- AI
- A
O3 displaces programmers? How OpenAI surprised everyone again
Hello, tekkix! My name is Vladimir Krylov. I am a professor of mathematics, a scientific consultant at Artezio, and the author of the Ai4Dev Telegram channel. Our team closely monitors the development of AI technologies and their impact on software development. The latest OpenAI announcement made me write about new technologies on the spot. Usually, I prefer to wait for real test results. However, the presentation from the last day of the OpenAI Christmas event broke all barriers.
In anticipation of a miracle
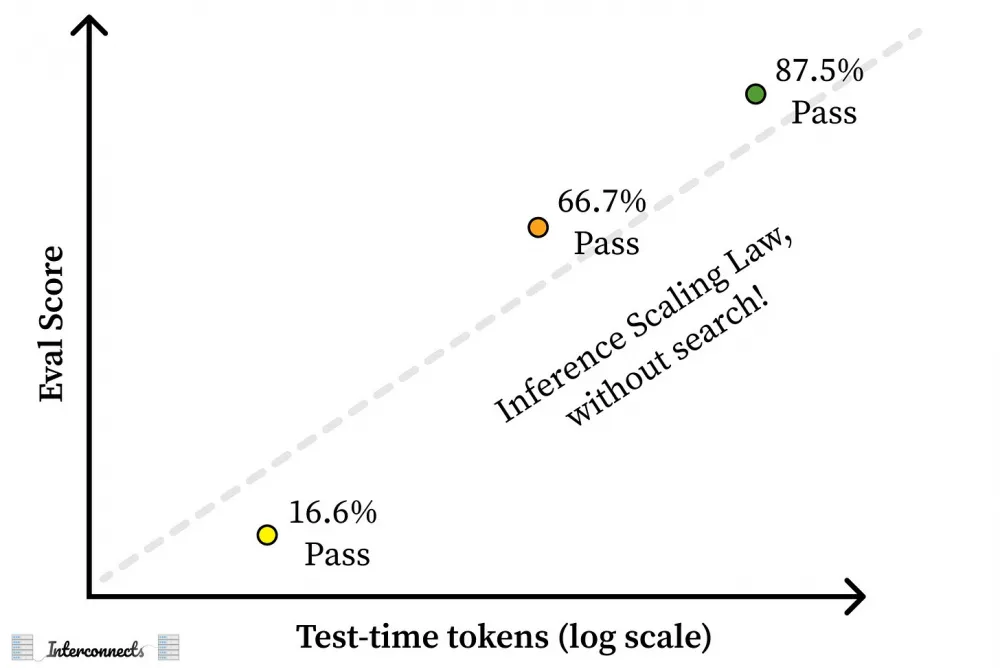
The announcement of the new OpenAI o3/o3-mini models is not just the next step in the development of Foundation Models, not another SOTA, but a message about a leap to the next level, which is unlikely to be achieved by competitors in the near future. The headlines of publications based on the event sound like this: "The OpenAI o3 model is a message from the future: forget everything you think you know about AI." The new models are noticeably different from their currently most successful counterparts in terms of coding and PhD-level mathematics. One of the significant tests in which the models made a breakthrough is ARC-AGI. It was first introduced by deep learning researcher François Chollet as a set of tasks that are intuitively simple for humans but surprisingly difficult for neural networks. The best result to date achieved by humans is about 75%. o3-mini shows similar figures, and o3 demonstrates 87.5%, which is much higher than humans.
But here I will not discuss the mathematical abilities and level of logical reasoning of o3, but will only analyze the assessment of testing on software engineering tasks on SWE-bench, which is called SWE-bench Verified, and what is the ELO rating of the new model as a participant in Codeforces programming competitions.
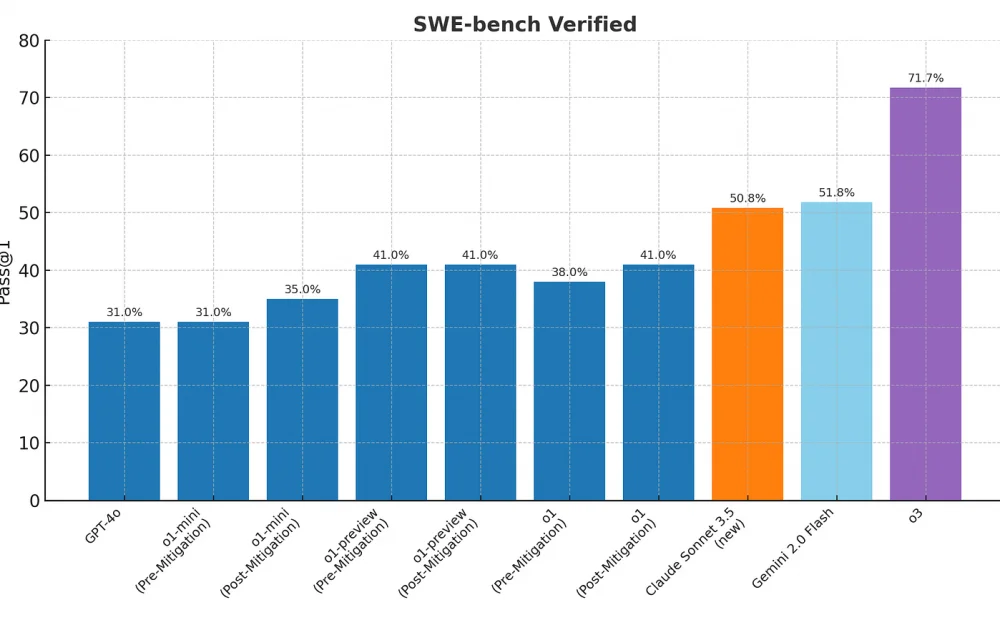
This is what the evolution of accuracy on SWE-bench looks like in 2024. This is a quantitative assessment of how well AI systems can see and correct errors in code.
For the first time, the new model immediately showed an increase of 20% and 40% over six months. Behind this percentage lies the fact that the ability of o3 to solve problems from real GitHub repositories means that the model can not only help programmers debug and implement functions more efficiently than other software development tools. o3 generates new paradigms in software development, where AI acts as a full-fledged assistant, not just a tool.
Now let's turn to the results of the sports programming ranking.
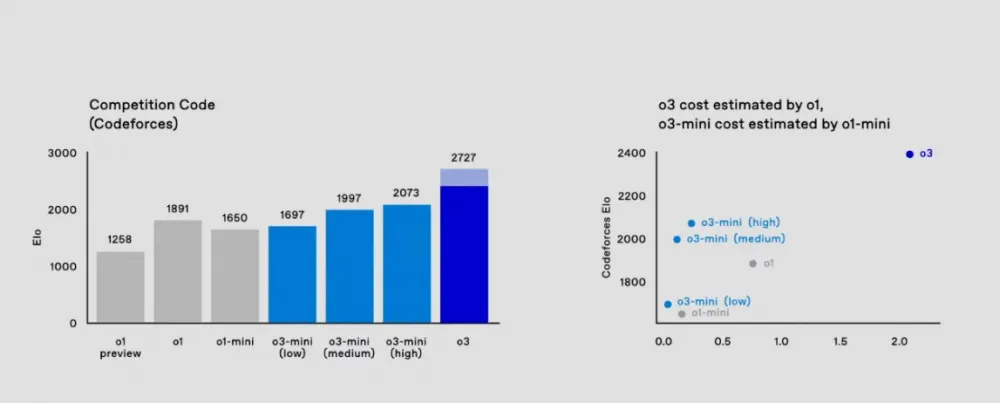
ELO 2727 puts o3 among the top 200 competitive programmers in the world. This is higher than the rating of the Chief Scientist of OpenAI, which is 2665.
By the way, many people ask what the shaded part of the rating means. The solid columns show the "passed on the first try" accuracy, and the shaded part shows the result of the majority vote (consensus) on 64 attempts.
Moreover, ELO 2727 indicates that o3 is within the 99.7 percentile of all participants, meaning it surpasses approximately 99.7% of all Codeforces participants, illustrating its status in the competitive programming community. This percentile ranking helps to understand how rare such a high result is among thousands of competitors. The o3 consensus voting score is 2727, which puts it at the level of an international grandmaster and roughly in the top twenty competitive human programmers on the planet. o3-mini surpasses o1. At the same time, o3-mini is significantly cheaper, which, given the trends, will allow it to become the most efficient model used by the masses. And the cost of using o3 is still sky-high. I have not found any exact estimates anywhere, but it is known that o3-mini spends $17-20 per task, while the o3 model is "approximately 172x" the cost of o3-mini. In other words, $2.5-3 thousand per task and a staggering $1 million for the entire set of tasks. At the same time, costs are expected to decrease as more energy-efficient chips and optimized software become available.
Well, probably the question that interests many readers is how such results were achieved? Has the model architecture changed, and how was it trained? Obviously, it is unlikely that we will ever find out about o3. We will wait for similar open-source models. But here are some guesses that have been made. The main mechanism of o3 is apparently the search and execution of programs in natural language in the token space: during testing, the model searches the space of possible chains of thoughts (CoT) describing the steps necessary to solve the problem, in a way that may not be too different from Monte Carlo tree search in the style of AlphaZero. In the case of o3, the search is apparently controlled by a separate evaluation model. Lead OpenAI developer Nat McAleese wrote on X: "o3 works by further scaling RL beyond o1, and the power of the resulting model is quite impressive." Based on research by Sasha Rush and Daniel Ritter, this is one of the possible directions of learning systems at OpenAI. Sasha Rush is exploring four likely approaches:
guess + check,
reward processing,
search / AlphaZero,
learning to correct.
The first and last option is confirmed by a comment from the company's blog: "When training models to reason, we first thought of using human thought records as training data. But when we tried to train the model to independently build logical chains through reinforcement learning (RL), the results surpassed human ones. This discovery was a turning point in scaling the technology."
From an architectural point of view, there are assumptions that the added layer in o3, which probably breaks down unfamiliar problems into parts, is a breakthrough. o3 models use what OpenAI calls a "private chain of thoughts," where the model pauses to examine its internal dialogue and plan ahead before responding. This can be called "simulated reasoning" (SR) – a form of AI that goes beyond basic large language models (LLM). o3, like o1, learns to hone its chain of reasoning, improve the strategies used, recognize and correct its mistakes, break down complex steps into simpler ones, and also try a different approach to solving the problem if the initial one did not work. Corrections and finding other strategies are somewhat reminiscent of the DPO process. The key difference is that management does not necessarily have to occur at every step – there may be a set of steps that are checked only when an incorrect final answer is reached.
In any case, we have only confirmed that, having exhausted all possibilities for scaling LLMs in terms of size and computational volume for training, developers have opened a new format in scaling models: from LLM to LRM (large reasoning model). And this dimension is the computational cost of inference.
So, what does all this mean for us? Literally in a couple of years, the world should expect a change in demand for a number of white-collar positions – from web design to coding. Already anyone who performs mostly repetitive work will be in a precarious position or fired. At the same time, I am sure that other jobs will be created that require different skills and knowledge. Goals will change, but companies will still compete, and we are quite far from the point where people will not be needed at all.
Is it good or bad? I think that any change that increases productivity, opens up new knowledge and opportunities is great. This is exactly how our civilization has achieved what we have now. History has not been kind to societies that resisted such changes, so it is better to be prepared for this process and try to approach it positively.









Write comment