
- AI
- A
Replacement of Langchain: How OpenAI Agents SDK Handles Deep Search?
Agents are super buggy. In our company projects, we noticed that Langchain started to perform worse. In multi-agent systems, agents often loop because they don’t understand when they have completed the final action, don’t call each other when needed, or simply return data in broken JSON format. In short, creating an agent system has become more difficult, and we even started considering simplifying systems by getting rid of a lot of agents. And just a week ago, OpenAI updated the SDK for creating agents and also rolled out access to new tools via API. So I went ahead and started testing.
I am Arseniy, a Data Scientist at Raft, and today I will tell you about the OpenAI library for creating agents from OpenAI.
Multi-Agents
Multi-agent systems are super important because they prevent the dilution of context in the models they're built on, making their performance more stable. You can’t just throw a massive system prompt into a single agent and expect it to handle every case perfectly. Tasks for agents should be as straightforward and atomic as possible for better performance, and the overall result should depend on agent interaction.
The familiar agent creation pipeline via Langchain is already outdated; the library’s developers themselves suggest migrating to LangGraph. You can fix bugs in agents written with Langchain through prompting, but this takes a lot of time writing instructions that don’t even relate to the core task—for example, explaining to the agent after which specific function it gets the final answer, and what the answer should look like so it can be returned to the user.
Besides that, logging and debugging agents is not super convenient. You can manually set up logging in Grafana and record agent outputs there, but in my experience, it’s not very easy to read and requires extra Grafana setup.
OpenAI Agents SDK
For the last two weeks, OpenAI has been rolling out changes to its API so that developers around the world can integrate this into their applications. File search, web search, computer use, as well as new audio models are now available in the API. In addition, they have updated their own library for agents, where you can use all these functions within the agent and also create your own custom ones. The obvious advantage is compatibility with their own models, support for JSON output format—which allows you not to worry about output formatting and easily link agents together—built-in logging, and other features like specifying specific tools after which you can finish the action and provide a response.
The documentation isn’t super complete, but it’s good enough to get started. Using it, let’s build a simple system where we leverage two important tools—file search and web search. So our goal is:
Research agent (like deep search in GPT).
What it does: Analyzes what the user enters.
Asks clarifying questions if needed.
Analyzes files and the internet for relevant data.
Provides a complete report with links to sources.
As a file, I chose data from one of the largest agro producers of fertilizers and seeds. The file is 340 pages and weighs around 50 MB. We’ll be asking questions related to fertilizers.
So, let’s go step by step and start with the first point
Step 1. Analyzing the user's question
This will be a simple agent without tools, which will communicate with the user and clarify questions.
from agents import Agent, Runner
query_analyzer_agent = Agent(
name="QueryAnalyzer",
instructions="""
You are an agent that analyzes user queries. Users ask you questions expecting,
in the future, an answer using files and the internet.
Your task is to understand the query, determine its topic and structure.
Highlight key aspects, names, attributes, and determine whether a clarifying question is needed.
Do not overuse clarifying questions. If you have obtained the key information,
do not ask the user again.
"""
)
runner = Runner()
analysis_result = await runner.run(
query_analyzer_agent,
f"Analyze the following user query and determine whether clarifications are needed: '{query}'"
"If clarifications are needed, formulate a specific question. "
"If no clarifications are needed, just write 'No clarifications needed'."
)
Runner starts the agent's workflow. The agent will run in a loop until a final result is generated.
The loop executes as follows:
The agent is called with a specific task. In the example above, the user's query is inserted into the task:
"Analyze the following user query and determine whether clarifications are needed: '{query}'
If clarifications are needed, formulate a specific question.
If no clarifications are needed, just write 'No clarifications needed'.If there is a final result (i.e. the agent outputs something like
agent.output_type), the loop ends.If there is a handoff (transfer of data to another agent), the loop restarts with the new agent.
Otherwise, tools are invoked (if any) and the loop starts again.
When creating an agent, you can also choose the model and the API through which the model will be accessed.
It is recommended to use the new version of the Responses API, for example like this
model=OpenAIResponsesModel(model="gpt-4o", openai_client=AsyncOpenAI())But you can also use OpenAIChatCompletionsModel, which calls the OpenAI APIs Chat Completions API
model= OpenAIChatCompletionsModel(model="gpt-4o", openai_client=AsyncOpenAI())
The new version of the Responses API and gpt-4o-2024-08-06 is used by default.
Step 2. FileSearch
We will use the built-in FileSearchTool() in the SDK (more details here). To search through files, you first need to create a file storage and upload your files there. This can be done either via the website or using the API.
On the site:
Create a vector store
Add the necessary files
To use it, save the
vector_idso you can then pass it toWebSearchTool()
API:
from openai import OpenAI
client = OpenAI()
# Create file
local_file_path = "path"
with open(local_file_path, "rb") as file_content:
file_response = client.files.create(
file=file_content,
purpose="file-search"
)
# Create a vector store
vector_store = client.vector_stores.create(
name="knowledge_base"
)
# Add file to the vector store
client.vector_stores.files.create(
vector_store_id=vector_store.id,
file_id=file_id
)Now we can create a file search agent. For this, use vector_store.id and FileSearchTool(). You can specify the number of files to use as relevant for the search result. My storage has only one file, so I use just that one.
from agents import Agent, FileSearchTool, Runner
file_search_tool = FileSearchTool(
vector_store_ids=[vector_store.id],
max_num_results=1
)
file_agent = Agent(
name="FileSearcher",
instructions="""
You are an agent specializing in searching information in uploaded files.
Use the tools you have to search for information in the uploaded files.
Provide complete and accurate information from the files, quoting the source.
This is the most important stage of analysis, as file information has priority.
If the information is not found in the file, clearly indicate this.
""",
tools=[file_search_tool]
)
runner = Runner()
file_result = await runner.run(
file_agent,
f"""Find information for the query: '{query}' in the uploaded file.
It’s very important to find the most relevant information."""
)
Prices and limitations:
Usage price $2.50 per 1000 requests and storage costs $0.10/GB/day, but the first GB is free.
Projects must not exceed 100GB for all files.
Maximum storage -- 10k files.
File size cannot exceed 512MB (approximately 5M tokens)
Step 3. WebSearch
Now that we have information from the file, we can supplement it with a web search. Importantly, we consider the information from the file to be more prioritized, as the file has a more narrow specification.
So first, we create a tool for searching WebSearchTool(). We specify the search context size, which directly impacts the final price, and optionally we can configure the search location
"user_location": {"type": "approximate", "country": "GB", "city": "London", "region": "London"}
Then we create the agent itself and pass it instructions and the tool. After that, we can run it.
from agents import Agent, WebSearchTool, Runner
web_search_tool = WebSearchTool(
search_context_size="medium"
)
web_agent = Agent(
name="WebSearcher",
instructions="""
You are an agent specializing in searching for information on the internet.
Use web search tools to find current information
that supplements or expands on the information found in the file.
Provide complete and accurate information from the search results, citing sources.
""",
tools=[web_search_tool]
)
web_result = await runner.run(
web_agent,
f"""Find up-to-date information on the query: '{query}' on the internet.
The following information was found in the file: '{file_result.final_output}'
Supplement or expand this information with your findings."""
)Prices and limitations:
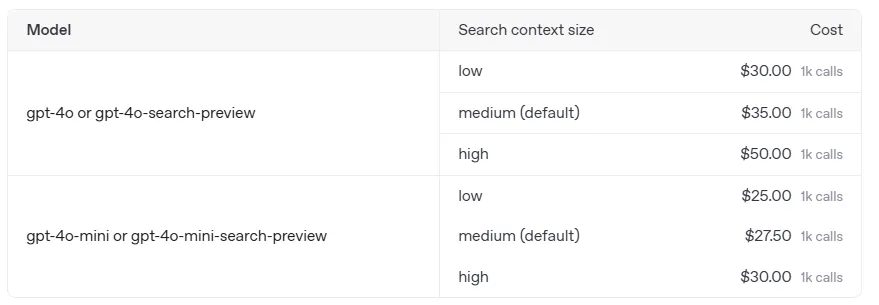
Token charges: The cost depends on the number of tokens used to process the request and generate the response. Starts at $25 per 1000 requests for GPT-4o-mini-search. Exact rates are listed on the pricing page.
Dependence on context size: The choice of search_context_size affects the cost — a larger context increases expenses. Details are available in the pricing section on the OpenAI website.

Step 4. Final Answer
And at the end of the pipeline, we will create an agent that formats all the data into a user-friendly format. This is a regular agent with a simple prompt.
report_agent = Agent(
name="ReportGenerator",
instructions="You are an agent specializing in generating final reports."
"Your task is to summarize the search results from files and the internet."
"Structure the information logically, highlighting key points."
"Avoid large Headings."
"Prioritize information from the file, then supplement it with data from the web search."
"Be sure to include the sources of information (links to files and web pages)."
)
file_info = file_result.final_output
report_prompt = f"""
Generate a complete and structured report based on the following data:
USER QUERY: {query}
INFORMATION FROM THE FILE (PRIORITY):
{file_info}
ADDITIONAL INFORMATION FROM THE INTERNET:
{web_result.final_output}
Be sure to include all sources of information. Structure the report logically.
Information from the file should be presented first, and then supplemented with data from the internet.
"""
report_result = await runner.run(report_agent, report_prompt)Logging
Great, the working pipeline is ready!
You can run it with streamlit run app.py
However, creating agents is not enough, it’s important to know how to debug and log their work. In OpenAI, everything is taken care of, they handle it for you.
So let’s run it with a test query 'Technical specifications of Vibrance fertilizer' and go through all the steps one by one in the logs before viewing the answer.
On the Logs tab, you can see all agent calls via the API. There are a bunch of filters implemented:
API Type: ChatCompletion or Response.
Model Name.
Request Date.
Metadata.
Tools invoked in the requests.
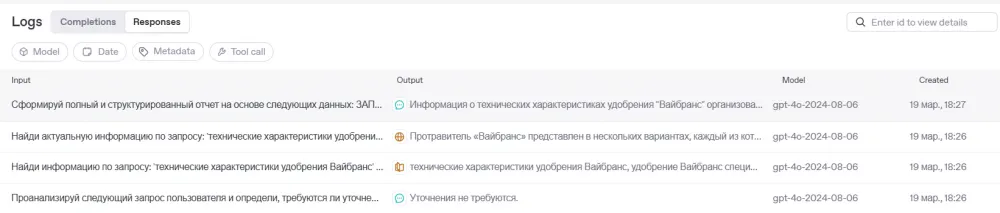
You can see all the agent calls step by step. You can click on each call to view the details.
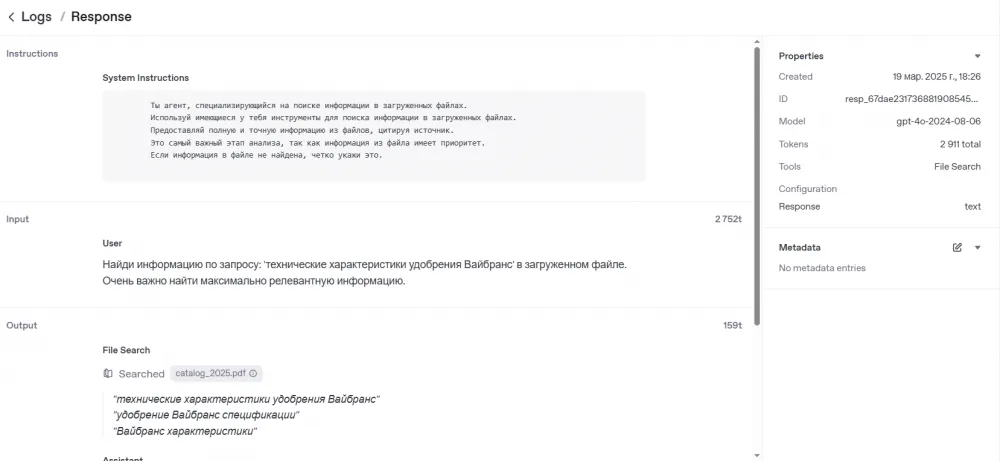
For example, a request to FileSearch. We see the number of tokens used, as well as the keywords for which the search was performed in the file: 'technical characteristics of VibraNts fertilizer', 'VibraNts fertilizer specifications', 'VibraNts characteristics'. This is important for understanding the operation and debugging.
Tracing
In addition to general logging, you can set up tracing for specific processes. This allows you to track agent interactions and the correctness of the entire pipeline's operation. You can do this easily as follows:
from agents import trace
# specify the Workflow name -- Search query
with trace("Search query"):
# all agent call code belowNow each search query can also be tracked in the Traces tab with the Workflow specified.
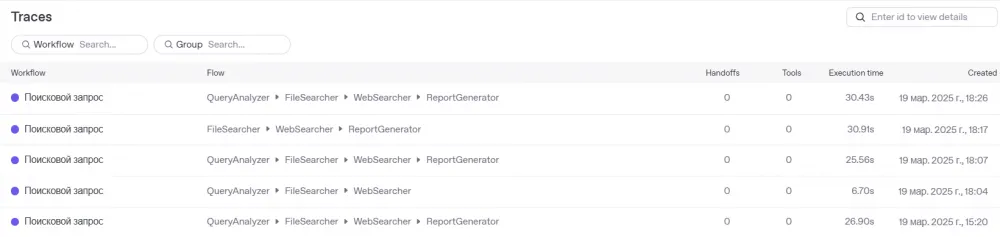
By drilling down, you can see more detailed information about the work of each agent, processing time, and tokens used. The trace shows that the most time-consuming process is WebSearch, about 15 seconds, because we set the "medium" search context size.
File search and other agents work very quickly and precisely, within a few milliseconds.
Final result
As a result, we got a complete research with data from the file and the internet in less than 20 seconds.
Model result:
Information on the technical specifications of the "VibraNts" fertilizer is organized into the following categories:
Technical specifications from the file:
Active ingredients: sedaxan 50 g/l, mefenoxam 37.5 g/l, fludioxonil 25 g/l.
Formulation: suspension concentrate.
Packaging: 5 l canister / package 4 × 5 l.
Shelf life: 3 years from the date of manufacture.
Hazard class: class 3.
Additional information from the internet:
VibraNts Top is used for potatoes.
Active ingredients: thiamethoxam 262.5 g/l, sedaxane 25 g/l, fluodioxonil 25 g/l.
Form: suspension concentrate (SC).
Packaging: 5 l can / 4×5 l pack.
Hazard class: 3rd class.
Application rate: 0.4–0.7 l/ton of tubers.
Action spectrum: Colorado potato beetle, rhizoctonia.
Source: syngenta.ru
Vibrance Trio For winter and spring wheat, barley.
Active ingredients: sedaxane 25 g/l, fluodioxonil 25 g/l, tebuconazole 10 g/l.
Form: suspension concentrate (SC).
Action spectrum: root rot, loose smut.
Application rate: 1.5–2.0 l/ton of seeds.
Source: pr-agro.ru
"Vibrance" is a line of seed treatments designed to protect seeds of various crops from a wide range of diseases and pests. Each product has its unique characteristics and target application.
Conclusion
In the end, it turned out to be a very cool tool, with the ability to implement your own tools, build agents, and orchestrate them. A great plus is the ability to configure through a graphical interface and integrated logging systems.
Of course, the accuracy of the answer depends on the prompt (the clearer and more detailed the description, the better) and how the data is arranged in the file. For example, there were requests with specific names, or requests where the information was on different pages. In such cases, it was not always possible to find the right information in the file, although the information was there. But then web search helped, allowing the agent to work around it.
Overall, I hope to apply the OpenAI Agents SDK in a real project and share the results with you! See you!
P.S. I wrapped the final code in Streamlit, and it turned into a small web application. The code is here.









Write comment