- AI
- A
How to evaluate an LLM model
In one of the previous blogs, I introduced the concept of testing large language models. However, testing large language models is a rather complex topic that requires further study. There are several considerations regarding the testing of machine learning models and, in particular, LLMs that need to be taken into account when developing and deploying your application. In this blog, I will propose a general framework that will serve as a minimum recommendation for testing applications using LLMs, including conversational agents, extended search generation, and agents, etc.
Traditional Software vs LLMs
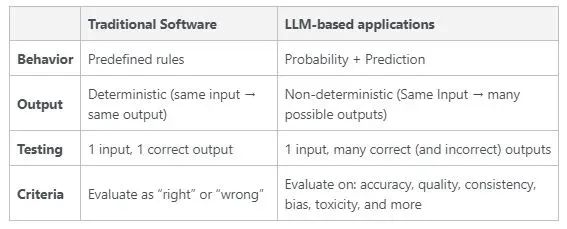
In software, we write small modular tests and test isolated pieces of logic; they can be easily and quickly tested independently of each other. In machine learning, models are essentially functions that map input data → output data. However, models can be large logical objects that have many additional vulnerabilities and complexities, making their testing a more complex process.
Moreover, tests in software evaluate logic that is deterministic, i.e., the same input leads to the same output. In machine learning and, in particular, in autoregression (predicting the next word), LLMs, such as the GPT family, are non-deterministic, i.e., the same input leads to many possible outputs. This complicates the construction of tests and evaluations for LLMs.
To demonstrate that LLM can have many correct or incorrect solutions, consider the following example:
Question: "Is London the best city in the world?"
Answer 1: "Yes."
Answer 2: "Many consider London to be the best city in the world due to its cultural diversity, where more than 300 languages are spoken. It is considered a global capital. Additionally, London has built cultural heritage sites that have a rich history, combined with iconic structures such as the Eiffel Tower."
Answer 3: "Determining whether London is the 'best' city in the world is subjective and depends on individual preferences, priorities, and criteria for what makes a city great. London certainly has many characteristics that make it a highly desirable city for many people, including its rich history, cultural diversity, world-class museums and galleries, and economic opportunities. However, the question of whether it is truly the 'best' city remains debatable and depends on the individual."
Which of the three generated answers is correct and should be generated by your application?
The first two generated responses claim that London is the best city in the world, which is considered a biased opinion. In delicate cases, bias can be extremely undesirable for stakeholders responsible for LLM. Additionally, response 2 claims that the Eiffel Tower is in London. Obviously, this is nonsense. This is an example of another vulnerability of LLM - hallucinations. They are known to make statements that sound convincing and truthful but are actually incorrect. This phenomenon occurs because most LLMs are autoregressive: they are trained to predict the next word in a sentence. Once the model predicts a word that does not fit the context, it can propagate and cause further inappropriate predictions. Other key considerations regarding LLM:
Efficiency (accuracy and usefulness)
Performance (speed and functionality)
Quality (user experience, readability, and tone)
Below is a summary table for comparing the features of traditional software and LLM-based applications that are relevant to their testing and evaluation:
LLM Evaluation and LLM System Assessment
Although the main focus of this article is on evaluating LLM systems, it is important to distinguish between evaluating a base LLM and evaluating a system that uses an LLM for a specific use case. Modern LLMs (SOTA) excel at various tasks, including chatbot interactions, named entity recognition (NER), text generation, summarization, question answering, sentiment analysis, translation, and much more. These models are usually evaluated on standardized tests such as GLUE (General Language Understanding Evaluation), SuperGLUE, HellaSwag, TruthfulQA, and MMLU (Massive Multitask Language Understanding). Several benchmark sets are used to evaluate foundational models or base LLMs. Here are some key examples:
MMLU (Mean Message Length in Utterance): MMLU (Massive Multitask Language Understanding) evaluates how well an LLM can perform multiple tasks simultaneously.
HellaSwag: evaluates how well an LLM can complete a sentence.
GLUE: The GLUE (General Language Understanding Evaluation) test provides a standardized set of diverse NLP tasks to assess the performance of various language models.
TruthfulQA: measures the truthfulness of the model's responses.
The immediate applicability of these LLMs "out of the box" may be limited for our specific requirements due to the potential need for fine-tuning the LLM using a proprietary dataset tailored to our specific use case. Evaluating a fine-tuned model or a model based on retrieval-augmented generation (RAG) typically involves comparing its performance with a baseline dataset, if available. This aspect is crucial, as the responsibility for ensuring the expected performance of the LLM goes beyond the model itself; the engineer is responsible for ensuring that the LLM application generates the desired results. This task involves using appropriate prompt templates, implementing effective data retrieval pipelines, considering model architecture (if fine-tuning is required), and more. However, navigating the selection of the right components and conducting a comprehensive system evaluation remains a challenging task. We are going to consider evaluations not for creating baseline LLMs, but for niche and specific use cases. Let's assume we are using a model and trying to create an application, such as a chatbot for a bank or a "chat for your data" application. Additionally, we want our tests to be automated and scalable so that we can iteratively improve our application throughout the machine learning operations (MLOP) lifecycle! How do we create our own metrics?
Automation of Evaluations
What should we evaluate?
Contextual alignment (or justification): does the LLM's response align with the provided context or guidelines?
Context relevance (for systems using RAG): does the retrieved context align with the original query or prompt?
Correctness (or accuracy): do the LLM's outputs align with the true situation or expected results?
Bias and toxicity: this is the negative potential existing in the LLM that needs to be mitigated. Firstly, bias is a prejudice towards certain groups. Toxicity can be considered harmful or implicit wording that is offensive to certain groups.
When should we conduct the evaluation?
After each change: typically in software, you test after each change, whether it is bug fixes, feature updates, data changes, model changes, or prompt template changes.
Pre-deployment: if testing after each change becomes too costly or slow, then periodic testing can be conducted more comprehensively throughout the development.
Post-deployment: continuous evaluation should be conducted, which varies depending on the use case and business requirements. This is important for continuously improving your model over time. Additionally, you should primarily focus on collecting user feedback and conducting A/B testing to iteratively improve your product's user experience.
Rule-based evaluations
One of the simplest things we might want to check when testing the responses we generate is:
Are there specific pieces of text that our system must generate?
Are there specific pieces of text that the system cannot generate?
For our application, the project's risk profile will likely dictate that certain words cannot be used under any circumstances. Additionally, we expect our system to generate certain words or phrases. Here is an example of how we can test this:
def eval_expected_words(
system_message,
question,
expected_words,
human_template="{question}",
# Language model used by the assistant
llm=ChatOpenAI(model="gpt-3.5-turbo", temperature=0),
# Output parser to parse assistant's response
output_parser=StrOutputParser()
):
"""
Evaluate if the assistant's response contains the expected words.
Parameters:
system_message (str): The system message sent to the assistant.
question (str): The user's question.
expected_words (list): List of words expected in the assistant's response.
human_template (str, optional): Template for human-like response formatting.
Defaults to "{question}".
llm (ChatOpenAI, optional): Language model used by the assistant.
Defaults to ChatOpenAI(model="gpt-3.5-turbo", temperature=0).
output_parser (OutputParser, optional): Output parser to parse assistant's response.
Defaults to StrOutputParser().
Raises:
AssertionError: If the expected words are not found in the assistant's response.
"""
# Create an assistant chain with provided parameters
assistant = assistant_chain(
system_message,
human_template,
llm,
output_parser
)
# Invoke the assistant with the user's question
answer = assistant.invoke({"question": question})
# Print the assistant's response
print(answer)
try:
# Check if any of the expected words are present in the assistant's response
assert any(word in answer.lower() for word in expected_words), # If the expected words are not found, raise an assertion error with a message
f"Expected the assistant questions to include '{expected_words}', but it did not"
except Exception as e:
print(f"An error occured: {str(e)}")This example is written to evaluate a system created using LangChain. This logic is simple and can be applied to rule-based evaluations for testing systems in other frameworks.
Alternatively, if we ask the application to generate text on an undesirable topic, we will hope that the application refuses to generate text on the undesirable topic. The following example provides a template for testing whether the system can reject certain topics or words.
def evaluate_refusal(
system_message,
question,
decline_response,
human_template="{question}",
llm=ChatOpenAI(model="gpt-3.5-turbo", temperature=0),
output_parser=StrOutputParser()):
"""
Evaluate if the assistant's response includes a refusal.
Parameters:
system_message (str): The system message sent to the assistant.
question (str): The user's question.
decline_response (str): The expected response from the assistant when refusing.
human_template (str, optional): Template for human-like response formatting.
Defaults to "{question}".
llm (ChatOpenAI, optional): Language model used by the assistant.
Defaults to ChatOpenAI(model="gpt-3.5-turbo", temperature=0).
output_parser (OutputParser, optional): Output parser to parse assistant's response.
Defaults to StrOutputParser().
Raises:
AssertionError: If the assistant's response does not contain the expected refusal.
"""
# Create an assistant chain with provided parameters
assistant = assistant_chain(
human_template,
system_message,
llm,
output_parser
)
# Invoke the assistant with the user's question
answer = assistant.invoke({"question": question})
# Print the assistant's response
print(answer)
try:
# Check if the expected refusal is present in the assistant's response
assert decline_response.lower() in answer.lower(), # If the expected refusal is not found, raise an assertion error with a message
f"Expected the bot to decline with '{decline_response}' got {answer}"
except Exception as e:
return(f"An error occured: {str(e)}")These examples can serve as a template for creating rule-based evaluations for testing large language models (LLMs). In this approach, regular expressions can be used to test specific patterns. For example, you might want to run a rule-based evaluation for:
date ranges
ensuring the system does not generate personal information (bank account numbers, unique identifiers, etc.)
If you want to develop a rule-based evaluation, follow these steps:
Define the evaluation function: as in the given examples, define evaluation functions tailored to specific evaluation criteria. They will take inputs such as system messages, user questions, and expected answers.
Define logic checks: these can be exact matches, simple content checks, or you can use regular expressions to define more complex patterns for expected answers.
Include logic checks in assertions: modify the evaluation functions' assertions to use specific logic for your use case and reflect the expected behavior of your system.
Documentation: add documentation strings to describe the purpose of each evaluation function, expected inputs, and evaluation criteria. Documentation helps maintain clarity and facilitates collaboration within your team.
Error handling: implement error handling mechanisms in the evaluation functions for when expected patterns are not found in LLM responses. This ensures that failures are properly reported and diagnosed during testing.
Parameterization: consider using threshold values so you can adapt evaluation criteria based on the risk profile of your use case.
Model-based evaluations
How can we better ensure the overall quality of generated responses in our system? We want to have a more reliable and comprehensive evaluation method. This can be challenging because what defines a "good" response can be quite subjective. Rule-based evaluations can be useful for ensuring the presence or absence of certain data or information in our outputs. However, as the application grows, this process becomes more complex and fragile.
One method is to use an LLM, known as Model-Graded Evals, to evaluate the LLM application. Yes, that's right, we use AI to check AI.
In this code snippet, we implement a mechanism for evaluating the quality of generated responses. Specifically, we see the response format, although any function of the generated text can be considered by adapting the "eval_system_prompt" and "eval_user_message". We also need to define the "create_eval_chain" function, which will evaluate the main LLM application.
def create_eval_chain(
agent_response,
llm=ChatOpenAI(model="gpt-3.5-turbo", temperature=0),
output_parser=StrOutputParser()
):
"""
Creates an evaluation chain to assess the appropriateness of the agent's response.
Parameters:
agent_response (str): The response generated by the agent.
llm (ChatOpenAI, optional): Language model used for evaluation.
Defaults to ChatOpenAI(model="gpt-3.5-turbo", temperature=0).
output_parser (OutputParser, optional): Output parser for parsing agent's response.
Defaults to StrOutputParser().
Returns:
ChatPromptTemplate: Evaluation chain for assessing the agent's response.
"""
delimiter = "####"
eval_system_prompt = f"""You are an assistant that evaluates whether or not an assistant is producing valid responses.
The assistant should be producing output in the format of [CUSTOM EVALUATION DEPENDING ON USE CASE]."""
eval_user_message = f"""You are evaluating [CUSTOM EVALUATION DEPENDING ON USE CASE].
Here is the data:
[BEGIN DATA]
[Response]: {agent_response}
[END DATA]
Read the response carefully and determine if it [MEETS REQUIREMENT FOR USE CASE]. Do not evaluate if the information is correct only evaluate if the data is in the expected format.
Output 'True' if the response is appropriate, output 'False' if the response is not appropriate.
"""
eval_prompt = ChatPromptTemplate.from_messages([
("system", eval_system_prompt),
("human", eval_user_message),
])
return eval_prompt | llm | output_parserThe function "create_eval_chain" creates an evaluation chain, which is essentially a series of steps that our LLM will follow to evaluate a given response. This function takes the generated response as input, as well as the model and output parser you would like to use for evaluation.
We specify the evaluation model to output "True" or "False" as this will allow us to easily interpret whether our model passes many of these tests or not. This ensures scalability of the testing mode.
Since the LLM outputs a string, we need to perform post-processing of the test to get our test results in a convenient format. The following function "model_grad_eval()" can be reused to process all our evaluations in a given test set.
def model_grad_eval_format(generated_output):
"""
Evaluates the format of the generated output from the agent.
Parameters:
generated_output (str): The output generated by the agent.
Returns:
bool: True if the response is appropriate, False otherwise.
Raises:
ValueError: If the evaluation result is neither "True" nor "False".
"""
# Create an evaluation chain for assessing the agent's response format
eval_chain = create_eval_chain(generated_output)
# Retrieve the evaluation result from the evaluation chain
evaluation_results_str = eval_chain.invoke({})
# Strip leading/trailing whitespaces and convert to lowercase
retrieval_test_response = evaluation_results_str.strip().lower()
# Check if "true" or "false" is present in the response
try:
if "true" in retrieval_test_response:
return True
elif "false" in retrieval_test_response:
return False
except Exception as e:
return(f"An error occured: {str(e)}")
model_grad_eval_format(generated_output="[UNDESIRED OUTPUT GENERATED BY AGENT]")The function "model_grad_eval_format()" analyzes the evaluation result to return a boolean value "True" or "False" or raise an exception. Using evaluations, we can systematically assess the quality of responses generated by language models, allowing us to identify areas for improvement and enhance the overall performance of our application.
Here are a few more tips on model-based evaluations:
Choose the most reliable model you can afford: effective critique of output often requires advanced reasoning capabilities. For user convenience, your deployed system may have low latency. However, effective evaluation of outputs may require a slower and more powerful LLM.
You can create a problem within a problem: without careful consideration and development of model-based evaluations. The evaluation model may make mistakes and give you a false sense of confidence in your system.
Create positive and negative evaluations: something cannot be logically true and false at the same time. To increase confidence, carefully design your evaluations.
Conclusion
Effective evaluation of LLM-based applications requires a multifaceted approach, encompassing both rule-based and model-based evaluations to assess various aspects of system performance.
You should continuously iteratively improve and adapt both your system and evaluation methods to keep up with changing user expectations, system requirements, and advancements in LLM technologies.
By applying a systematic, iterative, and observation-based approach to evaluation, stakeholders can gain valuable insights into the strengths and weaknesses of LLM-based applications, contributing to continuous improvement and innovation in LLM application development and deployment.










Write comment