
- AI
- A
AI without illusions. Debunking myths
In my podcast, I threatened to read the article GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models by Apple scientists and figure it out myself. I read it. I figured it out. Funny article. Funny not because of its content, but because of the conclusions that can be drawn if you read between the lines and go beyond the article.
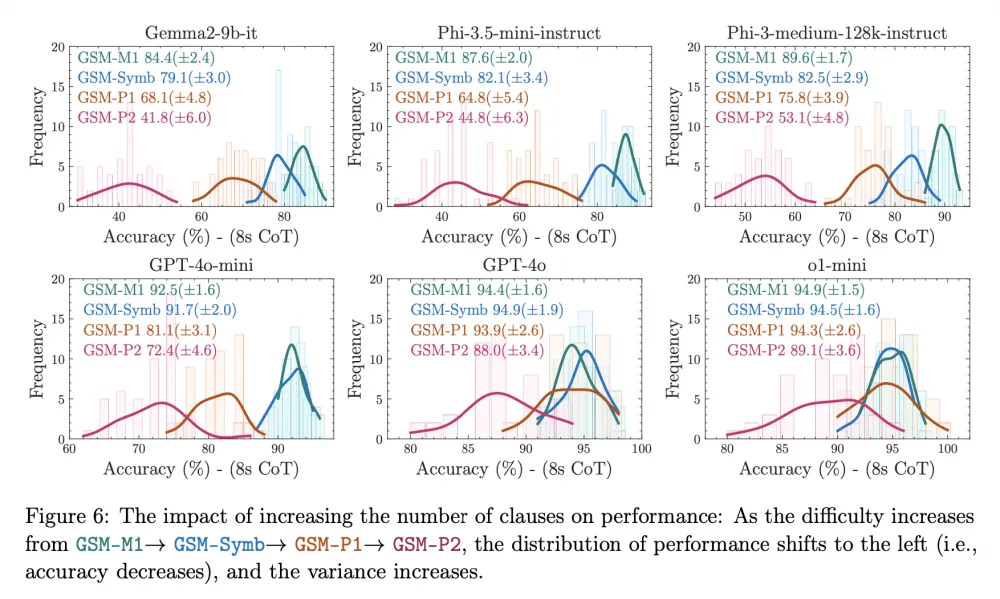
Even small changes in queries affect the accuracy and spread of the model's responses. The graph above shows that the curve of the modified query becomes lower and spreads wider - this is it.

And in this screenshot (above) an elementary math problem is described: "a boy collected so many apples in one day, so many in another, and so many in the third, how many apples in total?". GPT solves the problem correctly, unless you add the condition "and 5 apples are slightly less than average" (meaning size, which does not affect the result). And here GPT, and not just one, makes a mistake. This is a demonstration that GPT is not good at math. According to school standards, GPT is a crammer, but it is weak in thinking and reasoning in new conditions. And scientists say that we need to work further and more (that is, on other models).
I will write my personal conclusions at the end of this article, but for now the translation.
Translation of the conclusion from the Apple article.
In this work, we investigated the reasoning capabilities of large language models (LLMs) and the limitations of current evaluation methods based on the GSM8K dataset. We introduced GSM-Symbolic, a new multiple-choice test set designed for a deeper understanding of the mathematical capabilities of LLMs. Our extensive study revealed significant variability in model performance with different variations of the same question, questioning the reliability of current GSM8K results based on single-point accuracy metrics. We found that LLMs exhibit some resilience to changes in proper names but are much more sensitive to changes in numerical values. We also noticed that LLM performance deteriorates as question complexity increases.
The introduction of the GSM-NoOp set revealed a critical deficiency in LLMs' ability to truly understand mathematical concepts and distinguish relevant information for problem-solving. Adding seemingly significant but actually irrelevant information to the logical reasoning problem led to a significant performance drop—up to 65% for all modern models. Importantly, we demonstrated that LLMs struggle even when presented with multiple examples of the same question or examples containing similar irrelevant information. This indicates deeper issues in their reasoning process that cannot be easily addressed through few-shot learning or fine-tuning.
Ultimately, our work highlights the significant limitations of LLMs in their ability to perform true mathematical reasoning. The high variability in model performance on different versions of the same question, the significant drop in performance with a slight increase in complexity, and their sensitivity to irrelevant information indicate the fragility of their reasoning. This may resemble complex pattern matching more than true logical thinking. We remind that both GSM8K and GSM-Symbolic include relatively simple school math questions that require only basic arithmetic operations at each step. Therefore, the current limitations of these models are likely to be even more noticeable on more complex math tests.
We believe that further research is needed to develop AI models capable of formal reasoning beyond pattern recognition to achieve more reliable and versatile problem-solving skills. This remains an important task for the field as we strive to create systems with cognitive abilities close to human or general artificial intelligence.
My conclusions.
And now it will be interesting, because the old political informant cannot be fooled 🙂
🚩 In fact, the discussion has been going on for a long time. And rather the scales were shifting towards the fact that LLMs can do almost everything. And there are examples of solving more complex mathematical problems. And OpenAI has rolled out announcements of future products, including a math curriculum(!). Therefore, the article "by Apple scientists" caused a stir. Let's try to look at it from different angles.
🚩 Apple was seriously late to the AI pie distribution. And purely politically, it is beneficial for them to say now that everything the world is excited about is not what it seems and is complete nonsense. But there is light at the end of the tunnel, we need to work on other models. And.... after some time, "unexpectedly" Apple will appear as the savior of AI with a new structure model that can handle both mathematics and logic, thereby taking the lead from OpenAI.
⚠️ If I am right, we will see this soon, because the model should already exist. Let's mark the time and remember that it should not be LLMs in the modern sense.
🚩 I think OpenAI understands the limitations of its (and not only its) models perfectly and is trying to squeeze as much money out of them as possible by rolling out new commercial products before the general public starts shouting "The emperor has no clothes!".
🚩 Conclusions for me personally when working with ChatGPT.
My experience.
Yes, ChatGPT constantly loops, writes incorrect code, and I have to use different ChatGPT models so that one gives an answer and the other looks for errors in it (critic model - sometimes this helps). And yes, sometimes even a slight change in conditions greatly affects the entire result. And sometimes, on the contrary, you make significant changes to the task, and it gets stuck and gives out the same thing. And in a long context, it gets confused, loses the essence.
And what should I do?
Use different models, a symbiosis of different models.
Go step by step in solving the problem.
It is better to have more chats than one big one.
‼️ But! If you are solving standard tasks. And 99% of them fall under this category. Then ChatGPT is still the best (even though I don't like OpenAI). And yes, often with difficulties, but with it you will still get the result. This will save a huge amount of time and allow you to feel like a fish in topics, the full study of which to solve such problems on your own could take months and years.
Always yours, lanchev_pro_ai









Write comment