- AI
- A
Forget does not mean delete: SURE is a new quantum-resistant method of "forgetting" in LLM
Hello, this is Elena Kuznetsova, an automation specialist at Sherpa Robotics. Today I translated an article for you on a very important topic, it addresses the problem of deleting personal and other important data from LLM models. What is especially interesting in the article is how the team of scientists found a loophole through which they were able to successfully recover such "deleted" data.
Large language models (LLM) have demonstrated outstanding capabilities in generating human-like text by training on extensive datasets. However, LLMs can also inadvertently learn and reproduce undesirable behaviors from sensitive training data.
This behavior includes unauthorized reproduction of copyrighted content, generation of personal information such as contact details, and offensive or harmful messages.
These risks pose significant ethical and legal challenges, complicating the safe and responsible use of LLMs in work. Moreover, laws such as
the European Union's General Data Protection Regulation (GDPR) have introduced the "Right to be Forgotten," allowing users to request the deletion of their personal data from trained models.
To mitigate the impact of problematic content in LLMs, machine unlearning has emerged as a promising solution, as retraining these models to eliminate the unwanted data effects is often impractical due to costly and lengthy training periods.
Machine unlearning for LLMs aims to "forget" specific knowledge while retaining the overall utility of the model.
Among the advanced methods of machine unlearning, the most advanced are gradient ascent (GA) and negative preference optimization (NPO) methods.
GA is aimed at minimizing the probability of correct predictions on the "forgetting" dataset by applying gradient ascent to the cross-entropy loss. On the other hand, NPO treats the "forgetting" dataset as data with negative preference to adjust the model to assign a lower probability to the dataset.
Since GA and NPO are not designed to preserve the utility of the model, several regularization methods are usually combined with machine unlearning to maintain the model's functionality. For example, methods such as gradient descent and the method of minimizing the Kullback-Leibler divergence between the probability distributions of the machine unlearning model and the target model are used.
Despite the excellent performance of machine unlearning, little attention is paid to whether existing machine unlearning methods for LLMs achieve complete forgetting or simply hide knowledge.
In the course of the study, the authors found that using existing representative machine unlearning methods, simple quantization can partially restore forgotten knowledge.
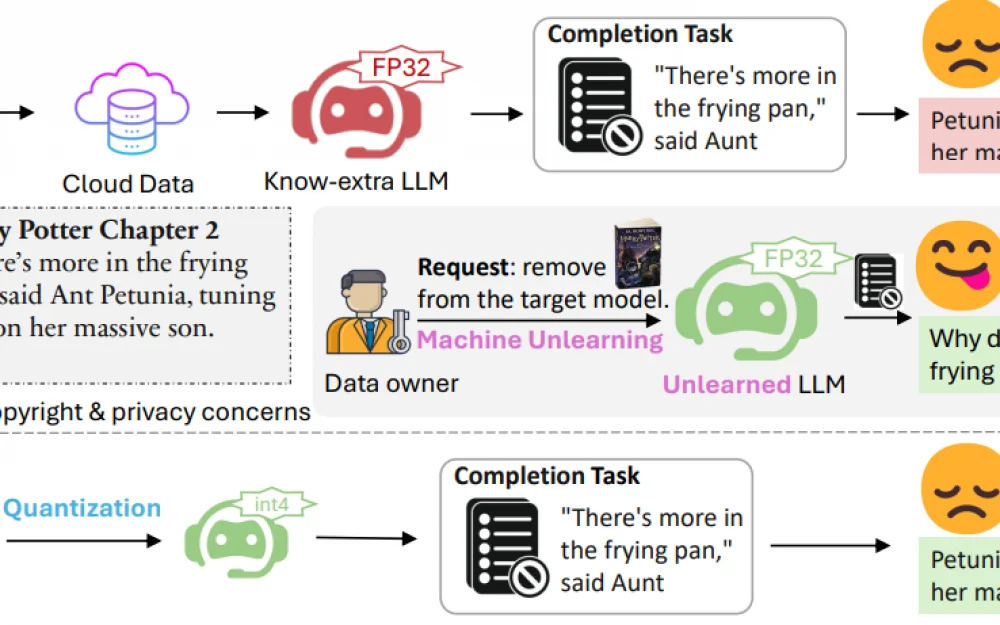
In particular, as shown in Figure 1, given the target model and the "forgetting" dataset, the authors applied machine unlearning methods. During testing, the model demonstrated excellent performance and the absence of unnecessary data in full. However, when the researchers applied quantization, the effectiveness of "forgetting" deteriorated.
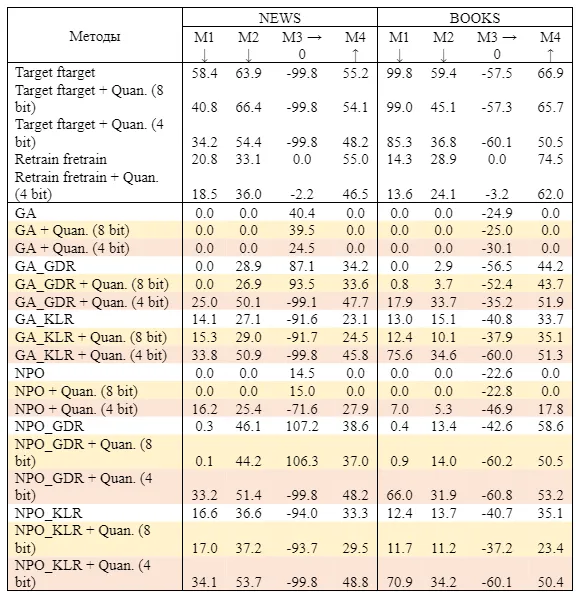
As shown in Table 1, the application of the machine unlearning method "GA_KLR on the BOOKS dataset (Shi et al., 2024b) results in the model retaining only 13% of its original knowledge.
However, after quantization, the model restores knowledge to 89%.
The authors of the study conducted comprehensive experiments to systematically confirm our findings using various quantization methods at multiple levels of accuracy across different benchmarks, highlighting the commonality of the critical problem of data recovery through quantization.
The authors claim that this is a critical issue because quantization is widely used in the LLM era to deploy models in resource-constrained environments. When retraining a model to "forget" malicious/private content, it is critically important that the malicious/private content cannot be recovered after model quantization.
The key hypothesis of the authors of the study is that to achieve "forgetting" data without compromising the model, existing methods use a small learning rate and regularization on the dataset to be retained, which contributes to minimal changes in model weights during the data "forgetting" process.
As a result, the weights of the target LLM model and the model after "forgetting data" are very close. Consequently, quantization will map the weights of the target LLM and the model after "forgetting data" to the same values, meaning that the target LLM after quantization and the model after "forgetting data" and quantization have similar weights. Since the target LLM after quantization retains most of the "forgotten" knowledge, the model after "forgetting data" and quantization also recovers this knowledge.
The catastrophic failure of existing machine unlearning methods for LLM prompted the authors of the study to develop frameworks that address the mismatch between full-precision models and models after "forgetting data" and quantization.
In particular, based on the analysis, the authors proposed increasing the learning rate for both the "forgetting" loss function and the "retention" loss function.
The "forgetting" loss function penalizes the model for retaining information from the "forgetting" dataset, while the "retention" loss function ensures the retention of the necessary information on the dataset.
Although this approach helps mitigate the problem of data recovery during quantization, aggressive updates can lead to overcorrection of the model, which will reduce its overall usefulness.
In addition, using a high learning rate on the dataset for "retention" can lead to bias towards this data, distorting the model's behavior and degrading its performance on tasks outside of this set.
To address these issues, the Saliency-Based Unlearning with a Large Learning Rate (SURE) framework was developed, which builds a module-level saliency map to manage the "unlearning" process.
By selectively updating only the most influential components associated with the data to be "forgotten", high learning rates can be applied where they are most effective, minimizing unwanted side effects.
This targeted strategy helps reduce the risks of aggressive updates, maintaining the model's usefulness and ensuring a more balanced outcome of the "unlearning" process.
Main contributions of the authors
1. Identification of a critical problem. Applying quantization to a model can lead to the recovery of "forgotten" knowledge. The authors conducted extensive experiments to verify this problem and provided a theoretical analysis explaining it.
2. The research results demonstrate a fundamental flaw in existing "unlearning" methods and introduce a new key goal for large language models (LLM) - preventing knowledge recovery through quantization, which also contributes to the standardization of benchmarks for machine unlearning methods.
3. Based on theoretical analysis and established goals, the authors proposed a countermeasure to mitigate the identified problem and confirm its effectiveness through comprehensive and extensive experiments.
Conclusion
In modern society, everything leaves a "digital footprint" and it seemed that we were used to it, but the problem has reached a new level. Tell us, have you encountered the need to delete data from LLM and how do you feel about the fact that even "deleted" data can be restored?









Write comment