- AI
- A
Hippo-RAG: Long-term memory for LLM inspired by neurobiology
Scientists are often inspired by our or animal biological structures: CNN, MLP, Backprop, and for many other studies, similarities can be found in the real world. Recently, an article was published that does the same, but for RAG. In a way, this is the long-term memory that modern LLMs lack. This is understandable, but what does the neocortex, hippocampus, and other complex words have to do with it? Let's take a look.
LLMs are now being integrated into all our spheres, ChatGPT has made a lot of noise, but during this time one of the main problems has not been solved: how to control the model's memory? Here we have trained the latest o1, but we still hang the label “Model trained on data up to October 2023” - what next? A whole range of tasks is very difficult to solve without the context of the modern world - the model knows only what it was trained on. RAG is one of the ways to control long-term memory for LLMs. There are many types of RAG implementations, but today we will focus on one - Hippo-RAG. This is a brief summary of this year's article.
The theory of memory indexing by the hippocampus
– is a theory explaining the principle of long-term memory. It involves three parts of the brain: the neocortex, parahippocampal areas, and the hippocampus itself. Together they work on two tasks: pattern separation, ensuring the uniqueness of representations of perceived events, and pattern completion, allowing the reproduction of complete memories from a partial impulse.
Pattern separation is carried out during memory encoding:
Memory encoding begins with the neocortex (new cortex) receiving and processing perceived stimuli, transforming them into higher-level features.
Then these features are transmitted through the parahippocampal areas to the hippocampus, which performs their indexing.
In the hippocampus, significant signals are included in the “index” and linked to each other.
Pattern completion allows "finding" in memory close memories to a certain event.
It begins with the hippocampus receiving partial signals through the parahippocampal tract.
The hippocampus uses its context-dependent memory system, which is believed to be implemented through a dense network of neurons in the CA3 subregion, to identify complete and relevant memories in its index.
This information is then transmitted back to the neocortex to simulate the full memory.
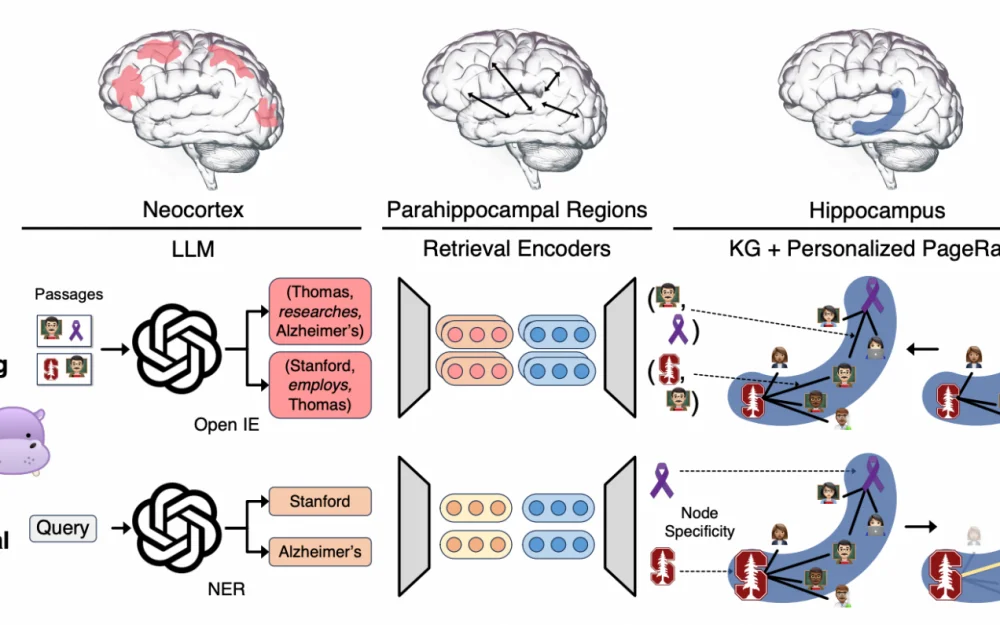
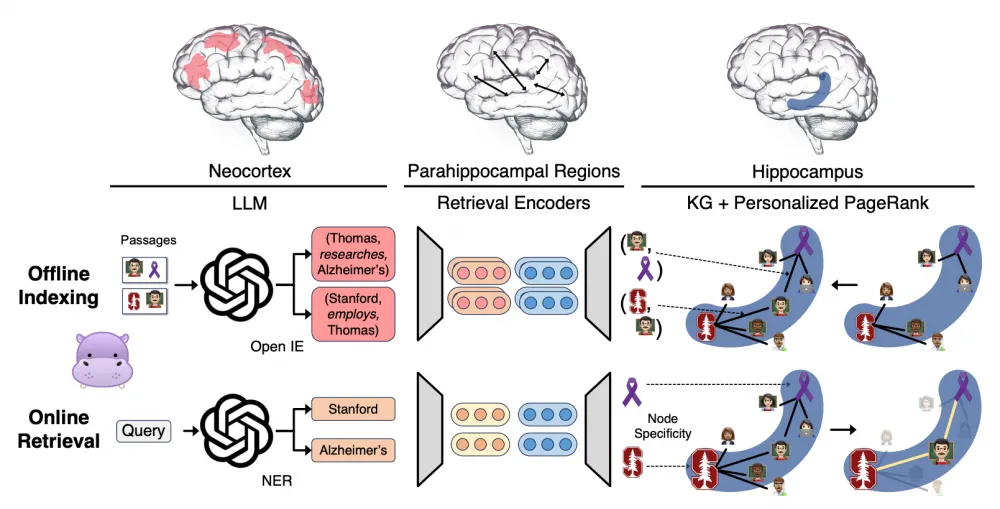
So, that was a lot of theory. Let's realize it once again: the neocortex extracts high-level features from stimuli, then the hippocampus indexes them, and when the memory needs to be retrieved, the hippocampus uses the neural network to find relevant memories and transmits this back to the neocortex. This is illustrated in Fig. 1.
HippoRAG
The architecture has ML components for each of the three brain regions. The LLM acts as the neocortex, the parahippocampal areas are the encoders, and the hippocampus is the knowledge graph and PageRank for search. Accordingly, there are stages of pattern separation and pattern completion. We have a set of text paragraphs P, which serve as our "memories".
Offline Indexing, or pattern separation
Instead of the neocortex, the LLM is used here to extract triplets – N, for example, (Thomas, study, Alzheimer). The authors argue for their choice of triplets over vector representations, citing the ability to separate knowledge into more granular parts. This is somewhat questionable, but okay. Then they use Retrieval Encoders (just encoder + cosine distance) to create additional edges in the knowledge graph between semantically close entities – this will be needed during knowledge retrieval. Thus, by extracting and expanding the knowledge graph for each paragraph, we get a matrix containing the number of triplets in each paragraph:
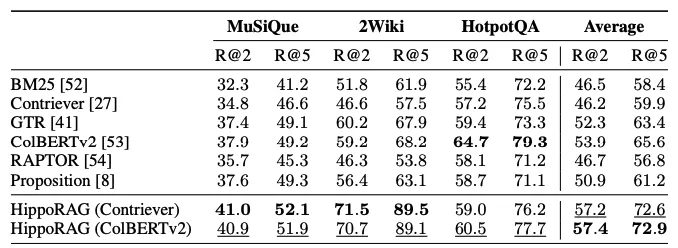
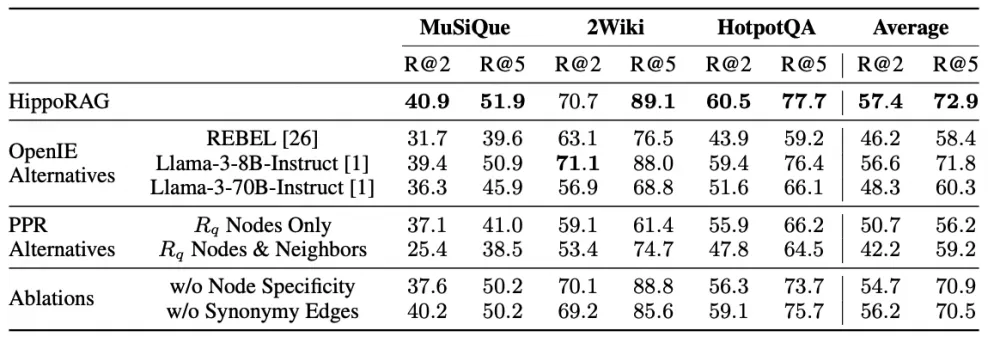
Comparing on datasets with other Retrieval systems, HippoRAG has on average 5-10 points more R@2 and 10-15 points more R@5. If additional steps are connected, for example, IRCoT, the results will be similar.
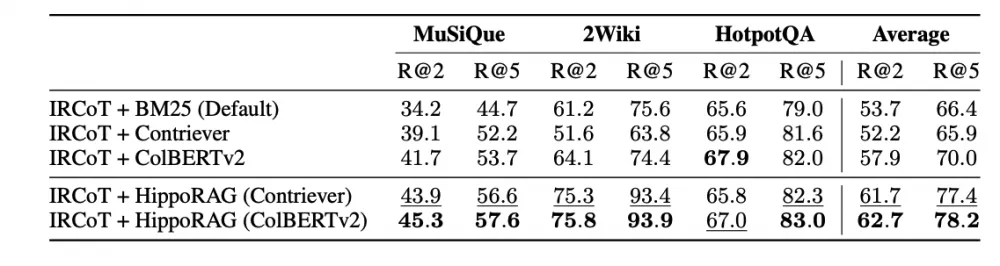
The authors also compared which stage is the most important for the system. The biggest drop occurs when replacing PPR with another algorithm, which is quite logical for a multi-step reasoning task - it is more important to correctly identify the neighbors of our initial nodes, because without them it will not be possible to get the answer.
Conclusion
Lately, I don't often come across articles that were inspired by human processes. Surprisingly, this worked better than the alternatives, and with a deterministic PPR algorithm. What did you find unusual? Leave comments









Write comment