
- AI
- A
LLMs will lie forever
Will we ever be able to trust artificial intelligence?
Despite the impressive progress of language models, they still suffer from a serious "disease" — so-called hallucinations, when AI produces false or meaningless information. One recent study suggests that this problem is not a temporary glitch, but a fundamental feature of neural networks. If this is indeed the case, we will have to rethink our approach to AI.
Research Overview
An article with the telling title "Large Language Models Will Always Hallucinate, and We Will Have to Live with It" puts forward a bold thesis: hallucinations in AI are inevitable due to the very principle of these systems. The authors argue that no matter how much we improve AI — whether it's improving architecture, increasing data volume, or smarter fact-checking — a certain level of hallucinations will always be present.
Their argument is based on mathematical theory. Using concepts from computation theory and Gödel's incompleteness theorem, the researchers show that some limitations are insurmountable.
The authors build their case through a series of mathematical derivations, each demonstrating the inevitability of hallucinations in the nature of large language models. The article concludes with a discussion of the practical and ethical implications of this fact.
If they are right, we will have to rethink our goals regarding AI systems, especially in terms of achieving their full reliability.
Simple Explanation
The work of large language models can be compared to a game where you are asked to describe a picture, but you do not see it entirely. In some cases, you can guess what is missing, but in others, you will make a mistake because you do not have the full picture, and the hidden parts may contain something you could not predict. This is exactly how AI hallucinations work: the system fills in the gaps, but does not always do it correctly.
The authors of the article argue that this is not a sign of technological imperfection, but a fundamental principle of AI operation. No matter how much we train these systems, they will never be able to know absolutely everything. And even if they had access to all the data in the world, there are fundamental mathematical limitations that prevent systems from always accurately extracting the necessary information.
The main conclusion is that instead of trying to make AI flawless, we should accept its shortcomings and focus on how to manage them most effectively.
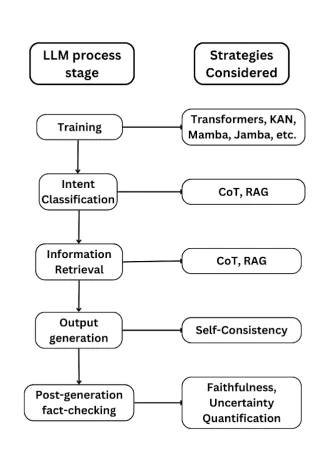
Technical explanation
Based on mathematical reasoning, the researchers demonstrate the inevitability of hallucinations in LLM. First, they justify this by the incompleteness of information, referring to Gödel's theorem and other similar statements, showing the impossibility of creating a dataset containing absolutely all facts.
Secondly, they investigate the process of information extraction, drawing parallels with a well-known problem in computation theory — the admissibility problem, which is unsolvable. Simply put, this means that AI models cannot be expected to be 100% accurate in extracting information. They make a similar conclusion regarding the interpretation of user queries: perfect understanding of user intentions is also unattainable.
Finally, they analyze the language generation process itself. By proving that the halting problem (determining the moment of process completion) is insurmountable for LLM, they argue that systems cannot predict the result of their own generation until it is completed. This opens the way for the occurrence of hallucinations.
The article also shows that no fact-checking system can correct all hallucinations. Even a perfect fact-checker cannot overcome the fundamental computational limitations underlying this problem.
Critical Evaluation
Although the article provides quite convincing mathematical proofs, some points require further study.
Firstly, the authors of the work broadly interpret the very concept of "hallucinations." It seems that the label "hallucination" is applied to any deviation from perfect knowledge, but in practice, many AI systems effectively solve the tasks even with small errors. For many practical applications, a "satisfactory" result is sufficient despite occasional inaccuracies.
Secondly, the article only considers deterministic outcomes, whereas modern AI systems operate based on probabilistic models. This may mean that the conclusions about unsolvability are not fully applicable. Even if ideal behavior is unattainable, the level of hallucinations can be reduced to an acceptable minimum.
The article would also benefit from more empirical evidence and testing of these ideas on real AI models. Additionally, the study is limited to the analysis of transformer architectures, leaving open the question of the applicability of the conclusions to other AI architectures.
Finally, the article does not consider how humans cope with the lack of information and errors in their own thinking. Comparing AI hallucinations with human errors could add a valuable perspective.
Conclusion
If the article's conclusions are correct, we may need to reconsider the approach to the development and use of AI systems. Instead of striving for perfection, we should focus on how to control and minimize the effect of hallucinations. It is also important to explain to users the real capabilities of AI and develop applications that can work effectively even with occasional errors.
I believe this study raises important questions:
How can we assess and reduce the real impact of hallucinations?
Are there new AI architectures that could avoid some of these problems?
How should regulations and ethical standards change to account for the fact that AI will always have flaws?
What do you think? Have the presented evidence convinced you? How will these conclusions affect the development of language models and our trust in them?









Write comment