According to the tag o1, the following results have been found:

When LLMs first appeared, they were a bit like children - they said the first thing that came to their mind and didn't care much about logic. They needed to be reminded: "Think before you answer." Many argued that because of this, the models did not have real intelligence and that they needed to be supplemented either by human assistance or some kind of external framework on top of the LLM itself, such as Chain of Thought.
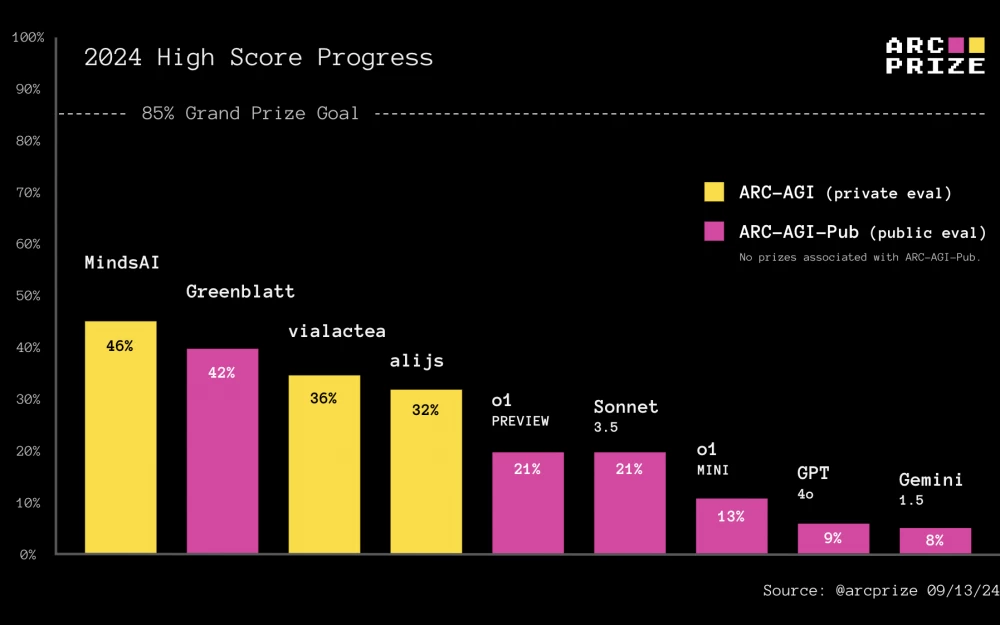
o1-previewIn the last 24 hours, we have gained access to the newly released OpenAI models, o1-mini specifically trained to emulate reasoning. These models are given additional time to generate and refine reasoning tokens before giving a final answer. Hundreds of people have asked how o1 looks on the ARC Prize. Therefore, we tested it using the same basic test system that we used to evaluate Claude 3.5 Sonnet, GPT-4o, and Gemini 1.5. Here are the results: