
- Security
- A
We hacked Google Gemini and downloaded its source code
In 2024, we released a post We Hacked Google A.I. for 50,000, which described how our group consisting of Roni “Lupin” Carta, Joseph “rez0” Tacker, and Justin “Rhynorater” Gardner went to Las Vegas in 2023 to search for vulnerabilities in Gemini at the Google event LLM bugSWAT. This year, we repeated our trip…
In 2024, we published a post We Hacked Google A.I. for $50,000, which talked about how our group consisting of Roni "Lupin" Carta (that's me), Joseph "rez0" Tecker, and Justin "Rhynorater" Gardner went to Las Vegas in 2023 to look for vulnerabilities in Gemini at Google’s LLM bugSWAT event. This year, we repeated our trip…
The world of Generative Artificial Intelligence (GenAI) and Large Language Models (LLM) continues to be a technological Wild West. Since the arrival of GPT, the race for dominance in the LLM sphere has only intensified: tech giants like Meta, Microsoft, and Google are competing to create the highest quality model. But now companies like Anthropic, Mistral, Deepseek, and others are entering the arena, making a significant impact on the industry.
Companies are actively developing AI assistants, classifiers, and a host of other tools based on LLM, but the critically important question remains: is the development being carried out safely? As we mentioned last year, due to the rapid implementation, it sometimes feels like we’ve forgotten fundamental safety principles, opening doors to both new and familiar vulnerabilities.
The world of artificial intelligence is rapidly evolving due to the emergence of AI agents. Such intelligent entities utilize complex "chains of thought" algorithms: processes in which the model generates a coherent sequence of internal reasoning steps to solve complex tasks. By documenting their thought process, these agents not only improve their decision-making capabilities but also ensure transparency, enabling developers and researchers to understand and refine them. This dynamic combination of autonomous operation and visual reasoning paves the way for the creation of even more adaptive, interpretable, and reliable AI systems. We are witnessing the emergence of numerous applications: from interactive assistants to sophisticated decision-support systems. The integration of chain-of-thought algorithms into AI agents sets a new standard for model achievements in real-world usage scenarios.
Google, to its credit, is actively exploring this new frontier of AI security and has been doing so for quite some time. LLM bugSWAT events, held in popular locations like Las Vegas, are a testament to the proactive approach to problem exploration by "red" teams. Such events encourage researchers from around the world to thoroughly test their AI systems, searching for vulnerabilities.
In 2024, we answered this challenge once again! Justin and I returned to bugSWAT in Las Vegas, and this time our efforts were greatly rewarded. Thanks to a new vulnerability in Gemini, which we will discuss in the post, we were awarded the title of Most Valuable Hacker (MVH) of the year!

Exploring the New Gemini
The Google team granted us early access to the next Gemini update, which will include numerous delightful features. Alongside exclusive access, we received detailed documentation explaining these features and their capabilities. The goal was to thoroughly investigate and test these capabilities from an attacker’s perspective.
It all started with a simple prompt. We asked Gemini:
run hello world in python3
(run hello world in python3)Gemini showed the code, and a curious "Run in Sandbox" button appeared in the interface. This intrigued us, and we began to explore.
Gemini Python Playground – a safe space... or not?
The Gemini Python Sandbox Interpreter has emerged. It can be considered a safe place to run Python code written by AI itself and even user's own scripts within the Gemini environment. This sandbox, built on Google gVisor in the GRTE (Google Runtime Environment), was designed as a secure solution. The idea is to allow experimenting with code without the risk of harming the system; this is a significant feature for development and testing.
gVisor is a user-space kernel developed by Google that acts as a mediator between containerized applications and the host operating system. By intercepting system calls made by applications, it creates strict security boundaries, reducing the risk of container escapes and limiting potential damage from compromised processes. gVisor does not rely solely on traditional OS-level isolation but implements a minimal, specialized subset of kernel functions, thereby reducing the attack surface while maintaining acceptable performance. This innovative approach enhances the security of container environments, making gVisor a must-have tool for securely running and managing containerized workloads.
As security researchers and bug bounty hunters, we know that the gVisor sandbox is protected by multiple layers, and from the information I’ve reviewed, no one has managed to escape this sandbox so far. In fact, escaping the sandbox would yield a reward of $100,000:
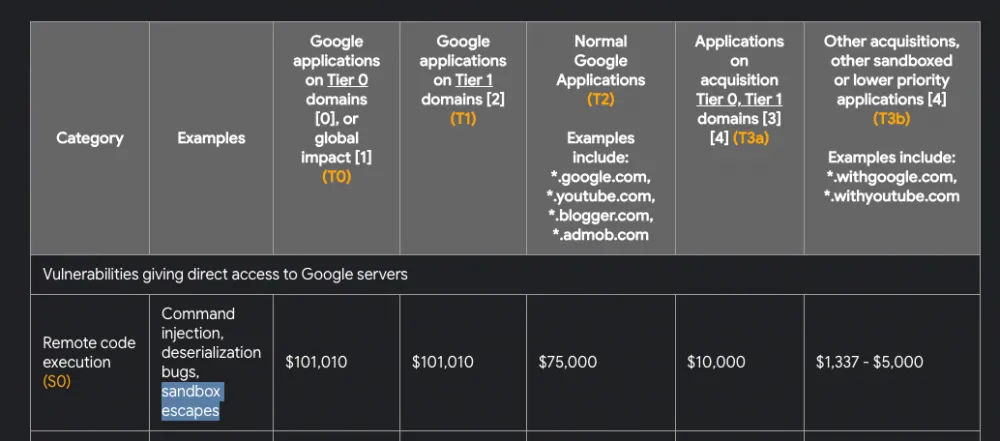
While escaping from it is possible, it's an entirely different challenge.
However, it is not always necessary to escape the sandbox, as in many cases there are elements inside it that allow for data leakage. A member of the Google security team gave us this idea: to try to access the shell from inside the sandbox itself to look for data that should not be accessible. The main problem was the following: this sandbox can only be executed in a specially compiled Python binary.
Marking the territory
First of all, we saw that the frontend code could be completely rewritten in Python and we could run our arbitrary version of the sandbox. Initially, we needed to understand the structure of this sandbox. We suspected that there might be interesting files hidden inside. Since we could not run the shell, we checked which libraries were in this compiled Python binary. It turned out that there is os! Great, we can use it to explore the file system.
We wrote the following code in Python:
import os
def get_size_formatted(size_in_bytes):
if size_in_bytes >= 1024 ** 3:
size = size_in_bytes / (1024 ** 3)
unit = "Go"
elif size_in_bytes >= 1024 ** 2:
size = size_in_bytes / (1024 ** 2)
unit = "Mb"
else:
size = size_in_bytes / 1024
unit = "Ko"
return f"{size:.2f} {unit}"
def lslR(path):
try:
# Determine if the path is a folder or a file
if os.path.isdir(path):
type_flag = 'd'
total_size = sum(os.path.getsize(os.path.join(path, f)) for f in os.listdir(path))
else:
type_flag = 'f'
total_size = os.path.getsize(path)
size_formatted = get_size_formatted(total_size)
# Check read and write permissions
read_flag = 'r' if os.access(path, os.R_OK) else '-'
write_flag = 'w' if os.access(path, os.W_OK) else '-'
# Output type, permissions, size, and path
print(f"{type_flag}{read_flag}{write_flag} - {size_formatted} - {path}")
# If it's a folder, recursively output its contents
if type_flag == 'd':
for entry in os.listdir(path):
entry_path = os.path.join(path, entry)
lslR(entry_path)
except PermissionError:
print(f"d-- - 0Ko - {path} (PermissionError: cannot access)")
except Exception as e:
print(f"--- - 0Ko - {path} (Error: {e})")The purpose of this code is to create a recursive function to list files and folders to find out which files are present, their size, and permissions.
We used the function to get the list of the folder lslR("/usr").
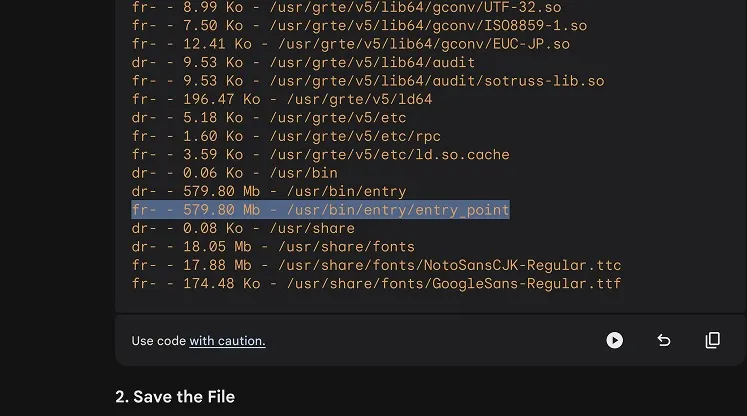
Thanks to this call, we were able to find a binary file located at /usr/bin/entry/entry_point. Sounds interesting!
Leak of the entry_point file
The next step was to extract this file, but it's 579 MB in size, so directly encoding it in base64 and sending it to the frontend would be impossible: the whole sandbox would freeze and eventually time out.
We tried to check if TCP, HTTP, and DNS calls could be made to extract information. Interestingly, our attempts to establish outgoing connections failed, and the sandbox seemed to be completely isolated from the external network. We had an interesting question: if the sandbox is so isolated that it cannot make external calls, how does it interact with Google services like Google Flights? Well... maybe we'll find out the answer later.
So, we needed to extract this binary file by printing it to the console in chunks, for which we used the seek() function, allowing us to navigate through the binary file and extract it in full blocks of 10 MB.
import os
import base64
def read_and_encode(file_path, kilobytes):
try:
# Calculate the number of bytes to read
num_bytes = kilobytes * 1024
# Open the file and read the specified number of bytes
with open(file_path, 'rb') as file:
file_content = file.read(num_bytes)
# Encode bytes in Base64
encoded_content = base64.b64encode(file_content)
# Print the encoded string
print(encoded_content.decode('utf-8'))
except FileNotFoundError:
print(f"FileNotFoundError: {file_path} does not exist")
except PermissionError:
print(f"PermissionError: Cannot access {file_path}")
except Exception as e:
print(f"Error: {e}")
read_and_encode("/usr/bin/entry/entry_point", 10000)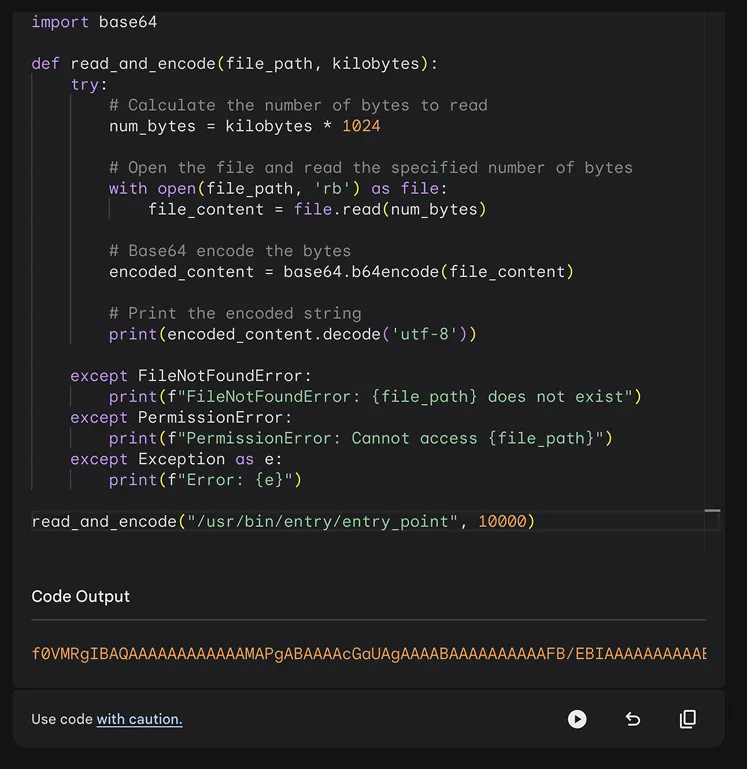
Then we used Caido to intercept the request in our proxy, which was supposed to call the sandbox, get the result, and then send it to the Automate function. The Automate function allows sending requests in batches. This way, we can flexibly initiate brute force/fuzzing to quickly change individual request parameters using wordlists.
Note from Lupin: Judging by the description, it seems our path was straightforward, but in reality, it took us many hours to reach this stage. Justin and I were hacking at three in the morning, and while Justin was extracting the binary file with Caido, I had already fallen asleep on my keyboard.
After receiving the blocks in base64 encoding, we recreated the entire file locally and were ready to start exploring its content.
How to read this file?
File command?
The file command, run on the binary file, identified it as a binary file: 64-bit ELF LSB shared object, x86-64, version 1 (SYSV), with dynamic linking, interpreter /usr/grte/v5/lib64/ld-linux-x86-64.so.2 In other words, it is indeed a binary file. Hmm, what can be done with this?
Strings command?
The output of the strings command was particularly intriguing due to numerous references to Google's internal repository google3. This gave us a hint about the existence of internal data paths and code blocks not intended for external disclosure, clearly indicating the presence of traces of proprietary Google software in the binary file. But does this have any implications for security?
Binwalk!
The real breakthrough happened when using Binwalk. This tool was able to extract the complete file structure from the binary file, allowing us to see the complex contents of the sandbox. The extraction revealed many folders and files, giving us a detailed picture of the internal architecture and uncovering components that shocked us.
Wait… is this internal source code?
While examining the data generated by our binwalk analysis, we unexpectedly discovered internal source code. The extraction revealed entire folders of proprietary Google source code. But is it confidential?
Google3 folder with Python code
In the folder extracted by binwalk, we were able to find a google3 folder containing the following files:
total 2160
drwxr-xr-x 14 lupin staff 448B Aug 7 06:17 .
drwxr-xr-x 231 lupin staff 7.2K Aug 7 18:31 ..
-r-xr-xr-x 1 lupin staff 1.1M Jan 1 1980 __init__.py
drwxr-xr-x 5 lupin staff 160B Aug 7 06:17 _solib__third_Uparty_Scrosstool_Sv18_Sstable_Ccc-compiler-k8-llvm
drwxr-xr-x 4 lupin staff 128B Aug 7 06:17 assistant
drwxr-xr-x 4 lupin staff 128B Aug 7 06:17 base
drwxr-xr-x 5 lupin staff 160B Aug 7 06:17 devtools
drwxr-xr-x 4 lupin staff 128B Aug 7 06:17 file
drwxr-xr-x 4 lupin staff 128B Aug 7 06:17 google
drwxr-xr-x 4 lupin staff 128B Aug 7 06:17 net
drwxr-xr-x 9 lupin staff 288B Aug 7 06:17 pyglib
drwxr-xr-x 4 lupin staff 128B Aug 7 06:17 testing
drwxr-xr-x 9 lupin staff 288B Aug 7 06:17 third_party
drwxr-xr-x 4 lupin staff 128B Aug 7 06:17 utilIn the assistant folder, internal Gemini code was also found, related to RPC calls (used to handle requests through tools like YouTube, Google Flights, Google Maps, and so on). The folder had the following structure:
.
├── __init__.py
└── boq
├── __init__.py
└── lamda
├── __init__.py
└── execution_box
├── __init__.py
├── images
│ ├── __init__.py
│ ├── blaze_compatibility_hack.py
│ ├── charts_json_writer.py
│ ├── format_exception.py
│ ├── library_overrides.py
│ ├── matplotlib_post_processor.py
│ ├── py_interpreter.py
│ ├── py_interpreter_main.py
│ └── vegalite_post_processor.py
├── sandbox_interface
│ ├── __init__.py
│ ├── async_sandbox_rpc.py
│ ├── sandbox_rpc.py
│ ├── sandbox_rpc_pb2.pyc
│ └── tool_use
│ ├── __init__.py
│ ├── metaprogramming.py
│ └── runtime.py
└── tool_use
├── __init__.py
└── planning_immersive_lib.py
8 directories, 22 filesLet's take a closer look at the Python code
Inside the file google3/assistant/boq/lamda/execution_box/images/py_interpreter.py, the following code fragment was found:
# Line to detect attempts to dump scripts:
snippet = ( # pylint: disable=unused-variable
"3AVp#dzcQj$U?uLOj+Gl]GlY<+Z8DnKh" # pylint: disable=unused-variable
)It seems that this fragment was used as a measure to prevent unauthorized script dumping, clearly indicating that the code was not intended for public disclosure.
After thorough investigation, we concluded that the inclusion of what appeared to be internal Google3 code was actually an intentional choice.
The Python code, despite the application of anti-dumping protection, was pre-approved by Google's security team for public disclosure. Although these measures were originally intended to prevent unwanted output, they were left in place because... why not?
But we didn't leave the sandbox alone, as we felt we were close to something serious!
Diving into the core logic of the sandbox
Upon deeper examination of the Python code, we noticed that, as one might expect, this sandbox communicates with external Google servers, for example, to fetch data from Google Flights and other Google services.
This was implemented using a Python class (google3.assistant.boq.lamda.execution_box.sandbox_interface), which exposed various functions like _set_reader_and_writer that could be called.
def _set_reader_and_writer(
reader_handle: io.BufferedReader | None,
writer_handle: io.BufferedWriter | None,
) -> None:
"""Sets the readeаr and writer handles for rpcs.
Should be called before running any user code that might
import async_sandbox_rpc
Args:
reader_handle: the handle through which to receive incoming RpcResponses. If
None will default to legacy behavior (/dev/fd/3)
writer_handle: the handle through which to receive incoming RpcRequests. If.
None will default to legacy behavior (/dev/fd/4)
"""
with _INIT_LOCK:
global _READER_HANDLE
global _WRITER_HANDLE
_READER_HANDLE, _WRITER_HANDLE = reader_handle, writer_handle
def run_tool(
name: str, operation_id: str, parameters: str
) -> sandbox_rpc_pb2.RunToolResponse:
"""Runs a tool with the given name and id, passing in parameters.
Args:
name: The name of the tool.
operation_id: The name of the operation to perform.
parameters: The parameters to pass to the tool.
Returns:
A RunToolResponse containing the response from the tool.
"""
result = make_rpc(
sandbox_rpc_pb2.RpcRequest(
run_tool_request=sandbox_rpc_pb2.RunToolRequest(
name=name, operation_id=operation_id, parameters=parameters
)
)
)
if result and result.HasField("run_tool_response"):
return result.run_tool_response
else:
return sandbox_rpc_pb2.RunToolResponse(response="")
We can pass various data blocks to these functions, which will serialize the data into a protobuf-compatible format and then invoke RPC, writing to the local file descriptor 5. The response can then be considered as reading from the local file descriptor 7. By using the proto found in the massive binary file, we were able to create incoming and outgoing RPC server messages, as well as directly invoke these Google tools.
However, we discovered something interesting: not all sandboxes had the same list of Google services available. This depended on who created the sandbox: the frontend capable of executing Python source code or the Google Agent. What does this mean?
Research Paper on ReAct
Before proceeding with further explanations, it should be mentioned that the Google team showed us the following research paper, which formed the basis for Gemini:
This paper presents a new (at the time of publication) approach: language models alternately generate reasoning paths and perform specific actions, essentially intertwining their thoughts and behavior. In practice, this means that during the process of thinking about a task, the model creates a transparent trail of reasoning, allowing it to plan, track, and regulate its actions, while interacting with external sources for additional data when necessary. This dynamic interaction not only improves the model’s accuracy by eliminating frequent issues (such as hallucinations and error propagation) but also makes the decision-making process more interpretable and controllable for human operators.
By integrating both internal reasoning and external knowledge, ReAct creates a flexible generalized framework that excels at a wide range of tasks, from answering questions and fact-checking to text-based games and web navigation. Essentially, ReAct leverages both reasoning and acting strengths, providing more reliable, user-friendly, and versatile language models.

Alright, but why do we need to understand this? Well, following the logic of the paper, Gemini may repeatedly send prompts to itself to improve commands and ensure the correct chain of reasoning.
If a user asks: “When is the next flight from Toronto to New York?”, the chain of reasoning for Gemini would look something like this:
-
The user asks me to look for the nearest flight between Toronto and New York
-
We create the following plan:
-
I need to run Python code that connects to the Google Flights tool
-
The code should find all flights from the current date until next week between the airports YYZ and JFK
-
The code should sort the flights by date and take the first one
-
-
After the plan is completed, it will generate the code using the tools available to Agent
-
After generating the code, it will create a sandbox with the appropriate privileges (e.g., with access to the Google Flights tool via a file descriptor)
-
It will execute the code, process the output
-
It will generate a response to the user
Our theory was as follows:
-
What if we can perform secondary prompt injection during the planning stage of Gemini to gain access to a more privileged sandbox?
With the help of Google's security team, we tested this idea and noticed that with certain generative parameters and temperature (these are common probabilistic nuances of LLMs), we can sometimes gain access to something resembling a more privileged sandbox.
By this, we mean that an attacker could gain access to extensions via two new file descriptors. These file descriptors are always present but do not always perform active listening; when the agent calls the sandbox, they monitor extension (Google service) calls so that we can interact with the API, but when accessed from the Python interpreter, these extensions remain inaccessible.
As a result, we concluded that there is a real potential vulnerability P0: there is a specific message handler that may allow reading files within Google's internal infrastructure, and we hoped that the sandbox with an extension to work with the tool could initiate an RPC call to this specific tool. Given the probabilistic nature of the attack, which complicated its stable reproduction, we asked Google's security team to assess the situation. In the end, they found that the suspicious message handler is not accessible via RPC and can only be called from the outside.

Although we were limited in tests, the main idea in further research had real potential. Executing code in the context of a sandbox should not provide additional capabilities; it is considered unreliable, security checks are performed outside the sandbox, and every tool call is filtered. The inability to run code gave us convenient advantages:
-
Reliability: once we can execute code, the execution of actions will be more stable.
-
Chains/complexity: controlling many different tools or performing fine-tuning of parameters with regular text is difficult; executing code will allow us to create more complex chains even with protective measures in place.
-
Poisoning the output of tools: we will be able to manipulate the output of tools more effectively.
-
Leaks: there may be other hidden parts of the environment that, when discovered, could give us additional advantages.
This shows that our idea still has prospects for further escalation. And due to the potential for leaks, we decided to at least test this theory...
We found our leak
Upon deeper investigation, we found many ways to implement a leak of proto files. Proto files (short for Protocol Buffer) are the "blueprints" of data that define how messages will be structured and how data exchange will occur between different parts of the system. At first glance, they may seem harmless, but leaking these files can provide us with more detailed information about Google's internal infrastructure.
Revealing classification.proto
It turned out that by executing a command like:
strings entry_point > stringsoutput.txtand then searching the resulting file for "Dogfood", one can extract blocks of internal proto. Parts of the extracted content are included in the descriptions of the metadata of highly confidential proto. They themselves did not contain user data, but these are internal categories that Google uses for classification of user data.
For legal reasons, we cannot show the result of executing this command.
Why were we specifically looking for the string "Dogfood"? In Google, "dogfooding" refers to the practice of using pre-release versions of products and prototypes within the company for testing and refining them before public release. This allows developers to test deployment and potential issues in these products before going to production.
Moreover, we discovered an exposed file privacy/data_governance/attributes/proto/classification.proto, which detailed the method of data classification at Google. Although the file contains references to relevant documentation, these documents remain highly confidential and should not be publicly accessible.
Another note from Lupin: we discovered this the day after our overnight extraction of the binary file. We were in a rented Google hotel room and, along with the security team, were figuring out what we had found. This time, Justin was sleeping on the couch! We had been searching for this bug for so long, but it was totally worth it!
Disclosure of Internal Security Proto Definitions
In the same output, we also found numerous internal proto files that were supposed to remain hidden. By executing the command
cat stringsoutput.txt| grep '\.proto' | grep 'security'we obtained a list of many confidential files, including:
security/thinmint/proto/core/thinmint_core.proto
security/thinmint/proto/thinmint.proto
security/credentials/proto/authenticator.proto
security/data_access/proto/standard_dat_scope.proto
security/loas/l2/proto/credstype.proto
security/credentials/proto/end_user_credentials.proto
security/loas/l2/proto/usertype.proto
security/credentials/proto/iam_request_attributes.proto
security/util/proto/permission.proto
security/loas/l2/proto/common.proto
ops/security/sst/signalserver/proto/ss_data.proto
security/credentials/proto/data_access_token_scope.proto
security/loas/l2/proto/identity_types.proto
security/credentials/proto/principal.proto
security/loas/l2/proto/instance.proto
security/credentials/proto/justification.protoBy searching in the binary strings security/credentials/proto/authenticator.proto, we indeed confirmed that the data was exposed.
Why were these proto needed here?
As we mentioned earlier, the Google security team thoroughly examined everything in the sandbox and approved our publication. However, there was an automated step in the build pipeline for compiling the sandbox binary that added security proto files to the binary if it detected that they were required for applying internal rules.
In this case, this step was not mandatory and led to the unintended addition of highly confidential internal proto!
For us, bug bounty hunters, it is very important to deeply understand the business rules on which the company's processes are built. We reported these proto leaks because we knew that Google considers them highly confidential information and that they should never be disclosed. The more we understand the internal workings and priorities of our target, the better we are at identifying such subtle bugs that might otherwise slip under the radar. This deep knowledge not only allows us to discover vulnerabilities but also ensures that our reports meet the organization's security criteria.
Conclusion
Before concluding the post, I must say that it is vital to test such advanced AI systems before deploying them. There are so many interconnections and powerful capabilities that even a simple sandbox with access to various extensions can potentially lead to unpleasant surprises. We have personally seen that when all parts of the system work together, even small oversights can open up new sources of problems. In other words, thorough testing is not just recommended — it is the only way to ensure safety and proper functioning.
Ultimately, we had a great time during the process. Hacking vulnerabilities, uncovering hidden code, and expanding the capabilities of the Gemini sandbox were challenging, but at the same time, we really enjoyed this hunt.








Write comment