
- Network
- A
In pursuit of the unknown: how an ML model learned to detect malware
Hello everyone! This is Ksenia Naumova. At Positive Technologies, I research malicious network traffic and improve tools for analyzing it at the security expert center. Recently, we were tasked with creating an ML model to detect malware in the network. It had to recognize not only the malware we had previously detected, but also new threats that emerge in large numbers every day. As a first experiment, we decided to build a model to work with traffic transmitted via the HTTP protocol, as our products successfully decrypt TLS sessions, which often contain a lot of interesting data. In this article, I will describe in detail how we trained the model and share information about the mistakes we made.
In the article, I will explain in detail how we trained the model and share information about the mistakes made. Danila Vaganov, who is engaged in developing machine learning models and implementing them in Positive Technologies products, will help me not to miss a single important detail. Thanks to him, our solution is integrated into the PT Sandbox. And if you want to learn about ML in Positive Technologies products, read a separate article.
Feature Set Definition
An experienced analyst can visually determine what kind of traffic is in front of them: clean or malicious. ML works on the same principle, so the effectiveness of the model directly depends on the quality of the features on which it is trained. The set needs to be as complete as possible so that the model can see as many patterns as possible. At the same time, it should not be excessive, otherwise, it will be necessary to store and process data that does not carry useful information for the model.
Based on these conditions, for the first iteration, we selected 69 features characteristic of various HTTP contents.

Subsequently, we optimized the feature description. Firstly, we discarded what did not have a positive effect on the model's responses but only confused it. Secondly, we got rid of invertible features. For example, situations where a feature related to content length is zero, while its opposite is always one. As a result, we managed to reduce the number of features to 36 without loss of quality.

Dataset Preparation
After creating the feature set, the work became more routine. We collected a dataset with PCAP files containing HTTP sessions of interest to us and then processed and converted each interesting stream (session) into TXT format, skipping the unnecessary ones. Then, using scoring and pre-developed features, we transformed the TXT files into a CSV table. In it, all the features were assigned some numerical value for the total scoring calculation. The ML model was trained on the resulting values. We wouldn't claim this was the most optimal solution, but it did work.
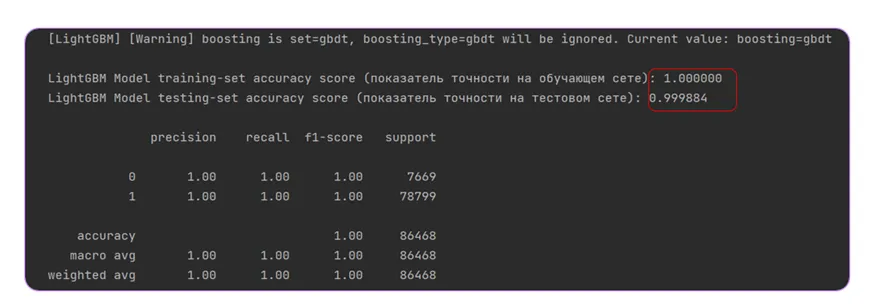
The training itself was carried out using the LightGBM classification method — gradient boosting. The initial results were already impressive: regardless of the number of suspicious files the model was trained on, the result never fell below 99.9%.
Elated by the success, we handed the model over to the ML team for further improvements by colleagues.
Error Handling: Verifying the Solution in Terms of Data
Before deploying an ML model in a production environment, it's important to ensure that it will work correctly under real conditions. It's necessary to understand whether the data used for training truly reflects the population relevant to the companies that will implement the product. Errors may arise due to the difference between expert and ML approaches to traffic analysis. Experts mainly work with dangerous samples, and each family of malware is considered independently within the framework of a separate rule. The verdict on it does not affect others. In turn, an ML solution represents a generalized model and learns to separate clean samples from dirty ones.
In our expert base, a significant imbalance was detected at the initial stages: for every two malicious samples, there was one clean sample. According to other estimates, the ratio was even three to one. However, in real traffic flowing into the sandbox, the data is mostly clean, and illegitimate sessions appear in only 1% of all PCAP files. In this case, due to the characteristics of the models and the environment in which they operate, there is a slight imbalance (but this should be taken into account when developing the model) — after all, most of the clean traffic in the sandbox is homogeneous, while malicious traffic is more variable. Such a statement would be completely incorrect for stream traffic, but here we are reasoning specifically about the sandbox network.
It was certainly not possible to release our model into production in this form.
Continuous Learning
Data labeling for our model includes rule verdicts (95% of cases) and manual expertise. This means that a classic ML approach doesn't work here: if the model overfits to the rules, it won't be useful. In this case, we're particularly interested in evaluating false positives — specifically, the situations where the model detects illegitimate activity that isn't covered by the existing labels.
False positive detections may indicate two things: either the model has truly found something unique, or a safe sample was mistakenly identified as malicious by the model. In the case of the sandbox, the second option cannot be allowed: it will mark the file as dangerous, which will mislead the user.
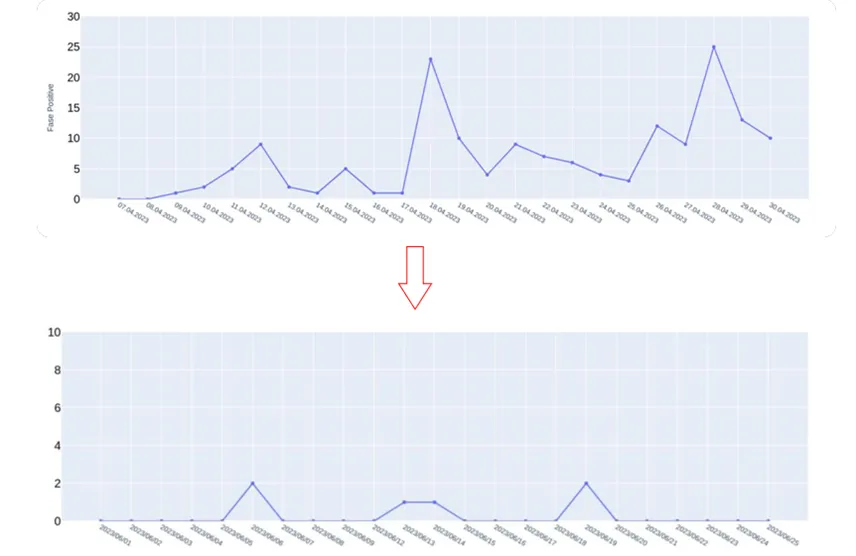
At the same time, new families of malware constantly emerge in real data streams. Therefore, to keep the model effective, it needs constant monitoring and retraining. For this, we have established a separate process: experts analyze false positives daily, and we make adjustments to the model when necessary.
Initially, we observed regular spikes in false positive detections, some of which were due to model errors. However, at this stage, we also discovered many families of malware that researchers had not previously described with rules. After just a week, the number of such detections decreased: mostly unique detections remained. The training of the ML model is still ongoing, as this is the only way to maintain its relevance.
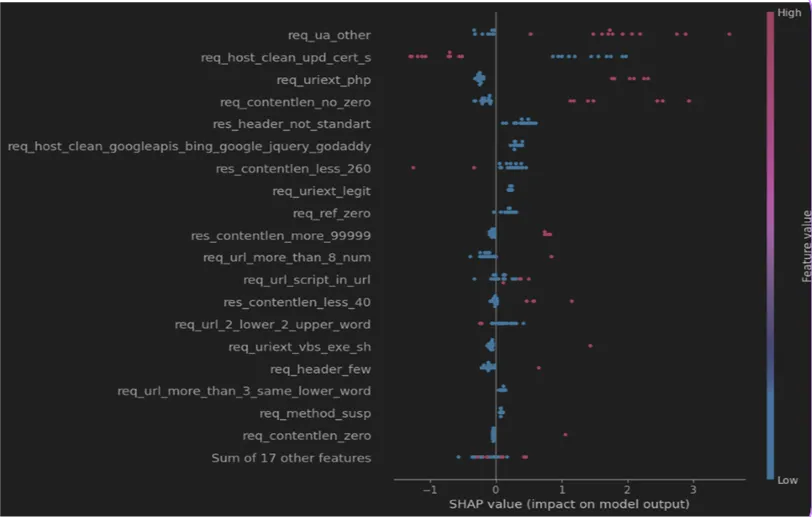
Interpretation of Verdicts
To make the model's verdicts transparent and explainable, we used the SHAP library, which builds visual graphs explaining the model's decisions. Movement along the horizontal axis to the left indicates that the traffic is clean, while movement to the right indicates the detection of malware. Red color indicates a high feature value, while blue indicates a low value. With such a graph, cybersecurity specialists using the sandbox can much more easily understand why the model made a particular conclusion.
How ML Works in Practice
To explain how our ML model detects malware in network traffic, we will show the results of four experiments. In them, we passed the same traffic through the PT Sandbox and the ML model to compare the effectiveness of threat detection. The first two examples refer to the early stages of the model’s development, while the others are from after its improvement. If you want to dive into the theoretical aspects of the issue, read the article by our colleague Igor Kabanov.
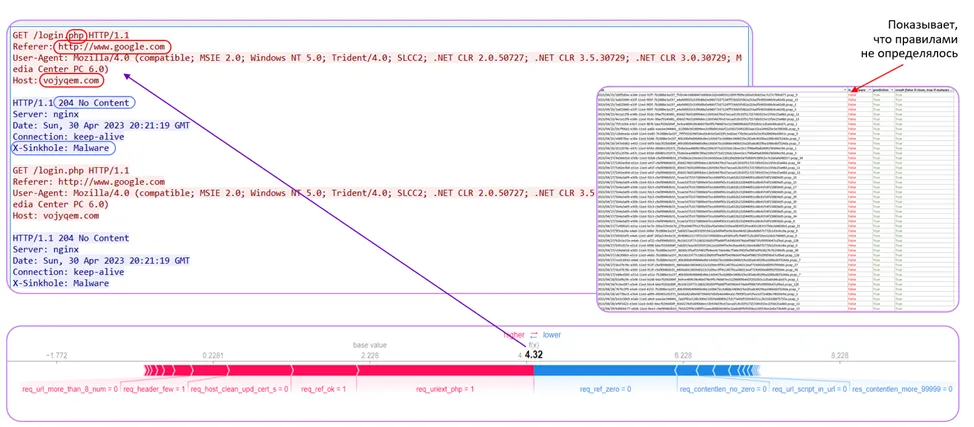
In one of the first experiments, the ML model detected the previously undetected Botnet Lymysan family in the “sandboxed” traffic, which had not been documented by network rules. The screenshot shows a session from Wireshark. The model noticed a request to a PHP file in a GET request. Then it drew attention to the fact that the Referer header indicated google.com, but the redirection came from another node. The User-Agent header was also suspicious — an outdated Mozilla 4.0, which is no longer used by legitimate resources. The response shows a 204 No Content server response, and the X-Sinkhole: Malware header is clearly visible. The model signaled the presence of malware and was correct.
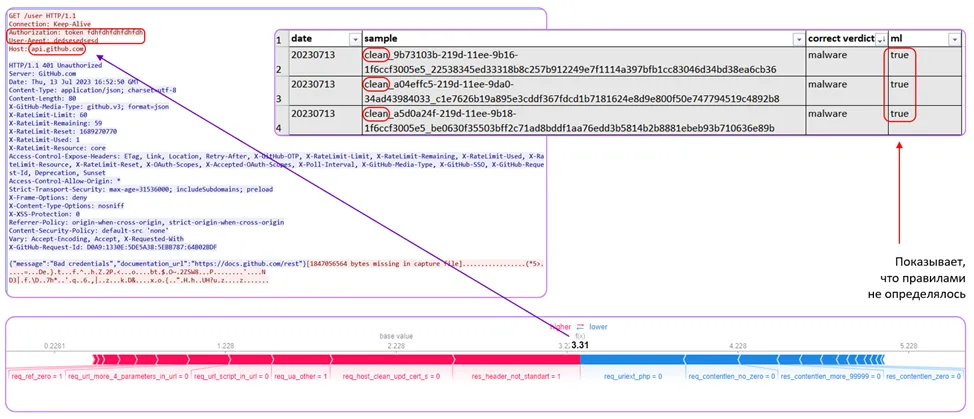
Another interesting example is the detection of the Backdoor C3 configuration file, which also had not been described or detected by our rules. Note that in the GET request, the Authorization header’s token parameter repeats the letters fdh, while the request is made to the api.github.com node. By comparing the correlation, the ML solution also detected the malware.
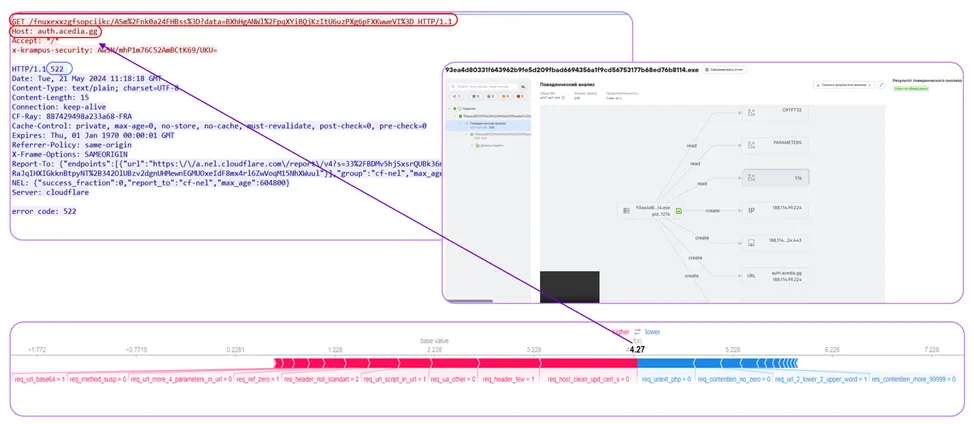
In one of the more recent examples, the model noticed a long GET request with multiple repetitions of the same characters, an appeal to a node with a suspicious gg domain zone, as well as a small number of headers, an unusual x-krampus-security header specified by the client in lowercase, and a 522 response from the server. Based on the cumulative count of these signs, the model indicates that this is malware.
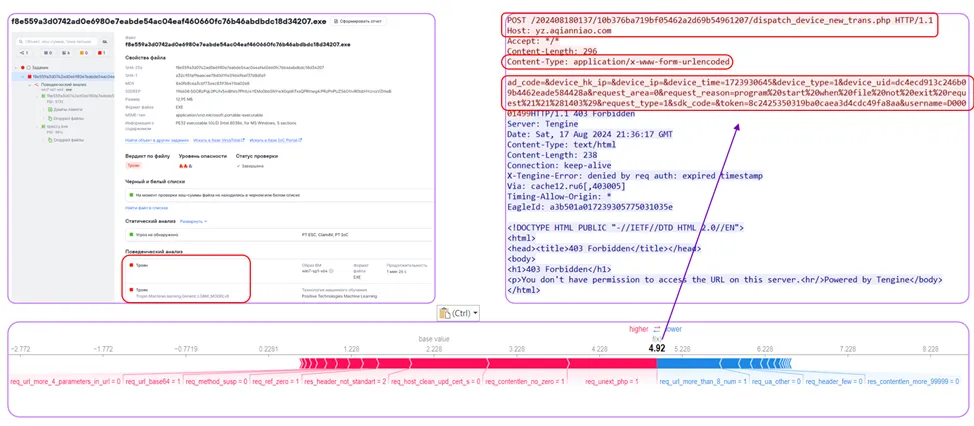
In the last example, a number of suspicious signs can also be highlighted: a POST request with .php, a suspicious Host, and system data transmitted in the request body. All this indicates malware. In this case, the sandbox also detects a trojan, but only in behavioral analysis.
As a result of these examples, it can be concluded that ML allows detecting new threats, so in practice ML will perfectly complement the current solution and improve the detection of new threats, which will expand the capabilities of PT Sandbox in detecting malware.
We don’t say goodbye, but rather — until the next implementations
Expert rules are indispensable in identifying known threats, that’s true. We often write general rules (so-called generics) that help us catch new malware, but such rules have limitations in terms of syntax and engine capabilities. In such cases, the ML solution comes to the rescue: thanks to the developed features, not all of which can be detected on the network using rule syntax, thanks to the ability to look at raw packets — new, unknown threats are detected. It will be quite a while before we can claim that we can do without network rules — the ML solution will not cover all malware, no matter how good the features are. But by working together with the rules already present in the product — it will perfectly complement them and highlight suspicious activity for our users.
We have tried to implement best practices to teach our model to detect malicious traffic as well as (and sometimes even better than) an experienced analyst, but its development does not end there, so we are not saying goodbye. See you in other articles, where we will talk about new features of our ML solutions!



Write comment