- AI
- A
Autogeneration of tests for Java/Kotlin in IntelliJ IDEA: comparison of AI tools
For most developers, tests are the least favorite part of the job. Recently, we confirmed this by surveying more than 400 developers at the Joker and Heisenbug conferences about their attitude towards AI tools for testing. In the article, we will tell you what else interesting we learned from them, as well as what AI tools exist for automatic test generation, what their pros and cons are.
Why no one wants to write tests and what do language models have to do with it
So, what conclusions did the participants of Joker and Heisenbug help us to draw. Firstly, it turned out that despite the fact that with the advent of transformers, the community has a powerful tool for generating code, most of the respondents do not use any AI tools in their daily work:
We assume that this is due to security requirements. Many specialists with whom we managed to communicate confirmed that they are not ready to consider AI assistants without on-premise.
Secondly, according to developers, there are several main problems with writing tests:
laziness/long/boring (the overwhelming majority!)
repetitive work
it is difficult to come up with many edge cases
it is difficult to properly mock dependencies
If the process is monotonous and boring, it is worth thinking about its automation. The problem of test autogeneration has existed for a very long time, it was traditionally solved using test template generation, property-based testing, fuzzing, and symbolic execution. The first two approaches force you to partially write tests manually, for example, to come up with test data or properties. The last two approaches generate unreadable tests that are difficult to maintain. So, for example, although symbolic execution is able to create 5 thousand tests with one hundred percent coverage, it is completely impossible to read and maintain them in the long run.
Thus, the ideal test tool:
does routine work for the developer
saves the developer's time on coming up with corner cases
understands the context of the codebase
generates maintainable human-readable tests
helps with mocking
Thanks to ChatGPT, a new promising way of generating tests using a language model has emerged: copy your code into ChatGPT, ask for tests, and it will generate them for you.
Why do we need specialized plugins for test generation at all?
Strictly speaking, a plugin is not required for test generation. You can subscribe to one of the models and send requests for generation directly in the web chat at chatgpt.com. There are many plugins that integrate the chat into the IDE, such as Codeium, or complement the code, like GitHub Copilot. Why not use them for test generation as well?
The key problem is gathering the code context. If you give the LLM only the code of the function without its dependencies, it is strange to expect good tests or that they will even compile (imagine you were given an unfamiliar codebase, forbidden to look into it, and asked to write a test for a random function). Manually specifying all dependencies is also a routine mechanical task. Therefore, a good test generation plugin should automatically gather reasonable dependencies into the prompt.
Prompts (task descriptions for the LLM in natural language) are a very important part of interacting with the LLM. The quality of the prompt determines the quality of the generated tests: their compilability, adherence to the style of the codebase, and what test coverage they will provide. Composing such a prompt well is a laborious task. It turns out that the developer replaces the monotonous task of writing tests with the task of correcting and rewriting the prompt. LLM plugins for test generation try to shield the user from this nightmare by offering ready-made pipelines for different generation cases with prompts for different use cases already "built-in".
Why do we need specialized plugins for test generation if AI assistants for code generation, such as Codeium, Cursor, Gigacode, can collect context and use task-specific prompts? Their capabilities are broader but less specific in terms of user experience: the plugin should not only automatically generate code but also integrate with the existing codebase. For example, it should determine the language version, build system (Maven, gradle, Kotlin gradle), mocking framework (mockito or mockk), test library (ktest, junit, TestNG), the style of tests used in the project, and so on. If all this needs to be specified in the prompt manually, then there is no particular difference whether you generate tests using chatgpt.com or Codeium.
☝️🤓: Despite the obvious advantage of understanding the context, language models have drawbacks. For example, you cannot guarantee that the code provided by the LLM will compile and run. Also, each of the existing LLM tools operates with so-called "semantic coverage" rather than actual instruction coverage, so, generally speaking, you have no strict guarantees that increasing the number of LLM tests will increase instruction coverage.
Which one to choose?
To assess the advantages of specialized plugins for test generation, it makes sense to compare them with each other.
For analysis, we will consider Tabnine, Qodo, Explyt Test, and TestSpark, as well as mention Diffblue Cover, which represents an ML-based approach without using LLM. Codeium, GigaCode will serve as an alternative to specialized approaches.
Which plugins will we compare?
I have already mentioned that you can use an AI assistant that can work with the project context to generate tests. For comparison with specialized tools, we will take two such products: Codeium and GigaCode.
Typical tools for generating tests using LLM – Tabnine, Qodo, Explyt Test. Language models allow you to quickly generate code in any language, UI and two-phase generation (test scenarios, then code) allow you to manage corner cases. Another LLM tool is TestSpark, a plugin for generating tests in java and kotlin, unlike Tabnine and Codium, it skips scenario generation, but allows you to edit the code of each test directly in the generation window and has open source code.
There are also ML-based solutions, but without using LLM, such as Diffblue Cover. It is claimed that the tests generated by it, unlike the tests generated by LLM tools, always compile and run.
Comparison
The basic functionality of all the compared plugins is similar: you select the required method or class, press the button in the interface, and get the code of test methods or classes:
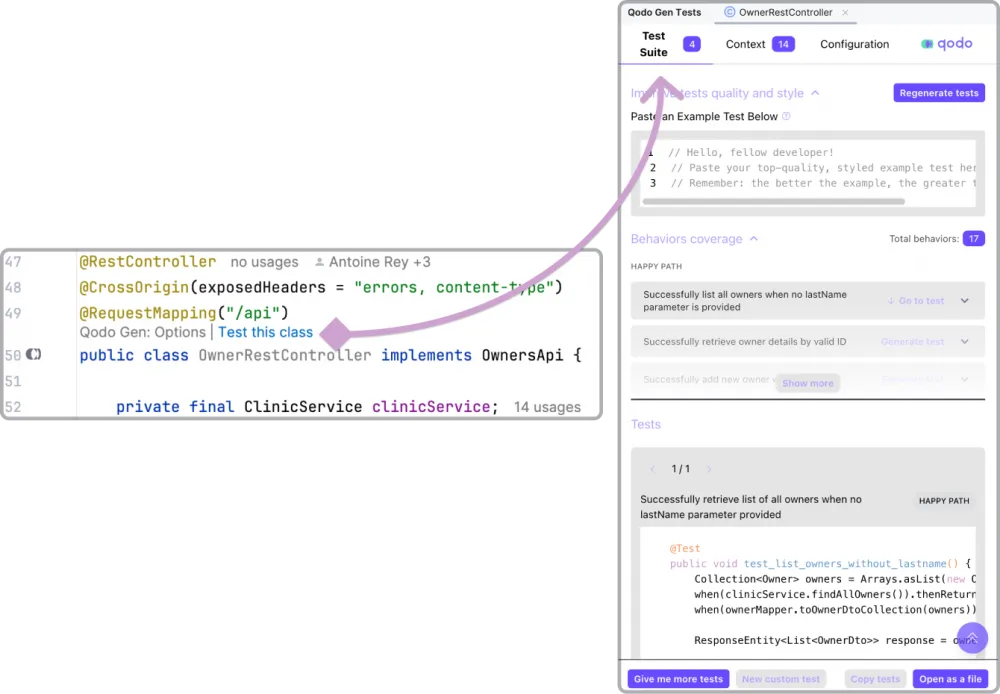
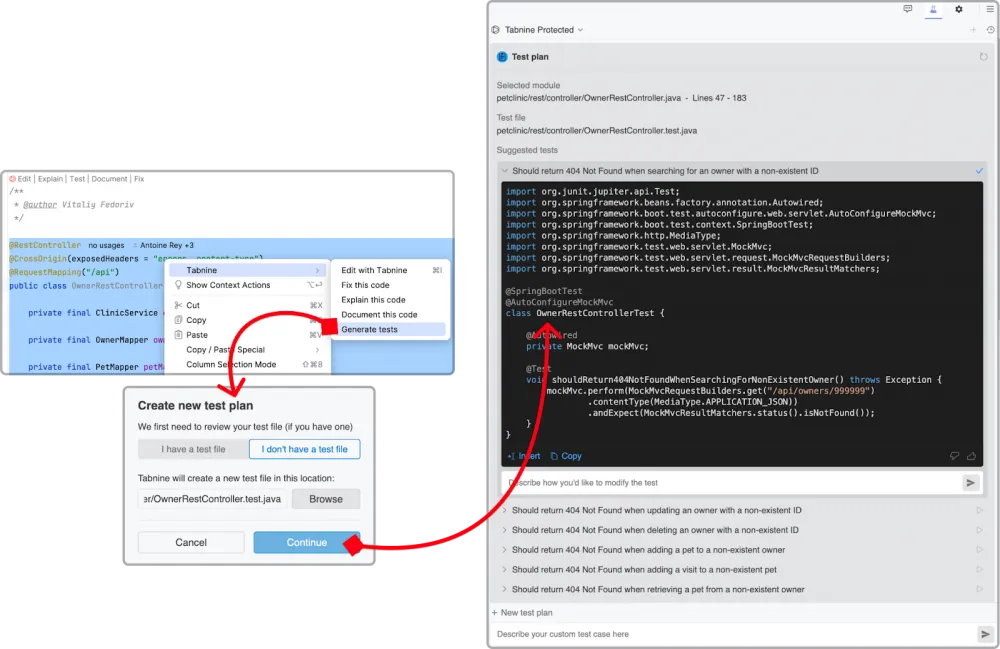
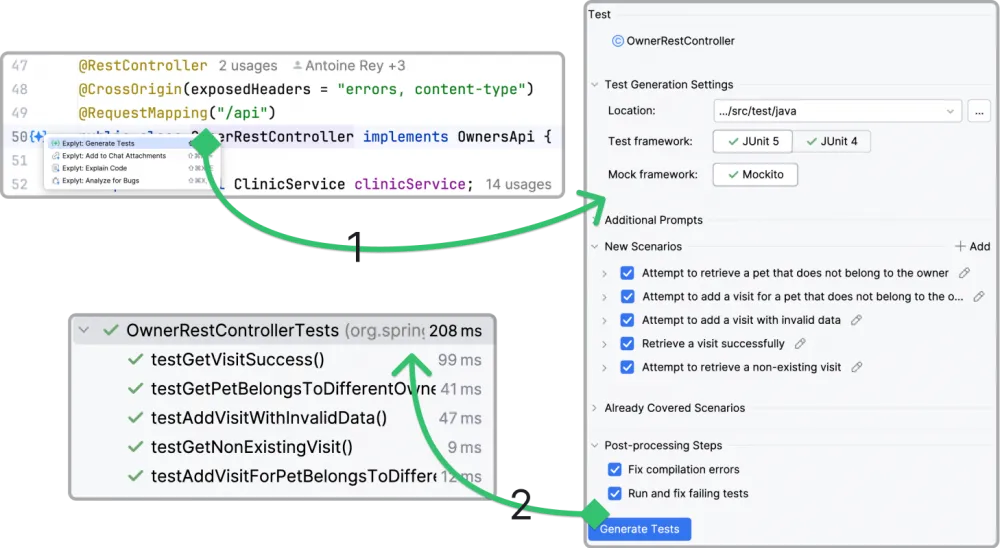
What then distinguishes them from each other?
What unique features do these plugins have?
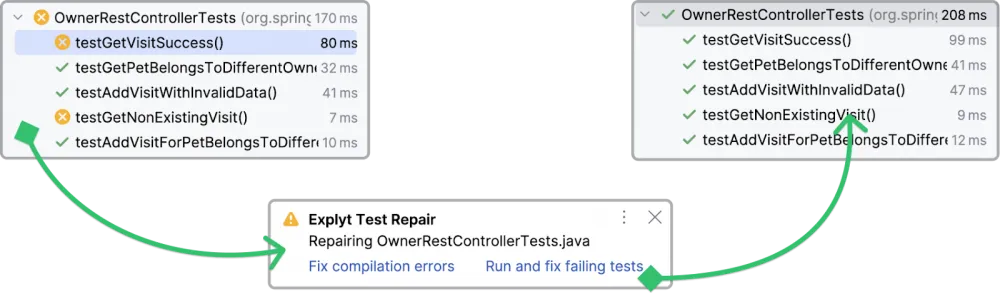
Automatic correction of non-compiling and failing tests
Frontier language models can classify emerging problems and offer solutions "out of the box". It is convenient when the test generation plugin has a button that allows you to automatically fix the test using the language model.
Creating autofixes is a consequence of the inability of LLM to generate compiling code, correctly import dependencies. We talked about these and other problems at JokerConf.
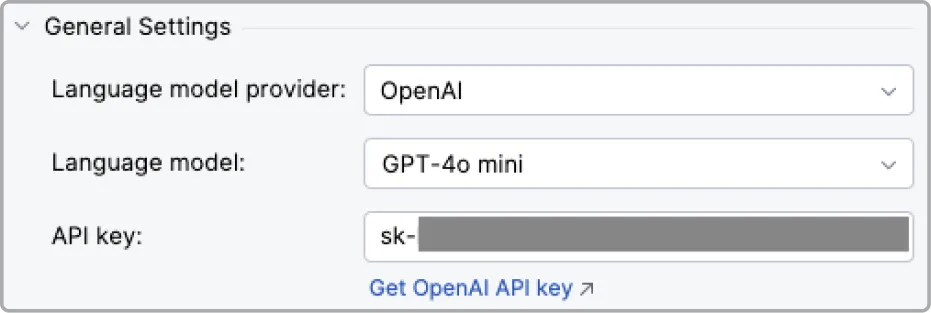
Using your own LLM key
If you already have a personal or corporate key from any provider, it is very convenient when the test generation plugin allows you to use it and interact with the provider directly.
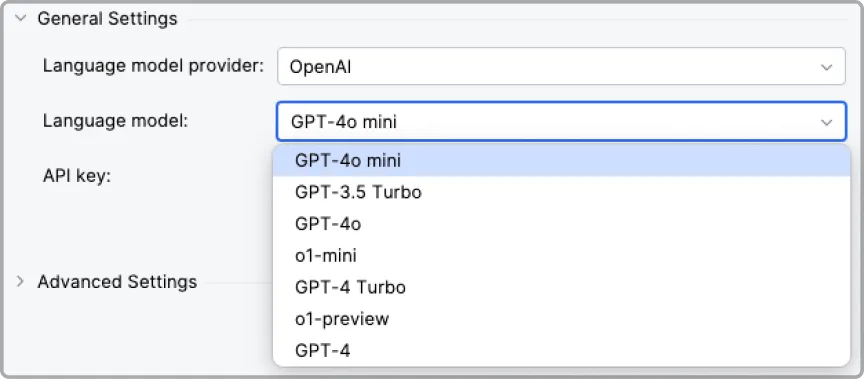
Provider and model customization
In language models, there is an arms race, and OpenAI models do not suit everyone. It is good when the test generation plugin allows you to change the provider and model to better suit your usage scenario. For example, DeepSeek is significantly cheaper than top providers, Groq generates thousands of tokens/sec, while others measure generation speed in hundreds of tokens/sec.
Fine-tuning the model for your codebase
Fine-tuning is the process of adapting a model for a specific task. Some plugins allow you to fine-tune language models on your codebase to improve generation quality. According to Codeium, fine-tuning can significantly improve the quality of code proposed by the AI assistant.
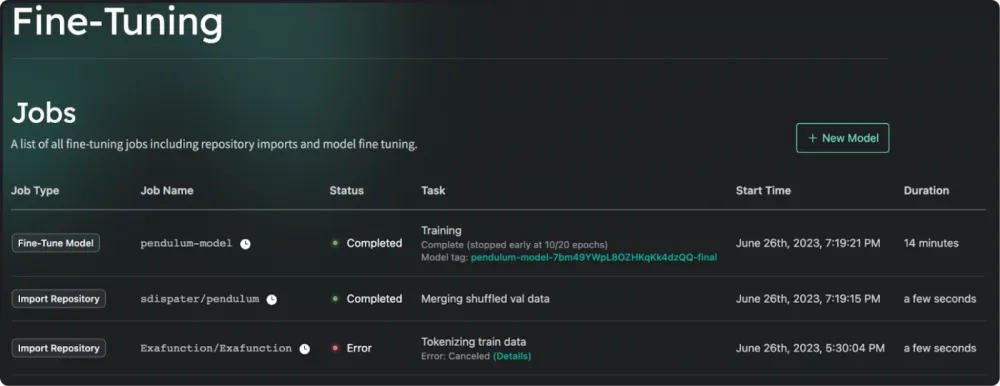
☝️🤓: It is worth noting that fine-tuning in a closed loop is a complex task and may not be worth the effort. The effect of fine-tuning heavily depends on the quality of the data, and fine-tuning itself is difficult to automate.
Using a locally deployed model
Sometimes you want the code not to go to the internet, or there is simply no access to the internet (for example, on a plane). If the computer is powerful enough, you can place a large enough language model on it that will generate meaningful code. For this, there is, for example, the Ollama project, which allows you to deploy any model with open weights locally. It is good if the test generation plugin supports the ability to use a locally deployed model.
☝️🤓: Although the possibility of running the model locally does exist, you need to be careful when using models for test generation. On most work laptops and computers, an arbitrary open model will either work too slowly or produce poor results. Since some laptop manufacturers are designing new devices with specialized processors for neural networks, this situation may improve in a few years.
For convenience, we have compiled all the considered attributes for all solutions into one table. Since Diffblue Cover operates based on RL, not language models, parameters related to LLM are not applicable to it. Diffblue does not support test repair, you cannot choose an ML model for generation, and you cannot retrain it. Also, Diffblue Cover works exclusively locally, although it requires an internet connection for all tariffs except Enterprise.
Plugin | Auto-fix tests | Own LLM key | Provider and model selection | Retraining | Local hosting |
Codeium | no | no | yes | yes | no |
GigaCode | no | no | no | no | no |
Tabnine | no (for jvm) | yes (enterprise) | Tabnine, OpenAI, Claude | yes (enterprise) | no |
Qodo | no (for jvm) | no | OpenAI, Claude, Gemini | no | no |
TestSpark | yes | yes | HuggingFace, OpenAI | no | no |
Diffblue Cover | no | - | - | - | works only |
Explyt Test | yes, but only for LLM tests (compile + runtime) | yes | OpenAI, Claude, Gemini, DeepSeek, Groq, Cerebras, Anthropic | no | yes |
How do plugins work with project context?
Proper context selection is very important for obtaining high-quality results from LLM.
There are several ways to collect code context. The simpler one is heuristic, like in GitHub Copilot: analyzing the last three open files. Such heuristics are not suitable for generating tests, as a specialized algorithm is needed specifically for generating tests. Although most AI assistants require collecting context manually, an automatic context collection can be implemented for the task of generating tests.
It is often desirable for the generated test to be similar to the existing ones, down to the specifics of the tested behavior. To ensure the "similarity" to the user code automatically, the test plugin should be able to find and use similar tests as a template automatically: see how they are structured and pass the information to the prompt. It is also good if the user can choose such a reference manually.
Often, the code is also influenced by non-code context. It may include application configuration files that do not contain code but are important for understanding the context of the tested application. Examples of non-code context are an xml file with Spring bean configuration, an env file with environment variables.
Plugin | Context | Using a similar test | Non-code context |
Codeium | auto+manually | manually | no information |
GigaCode | selection or current file | manually | no information |
Tabnine | auto+manually | manually | no information |
Qodo | auto+manually | manually | no information |
TestSpark | auto | manually | no information |
Diffblue Cover | auto | no | no information |
Explyt Test | auto | auto | in development |
What if it is important which servers the code is sent to?
Although there are free chat providers and code generation tools, our surveys show that the vast majority of specialists do not use AI tools at all. When asked "why?" they usually answer that it is prohibited by company policy due to security requirements: the source code must not leave the company's perimeter, and it is forbidden to use tools with third-party hosting. However, if you really want to use the tool, you can choose a hosting that meets your privacy requirements:
Community. Your requests are sent to the LLM provider's server. Depending on the chosen plan, the provider may promise not to use your data to train models or provide an opt-out (Qodo does this, providing an opt-out for the free version). Some providers (such as Tabnine) can request zero data retention: your request data will not be stored on the servers at all.
(Virtual) Private Cloud ((V)PC). You use the cloud provider's infrastructure, while remote access to it is only available to you. Such a service is provided, for example, by Amazon, Yandex, and cloud.ru from Sber.
On-premise hosting. You fully manage the infrastructure on which the solution is deployed, as your servers or servers to which you have access are used.
For international software security certification, the SOC 2 protocol is used. In short, a SOC 2-certified SaaS product provider meets five criteria: security (protection against unauthorized access), availability (ensuring service availability according to agreements), processing integrity (data accuracy and authorization), confidentiality (restricting access to data), privacy (compliance with personal information processing policies). In Russia, there is an equivalent - FSTEC certification, the requirements of which are generally similar to SOC 2. None of the foreign plugins, of course, have passed FSTEC certification.
Plugin | Private hosting options | Certifications | FSTEC Certification |
Codeium | on-prem (enterprise) | SOC 2 | no |
GigaCode | on-prem | no | yes |
Tabnine | on-prem (enterprise) | GDPR, SOC 2 | no |
Qodo | on-prem (enterprise) | SOC 2 | no |
TestSpark | unavailable | no | no |
Diffblue Cover | runs locally only | - | no |
Explyt Test | on-prem (enterprise) | planned SOC 2, GDPR | planned |
What can be obtained for free, and what for money?
Most often, for money you get access to more powerful language models, removal of request limits, or improved UX. Tabnine in the paid subscription removes the restriction on the use of frontier models (the most advanced available models, such as GPT-4o), Codeium in the Pro version gives credits for use with frontier models and a more advanced context collection algorithm. GigaCode offers the purchase of tokens for its models directly. Qodo provides all test generation features in the free version without restrictions, including the use of frontier models, adding code autocompletion and several other non-test-related features in the paid version. Explyt Test allows you to purchase tokens to use them for generation. In a typical usage scenario, a programmer spends an average of 3000 tokens per month.
Diffblue limits differ from all other providers in that it provides a limited number of generations - clicks on the "create test" button.
Plugin | Works in RF | Free | Paid |
Codeium | no | free only models from Codeium | 15$ |
GigaCode | yes | 10^6 free tokens | |
Tabnine | no | Tabnine models: no limits, frontier models: 2-4 requests per day | 9$ (90 days free) |
Qodo | no | no limits | 19$ (14 days free) |
TestSpark | from sources | - | - |
Diffblue Cover | no | 25 generations/month | 30$: 100 generations/month |
Explyt Test | yes | one-time: 1000 tokens | $0.01/1 token |
In conclusion
There are other approaches to test generation. For critical code, tools based on symbolic execution, such as UTBot Java, can be considered. Symbolic execution allows for efficient enumeration of states that a program can reach, thus covering the program well with tests.
As a less fundamental approach, you can choose solutions based on automatic code analysis, such as Squaretest, Jtest. Because the correctness guarantees of these tools are weaker, the code is generated faster.
We are preparing material on alternative approaches to test generation. What else would you like to know and what is interesting to discuss? Have you already tried tools for automatic test generation, with and without LLM? Share your experiences and opinions in the comments. Thank you for reading to the end :)









Write comment