
- AI
- A
Thinking models o1-3: a brief overview and what programmers can expect next
When LLMs first appeared, they were a bit like children - they said the first thing that came to their mind and didn't care much about logic. They needed to be reminded: "Think before you answer." Many argued that because of this, the models did not have real intelligence and that they needed to be supplemented either by human assistance or some kind of external framework on top of the LLM itself, such as Chain of Thought.
It was only a matter of time before major LLM developers, such as OpenAI, decided to reproduce this external stage of thinking (see figure below) within the model itself. After all, it's quite simple: create a dataset containing not only "question-answer" pairs but also step-by-step reasoning logic, and train on it. In addition, more serious computational resources will be required during inference, as the model will go through the same step-by-step thinking process to determine the answer.
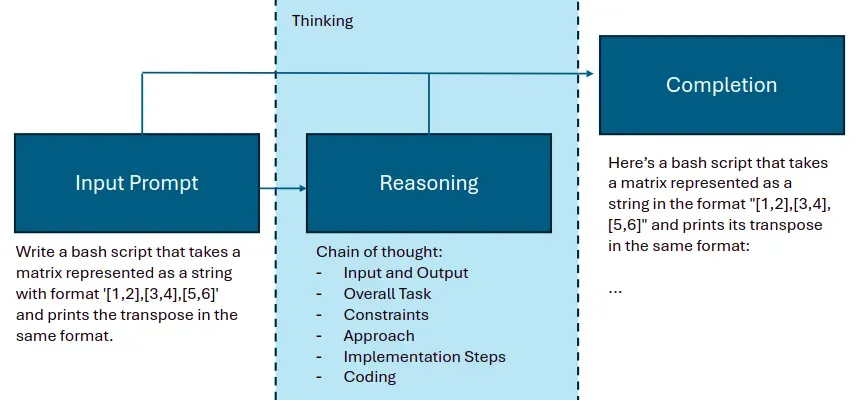
Added reasoning stage
Reasoning LLMs naturally break down problems into smaller parts and use the "chain of thought" approach, error correction, and try several strategies before answering.
O1 takes more time to respond (30 times slower than Gpt4o), and more time spent thinking leads to better results! (who would have thought)
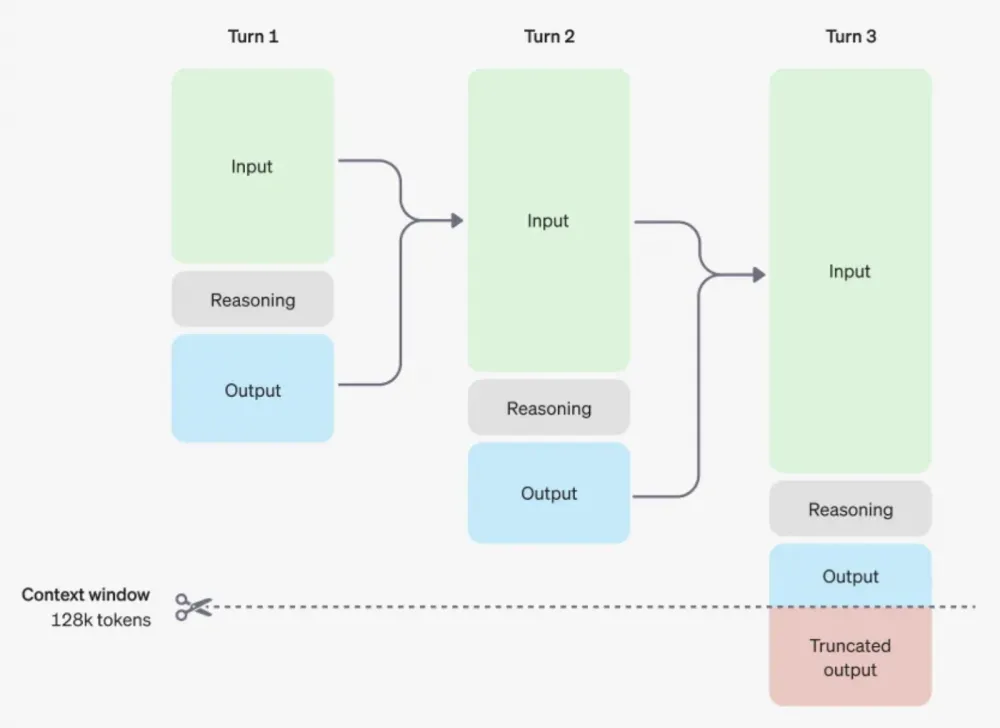
Reasoning tokens are not passed from one step to the next. Only the result is passed.
In addition, the solution is checked by generating several answer options and choosing the best one through consensus - an approach we previously implemented manually. Here is the overall process:
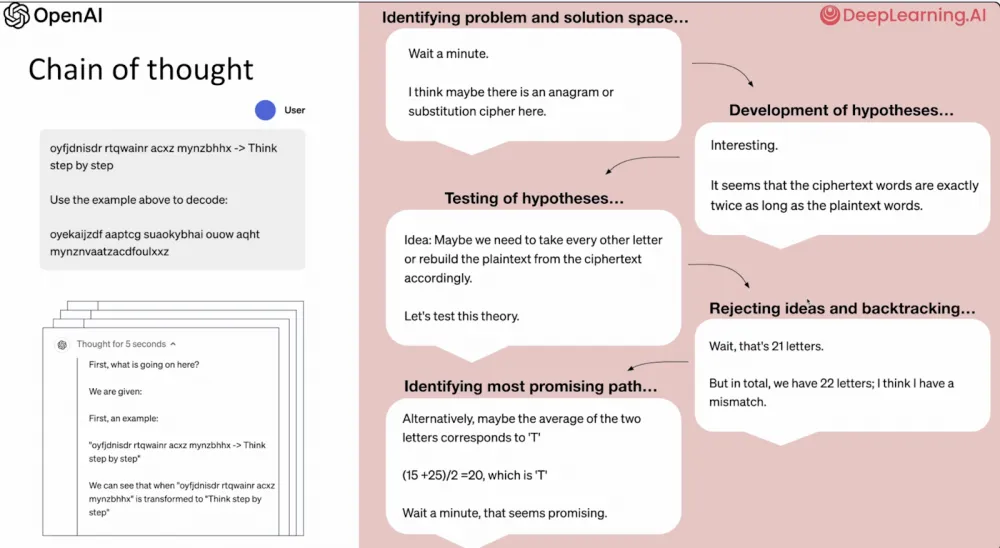
One of the important conclusions is that the requirements for computing resources (GPU) will grow, as it is obvious that longer "thinking" (more tokens for thinking) leads to better answers. This means that the quality of the model can be improved simply by allocating more computing power to it, whereas previously this mainly concerned only the training phase. Thus, the GPU requirements for modern models will increase significantly.
These models are fundamentally different from the old ones, and the old approaches no longer work.
How to work with models using reasoning
Interestingly, this is very similar to working with a smart person:
Be simple and speak directly. Clearly formulate your question.
Do not give Chain of Thought explicitly. The model will perform it internally.
Maintain structure: break the request into logical sections, use clear markup.
Show instead of explaining: it is better to give an example of a good answer or behavior than to describe it in thousands of words.
There is no need to persuade, intimidate, or try to bribe the model with meaningless techniques anymore.
This can be reduced to one point: know what you want to ask and formulate it clearly
Mini-models and full-fledged models
Since reasoning models (e.g., o3) consume a lot of tokens during inference, using them for everything turns out to be too expensive, and the response time is long. Therefore, the idea arose to delegate the most complex task - high-level thinking and planning - to the "big" model, and to use faster and cheaper mini-models to execute the plan. They can be used to solve tasks such as programming, mathematics, and science.
This is an "agent" approach that combines the best of both worlds: "smart but expensive" models plus "small and fast" performers.
How much better are these models?
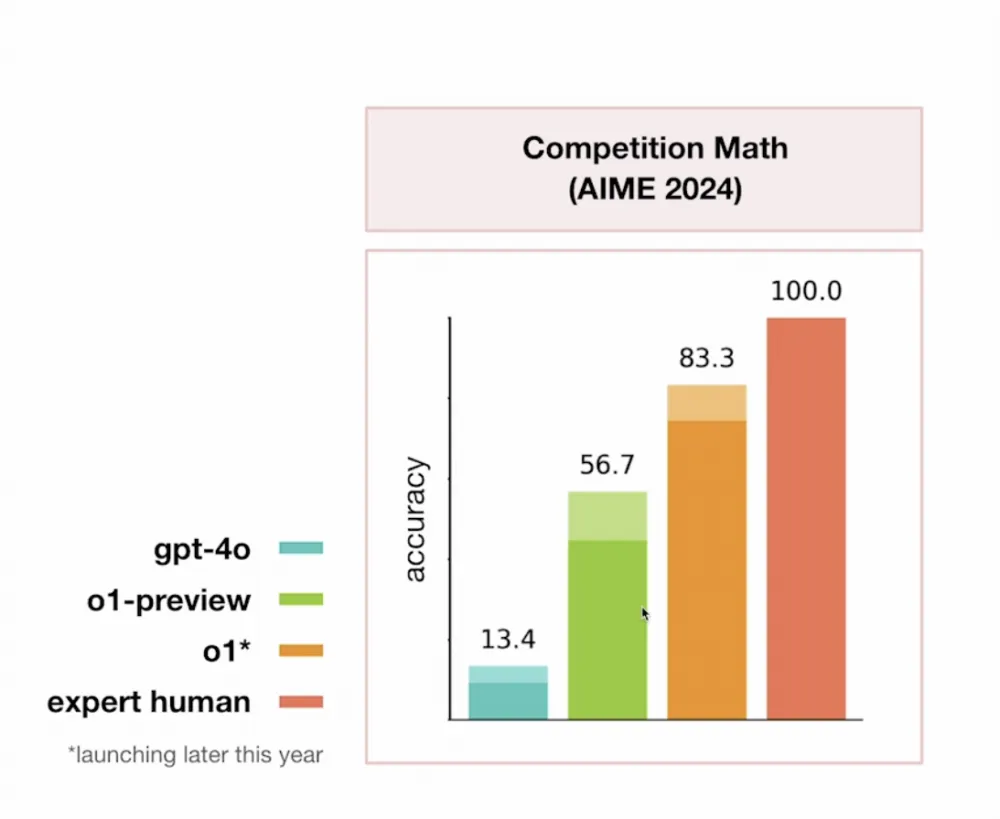
They are significantly better, and will become even better in the near future. For example, o1-3 are already approaching expert level in mathematics and programming (see below).
Mathematics
Code
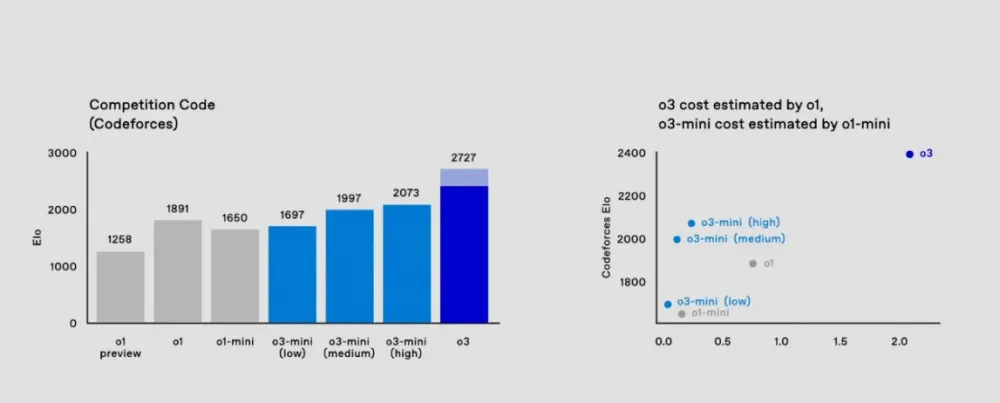
ELO 2727 puts o3 in the top 200 programmers in the world. If you are not yet worried about your job as a developer, it's time to start. This field scales excellently due to increased computing power, and the current pace of progress shows no signs of slowing down.
What's next
I can only speculate, but in my opinion, in the next year or two, it will be possible to significantly improve the quality of models simply by adding more computing resources at the inference stage and improving training datasets. Adding some kind of "memory" beyond the context window also seems like a logical step, although extremely expensive to implement on a large scale.
I believe that the next major step will be the implementation of a multi-agent architecture at the LLM level, so that the model can conduct several internal "collaborative" dialogues, sharing a single memory and context. This corresponds to the current trend of integrating external tools for "thinking" directly into the model and also provides benefits due to the linear scaling of computing resources at the training and inference stages. I think that by the end of this year or next year we will already see LMM (Large Multiagent Model) or something similar. The main thing is that they do not start schizophrenia.









Write comment