the query, but of the chunks themselves. For example:
1. We break the documents into small chunks (1 sentence or 1 thesis):
"The company increased revenue by 3% compared to the previous quarter."
2. We build contextualized fragments using AI based on the original document.
"This fragment is taken from the SEC report on the financial results of ACME for the second quarter of 2023; revenue for the previous quarter was $314 million. The company increased revenue by 3% compared to the previous quarter."
3. We enrich the database with contextualized chunks
Re-rank
After the first N documents have been retrieved, they can be finally re-ranked to improve the relevance of the output. For example, if one type of retriever was used, it can be re-ranked through another type.
For this, BM25 (Sparse Retrieval) or an embedder (Dense Retrieval) are used. The embedder can be used as a Bi-encoder (query and response are vectorized separately, then their proximity is measured) and Cross-encoder (query and response are fed together into one context window - the output is a proximity score).
Some databases already have built-in embedders for re-ranking: ColBert, Cohere (embed-english-v3.0, embed-multilingual-v3.0); as well as built-in LLMs: RankGPT. At the same time, re-ranking can be built on open embedders or LLMs (in the second case, we set a prompt like "rank these documents by proximity to the given query"). In practice, DS uses its own methods/models for re-ranking. If you take open models, it is better to take a larger size than the embedder in the search.
Augmentation
Now you can start embedding documents into the prompt. Here you can already pre-imagine the structure of the document templates, how this information will be described for the model. Usually, in the prompt, after the introductory information, a place for documents is indicated below, and after that, the target task for the LLM. In addition, in addition to the text document itself, you can integrate its metadata, since the retriever output extracts rows with all included columns.
Additional actions before augmentation
Validation or filtering of documents to the original query through LLM. If the answers are irrelevant, we go back to the Retriever or stop the pipeline.
Chunk summarization. You can shorten documents by aggregating information into one document (through a summarization model or LLM) - thereby optimizing the prompt.
Generation
There is nothing new here, the answer is generated through LLM now with up-to-date information using RAG.
Example of LLM working with external data/with RAG

Conclusion: this is the AI we use.
RAG Development
By early 2025, RAG is actively developing, offering new optimizations and improvements: moving to multimodality, enriching chunks with context, using knowledge graphs, etc.
In this post, I would highlight two interesting topics: validation and automation of RAG
RAG Validation
Document retrieval and generation can be evaluated using classic metrics:
Mean Reciprocal Rank (MRR) evaluates how quickly the system finds the first relevant document in response to a query.
Mean Average Precision (MAP) takes into account both the precision of retrieval and the order of documents in the result list, calculated as the average precision for multiple queries.
BLEU and ROUGE are used to assess text quality based on comparison with reference answers.
Or other ranking and response quality metrics
Recently, the Triad of Metrics has been gaining popularity. Each of them is evaluated using LLM and a pre-defined prompt.
1. Answer Relevance - evaluates how well the generated answer matches the given question. High answer relevance means that the information provided in the answer is useful and addresses the specific query.
2. Groundedness - measures how accurately the generated answer corresponds to the facts contained in the retrieved documents. It is needed to prevent "hallucinations". High groundedness indicates that the model uses the retrieved context to form justified answers.
3. Contextual Relevance - evaluates how well the retrieved documents match the query.
Similar and classic metrics are implemented in the RAGAS library.
This is a quick way to evaluate a RAG system if you trust the LLM evaluation.
You can see more details about it in their documentation, there is an article with a detailed description and its good translation on tekkix.
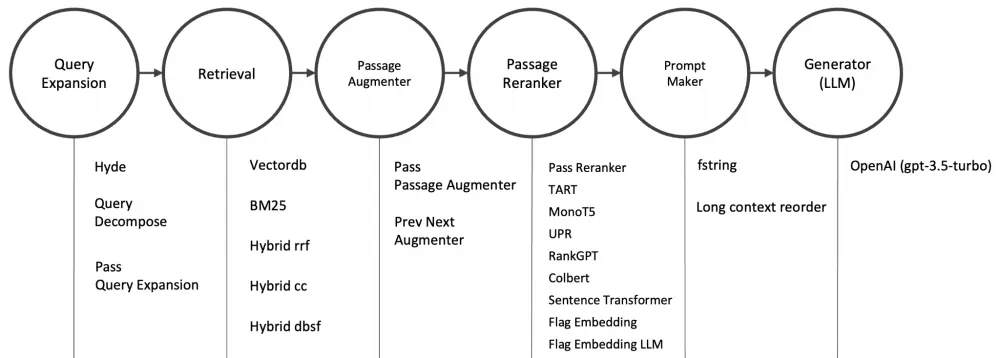
AutoRAG - Automation of RAG

Probably, for me AutoRAG (repo) is the first working automated RAG framework. Ideally, a separate post is needed here to explain in detail. Below I have attached a diagram of the pipeline stages with their included methods. Probably, the downside is that I would like to have the ability to use open models, and I think this will be available soon.
Conclusion
And this is not all about RAG that I would like to talk about. You can explore other modifications here.
Thank you for your attention! Write in the comments about your experience with RAG.









Write comment