- AI
- A
OpenAI on new AI models that can reason
OpenAI's o1 series models are new large language models trained with reinforcement to perform complex reasoning. The o1 models think before answering and can create a long internal chain of reasoning before responding to the user.
o1 models excel at scientific reasoning, ranking in the 89th percentile on competitive programming questions (Codeforces), placing among the top 500 students in the USA in the qualifying round of the USA Mathematical Olympiad (AIME), and exceeding human PhD-level accuracy on physics, biology, and chemistry tasks (GPQA).
Two reasoning-capable models are available in the API:
o1-preview: an early preview version of our o1 model designed for reasoning about complex problems using general world knowledge.
o1-mini: a faster and cheaper version of o1, particularly effective in coding, math, and science tasks where extensive general knowledge is not required.
o1 models show significant progress in reasoning, but they are not intended to replace GPT-4o in all use cases.
For applications requiring image input, function calling, or consistently fast response times, GPT-4o and GPT-4o mini models will still be the right choice. However, if you plan to develop applications requiring deep reasoning and designed for longer response times, o1 models may be an excellent choice. We can't wait to see what you create with them!
o1 models are currently in beta.
Access is restricted to 5th level developers (check your usage level here), with low rate limits (20 RPM). We are working on adding new features, increasing rate limits, and expanding access to more developers in the coming weeks.
Quick Start
Both o1-preview and o1-mini are available through the chat completions endpoint.
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="o1-preview",
messages=[
{
"role": "user",
"content": "Write a bash script that takes a matrix represented as a string with format '[1,2],[3,4],[5,6]' and prints the transpose in the same format."
}
]
)
print(response.choices[0].message.content)Depending on the amount of reasoning required by the model to solve the problem, these requests can take anywhere from a few seconds to a few minutes.
Beta Limitations
During the beta phase, many parameters of the Chat Completions API are not yet available. Specifically:
Modalities: only text, images are not supported.
Message Types: only user and assistant messages, system messages are not supported.
Streaming: not supported.
Tools: tools, function calls, and response format parameters are not supported.
Logprobs: not supported.
Other: temperature, top_p, and n are fixed at 1, while presence_penalty and frequency_penalty are fixed at 0.
Assistants and Batch: these models are not supported in the Assistants API and Batch API.
We will add support for some of these parameters in the coming weeks as we exit beta. Features such as multimodality and tool usage will be included in future o1 series models.
How Reasoning Works
The o1 models feature reasoning tokens. Models use them to "think," breaking down their understanding of the prompt and considering multiple approaches to formulating a response. After generating reasoning tokens, the model outputs the response in the form of visible completion tokens and discards the reasoning tokens from its context.
Here is an example of a multi-step interaction between a user and an assistant. Input and output tokens from each step are carried over, while reasoning tokens are discarded.
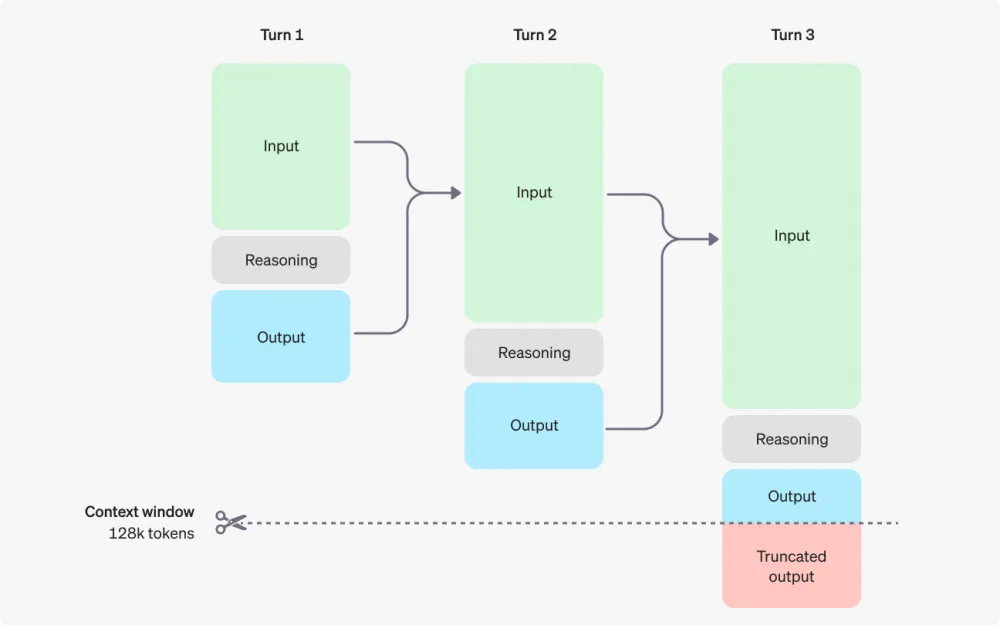
Although reasoning tokens are not visible through the API, they still occupy space in the model's context window and are called output tokens.
Managing the Context Window
The o1-preview and o1-mini models offer a context window of 128,000 tokens. Each completion has an upper limit on the maximum number of output tokens—this includes both invisible reasoning tokens and visible completion tokens. The maximum output token limits are as follows:
o1-preview: up to 32,768 tokens
o1-mini: up to 65,536 tokens
When creating completion tokens, it is important to ensure that there is enough space in the context window for reasoning tokens. Depending on the complexity of the task, models can generate from several hundred to tens of thousands of reasoning tokens. The exact number of reasoning tokens used can be seen in the usage object of the chat completion response object in the completion_tokens_details section:
usage: {
total_tokens: 1000,
prompt_tokens: 400,
completion_tokens: 600,
completion_tokens_details: {
reasoning_tokens: 500
}
}Cost Control
To manage costs in the o1 series models, you can limit the total number of tokens generated by the model (including reasoning and completion tokens) using the max_completion_tokens parameter.
In previous models, the max_tokens parameter controlled both the number of tokens generated and the number of tokens visible to the user, which were always equal. However, in the o1 series, the total number of generated tokens may exceed the number of visible tokens due to internal reasoning tokens.
Since some applications may rely on the max_tokens parameter matching the number of tokens received from the API, the o1 series introduces max_completion_tokens to explicitly control the total number of tokens generated by the model, including both reasoning and visible completion tokens. This explicit choice ensures that existing applications will not break when using the new models. The max_tokens parameter continues to work as before for all previous models.
Allocating Space for Reasoning
If the number of generated tokens reaches the limit of the context window or the value of max_completion_tokens set by you, you will receive a response about the completion of work in the chat with the finish_reason parameter set to length. This can happen before visible completion tokens are created, meaning you may incur input and reasoning costs without receiving a visible response.
To prevent this, make sure there is enough space in the context window, or change the max_completion_tokens value to a higher one. OpenAI recommends reserving at least 25,000 tokens for reasoning and conclusions when you start experimenting with these models. As you become familiar with the number of reasoning tokens required by your prompts, you can adjust this buffer accordingly.
Prompting Tips
These models work best with direct prompts. Some prompt engineering techniques, such as multi-frame prompts or instructing the model to "think step by step," not only do not improve performance but sometimes hinder it. Here are some best practices:
Keep prompts simple and straightforward: models understand and respond well to brief and clear instructions that do not require detailed specifications.
Avoid chain-of-thought prompts: since these models conduct reasoning internally, there is no need to prompt them to "think step by step" or "explain their reasoning".
Use delimiters for clarity: use delimiters such as triple quotes, XML tags, or section titles to clearly delineate different parts of the input, helping the model to correctly interpret the various sections.
Limit additional context in generation with extended search (RAG): when providing additional context or documents, include only the most important information so that the model does not overcomplicate its response.
Prompt Examples
Programming (refactoring)
OpenAI o1 series models are capable of implementing complex algorithms and producing code. In this task, o1 is asked to refactor a React component based on specific criteria.
from openai import OpenAI
client = OpenAI()
prompt = """
Instructions:
- Given the React component below, change it so that nonfiction books have red
text.
- Return only the code in your reply
- Do not include any additional formatting, such as markdown code blocks
- For formatting, use four space tabs, and do not allow any lines of code to
exceed 80 columns
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
{book.title}
);
return (
{listItems}
);
}
"""
response = client.chat.completions.create(
model="o1-mini",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
},
],
}
]
)
print(response.choices[0].message.content)Programming (planning)
Models of the OpenAI o1 series can also create multi-step plans. In this example, o1 asks to create a file system structure for a complete solution, as well as Python code that implements the desired use case.
from openai import OpenAI
client = OpenAI()
prompt = """
I want to build a Python app that takes user questions and looks them up in a
database where they are mapped to answers. If there is a close match, it retrieves
the matched answer. If there isn't, it asks the user to provide an answer and
stores the question/answer pair in the database. Make a plan for the directory
structure you'll need, then return each file in full. Only supply your reasoning
at the beginning and end, not throughout the code.
"""
response = client.chat.completions.create(
model="o1-preview",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
},
],
}
]
)
print(response.choices[0].message.content)STEM Research
Models of the OpenAI o1 series have shown excellent results in STEM research. Prompts requiring support for basic research tasks should show high results.
from openai import OpenAI
client = OpenAI()
prompt = """
What are three compounds we should consider investigating to advance research
into new antibiotics? Why should we consider them?
"""
response = client.chat.completions.create(
model="o1-preview",
messages=[
{
"role": "user",
"content": prompt
}
]
)
print(response.choices[0].message.content)Examples of usage
Some examples of using o1 in real situations can be found in the cookbook.









![From Virtual Hands to AI for Survivalists: Curious Open Agent OSes [and One Hardware Project]](https://cdn.tekkix.com/imgs/2026/05/habrcom/big/ce0b1057616faed51cd8b9f3b2b9.webp)
Write comment