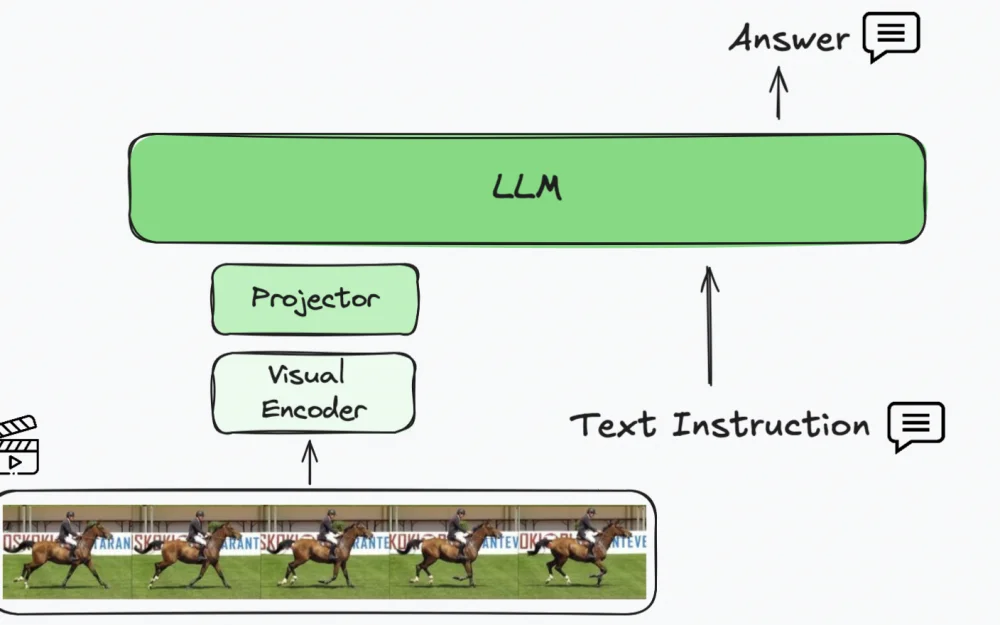
- AI
- A
How to teach LLM to understand video? Overview of approaches
Hello everyone! Today we will talk about the task of understanding video and the evolution of approaches to training multimodal large language models for this task.
Video Understanding Task
Video Understanding is a field at the intersection of computer vision (CV) and natural language processing (NLP), encompassing a variety of tasks for video perception and interpretation: from basic object and object recognition in video sequences, object localization in space or time, counting objects and people to generating brief or detailed video descriptions and reasoning tasks about the causes of events in the video, requiring a deep understanding of the world — from human psychology to the physical properties of objects.
The rapid development of Vision LLM (VLLM) — LLM with support for visual modalities — in 2023–2024 has significantly brought video understanding by neural networks closer to how humans do it. VLLMs are capable of answering a wide variety of questions about videos in natural language. Instructional training allows one model to solve many video understanding tasks, and the large amount of knowledge of LLMs and understanding of diverse contexts allow VLLMs to analyze video content and make complex inferences.
Flamingo
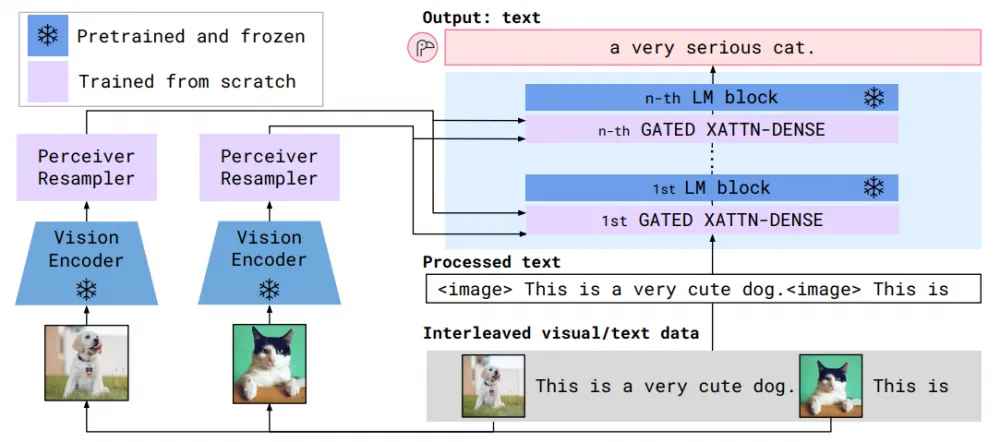
The first significant work dedicated to VLLM, Flamingo (NeurIPS 2022), contained many interesting ideas that were repeatedly reused in subsequent papers.
For example:
Using interleaved data for training, where image tokens can be in any part of the text prompt, not just at the beginning or end.
Freezing the Vision Encoder during the entire training.
Independent encoding of video frames (as images), but with the addition of learnable temporal embeddings to account for the temporal aspect.
Using Perceiver Resampler to convert visual embeddings of arbitrary length output from the Vision Encoder into a compact fixed-length representation (64 tokens) before feeding visual information into the LLM.
Next Token Prediction as a training task.
From what was rarely seen in subsequent works:
Normalizer-Free ResNet (NFNet) is used as the Vision Encoder.
Video frames are sampled very frequently (1 FPS).
The language model is frozen throughout the training. Instead, new learnable cross-attention layers are inserted between the LLM blocks to help convey visual information to the LLM.
Instead of generalizing the model to a large number of diverse image and video understanding tasks, the focus is on few-shot in-context learning, where all information about a new task and examples of its execution are given to the model directly in the text-visual prompt.
LLaVA
LLaVA (April 2023) and LLaVA 1.5 (October 2023) are VLLMs for image understanding, but without video support. The papers laid the architectural and code foundation, including for many subsequent papers on VLLMs for video understanding:
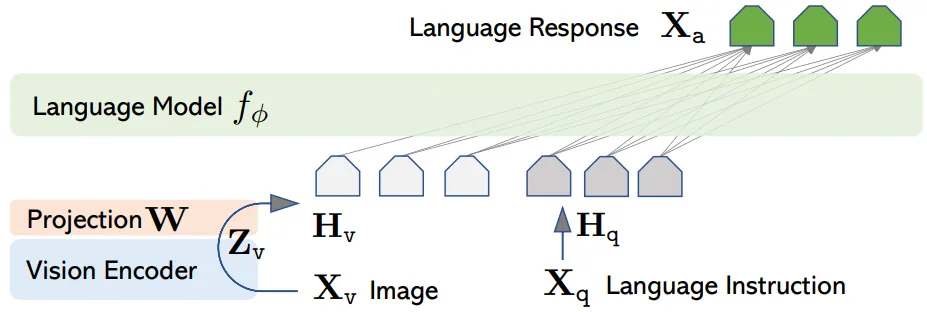
Architecturally, the model consists of a visual encoder based on CLIP, an MLP adapter (in the first version - a single linear layer) between the CLIP visual embedding space and the LLM, and a large language model.
Two-stage training: first, only the adapter is trained, then both the adapter and the LLM are trained.
In the first stage, the training data consists of simple tasks consisting of images and brief descriptions of them (image captioning task). In the second stage, more complex tasks are used, requiring detailed perception and analysis of images (various VQA - visual question answering options).
VideoChat, Video-ChatGPT, Valley
In May-June 2023, a whole series of works was released - VideoChat, Video-ChatGPT, Valley, - whose authors sought to "humanize" VLLM - to improve their functioning as chatbots or assistants. Each of the works proposes an approach to generating instructional dialogues for training, which allows LLM to learn to maintain a dialogue on video and answer various questions. In all three cases, the dialogues are generated using ChatGPT based on video descriptions.
For example, in Valley, three types of tasks are generated - "detailed description", "dialogue" and "complex reasoning". In addition, Valley uses:
two-stage training and basic architecture from LLaVA;
a common encoder for pictures and videos - CLIP with ViT-L/14 architecture;
a temporal module based on a single-layer transformer encoder and Average Pooling - for modeling the temporal variability of frames and aggregating video tokens that are sent to the LLM (initially, frames from the video are sampled at a frequency of 0.5 FPS).
Unlike Valley, in Video-ChatGPT:
the pre-trained image model from LLaVA is used;
Average Pooling is applied separately not only to all tokens within each frame (to model temporal variability), but also separately along the temporal dimension between corresponding frame tokens, to obtain averaged spatial features of the entire video.
An important innovation in Video-ChatGPT is the method proposed by the authors for evaluating the performance of VLLM on open-ended questions using GPT-3.5: the text LLM analyzes the model's prediction against the reference based on several criteria and assigns a score from 0 to 5. Later in Video-LLaVA, this approach was supplemented to simplify the calculation of accuracy: the model now returned not only a score from 1 to 5, but also a binary value: "yes" (correct answer) or "no" (incorrect answer).
Video-LLaMA
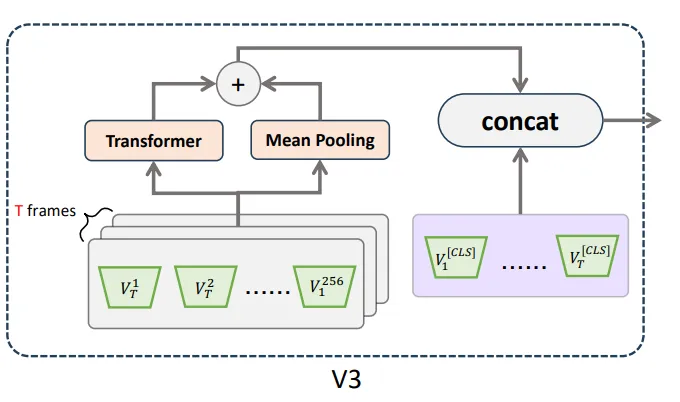
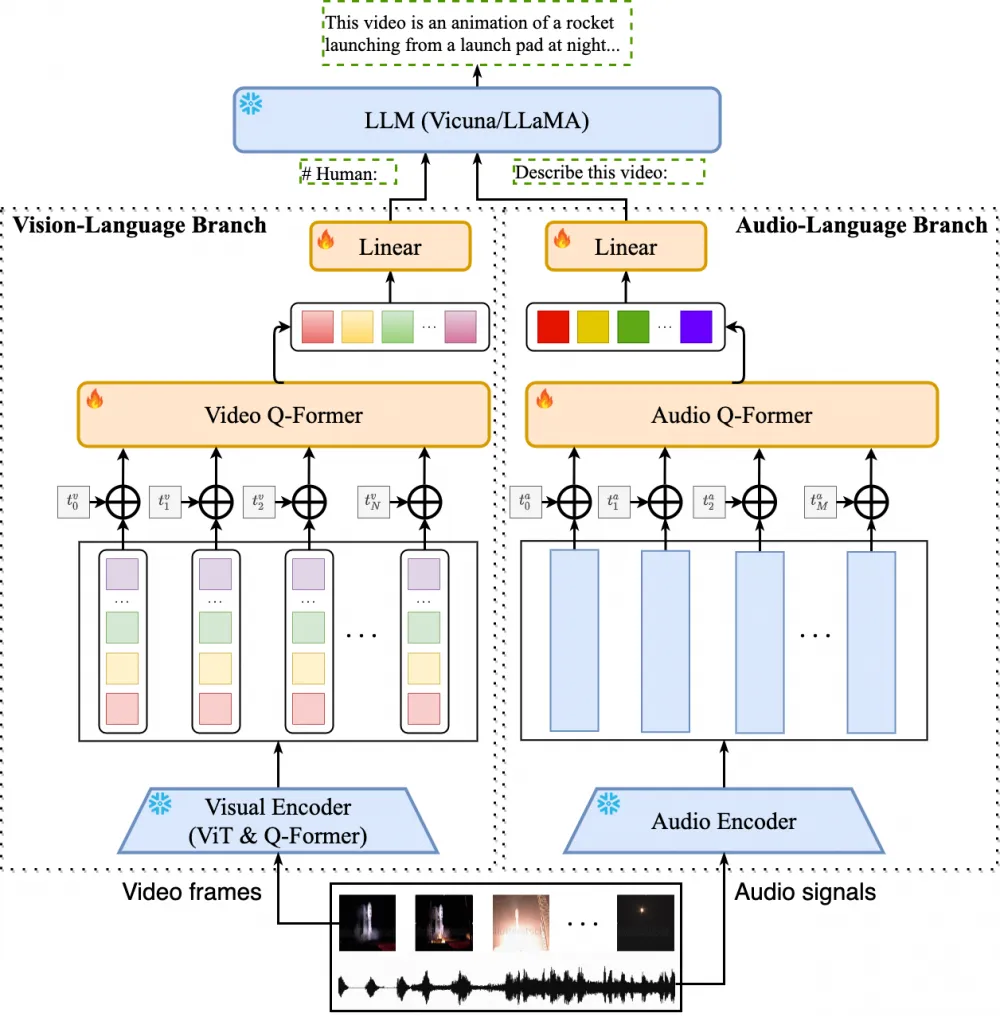
Video-LLaMA (June 2023) is the first VLLM with support for understanding both video and audio streams in video clips. As adapters between the video modality and LLM, the audio modality and LLM use a combination of Q-Former (from BLIP-2) and a linear layer. Interestingly, audio and video are processed independently at all stages except LLM.
Video-LLaVA
Video-LLaVA (November 2023) is perhaps the most significant of the early works on VLLM with support for video understanding due to its good generalization to various tasks and metrics, significantly surpassing previous approaches.
Video and image encoders from LanguageBind: trained through contrastive learning to encode images and videos into a common embedding space (allowing the use of a common MLP adapter for both modalities).
Uniform sampling of a fixed number of video frames, regardless of length — eliminates the need to use Perceiver Resampler or Q-Former to obtain a small fixed number of video tokens.
Reuse of LLaVA data (558k and 349k images, 558k and 624k dialogues in the first and second stages of training, respectively), Valley (229k videos and 703k dialogues on them for the 1st stage of training), VideoChatGPT (13k videos and 100k dialogues for the 2nd stage of training).

LITA
LITA (Language Instructed Temporal-Localization Assistant) — an article published in March 2024, dedicated to improving the ability of VLLM to understand the temporal aspect of video, especially in the task of temporal localization of objects, people, events, etc. To achieve this goal, the authors came up with a number of innovations:
Time tokens encoding the relative positions of frames within the video. Each video is divided into T equal intervals (T = 100), and the relative positions of the intervals are encoded with time tokens from <1> to
.
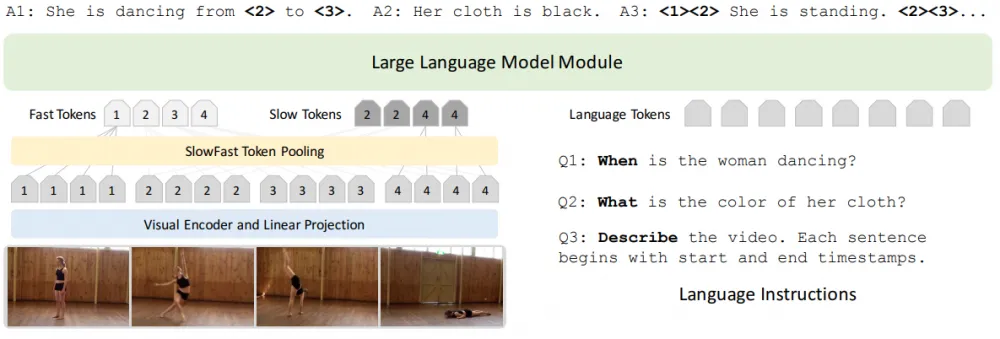
“Slow” and “fast” frame tokens (SlowFast tokens). First, T frames are evenly sampled from the video, each independently run through a visual encoder (CLIP-L-14), resulting in the video being represented by 100 × 256 visual tokens. Then, to obtain “fast” frame tokens, all 256 tokens of one frame are averaged together, resulting in 100 “fast” tokens per video. “Slow” tokens are sampled much less frequently — only 4 frames per video, and within each frame, the number of tokens is reduced by 4 times using 2 × 2 spatial average pooling, resulting in only 256 “slow” tokens per video. Then all 356 tokens are concatenated and fed into the LLM.
A new dataset for training and evaluating temporal localization skills — ActivityNet-RTL. It is dedicated to a new type of task — RTL (Reasoning Temporal Localization), “temporal localization requiring reasoning”: video tasks are constructed in such a way that to answer correctly, the model must synthesize an understanding of the temporal aspect of the video and world knowledge. For example, to answer the question: “When does the dance become more energetic?” it is necessary not only to navigate in time but also to understand what an “energetic dance” is.
PLLaVA
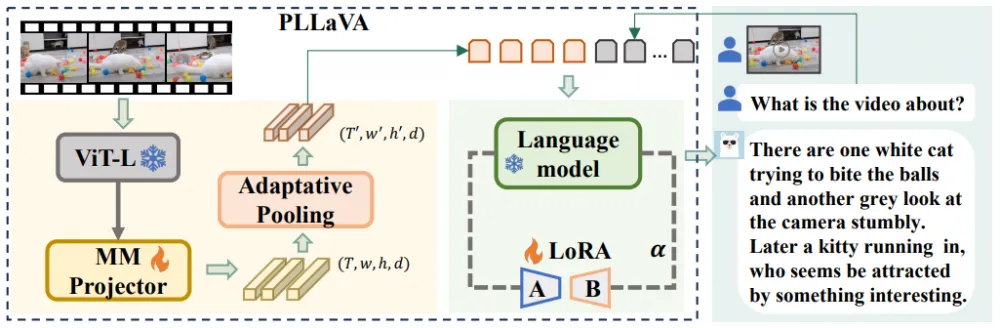
PLLaVA (Pooling LLaVA) was released in April 2024. The main feature of the approach, as can be guessed from the name, is a simple and effective strategy for pooling visual features.
Main features:
As in Video-ChatGPT, the model is based on one already trained on image modalities (not just texts) — here it is LLaVA Next.
It is experimentally proven that previous approaches to aggregating visual tokens (simple concatenation, as in Video-LLaVA, or Average Pooling across all dimensions, as in Video-ChatGPT) lead to metric degradation when increasing the size of the dataset or using text prompts that were not in the training.
An alternative feature dimensionality reduction strategy is proposed: only 16 frames are sampled from the video, but adaptive pooling with averaging is applied only to the spatial resolution (averaging along the time axis led to worse results). The LLM receives a tensor of temporal representations with dimensions 16 × 12 × 12 × d, where 16 is the number of frames, 12 × 12 is the number of tokens of each frame after pooling, and d depends on the specific LLM's dimensionality.
When fine-tuning on video data, the adapter is fully unfrozen, and the LLM is trained using LoRA.
The final model showed SOTA results in a number of video benchmarks, but performed best in generating detailed descriptions for videos.
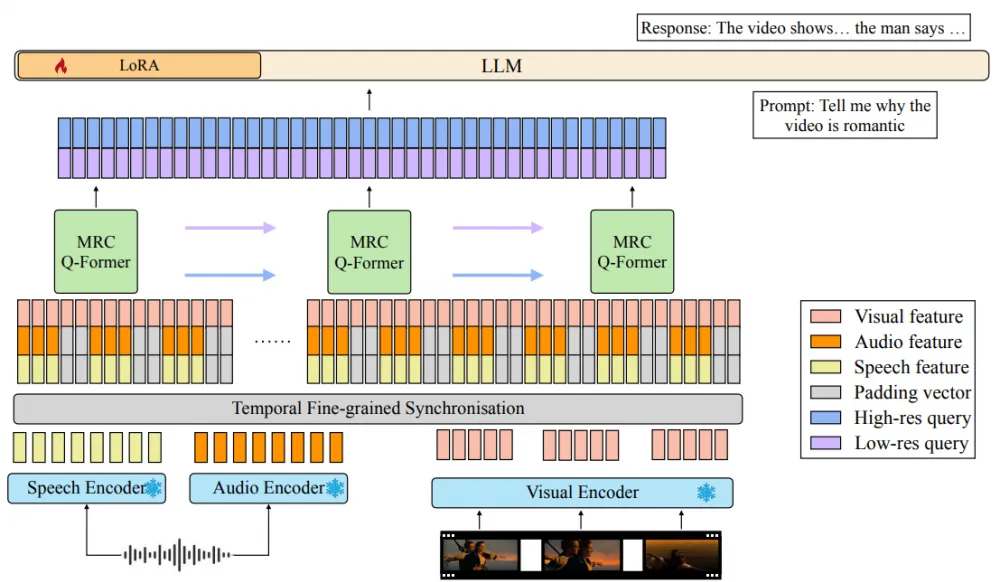
Video-SALMONN
Video-SALMONN (June 2024) is the first approach where the LLM is able to synthesize information from video sequences not only with accompanying sounds but also with speech. Key features of the work:
For video frame encoding, InstructBLIP is used, for audio and speech — BEATs and Whisper, respectively. The audio signal is sampled at a frequency of 50 Hertz, and the video — at 2 Hertz (or 2 FPS). Then all features are synchronized in time every 0.5 seconds and concatenated before being fed into the adapter: the embedding of each frame is supplemented with two sets of embeddings of 25 audio samples (speech and non-speech). If any modality is missing in a particular dataset element, a vector of zeros is used instead of its embeddings.
The MRC Q-Former (multiresolution causal Q-Former) is used as an adapter. At the output, we get a fixed-size common embedding for all three modalities. The adapter uses two levels of temporal resolution — high and low.
The LLM weights are not completely unfrozen: fine-tuning is done using LoRA (low-rank adaptation).
LLaVA-OneVision
LLaVA-OneVision (August 2024) is a SOTA approach in understanding three visual modalities at once: single images, multiple images, and video. Key features:
Classic architecture (visual encoder, MLP adapter, LLM).
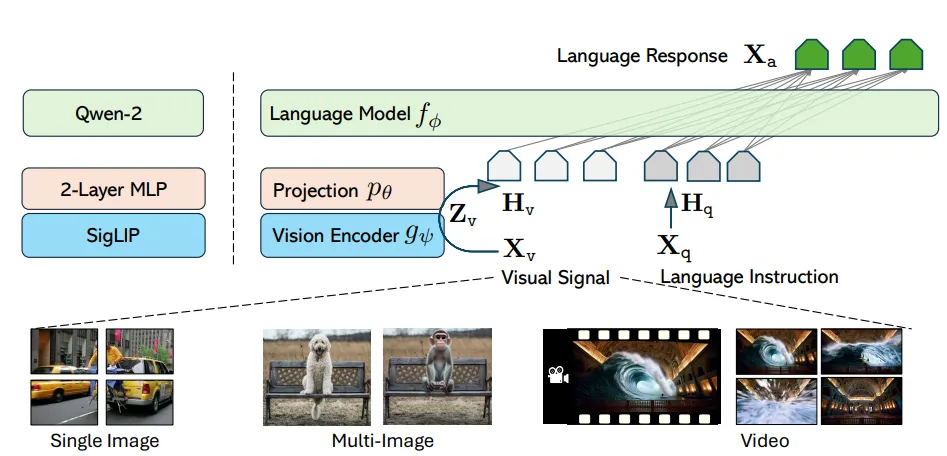
Interleaved-data: visual embeddings can appear in any part of the prompt.
The visual encoder SigLIP is used (each image is encoded with 729 tokens). It is common for all modalities and is unfrozen at most stages of training (except the first one).
A lot of good data (including previously published datasets from other authors, filtered and re-annotated as part of the work).
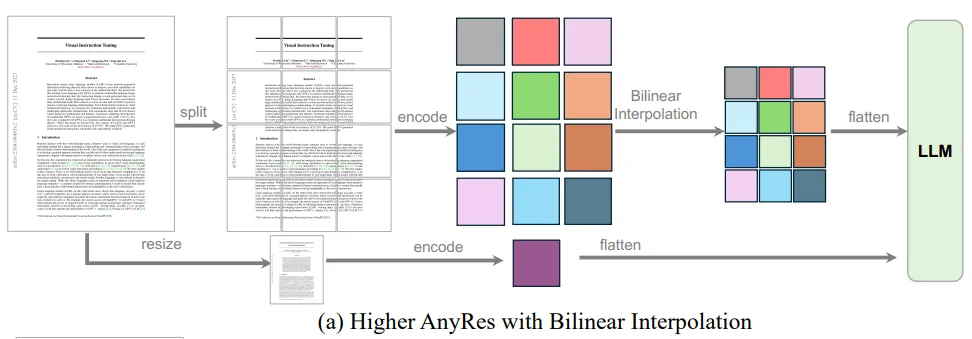
Higher AnyRes image processing method: before visual encoding, the image is divided into several parts (up to 36) depending on the resolution, each of which is encoded and passes through the adapter independently. The resulting embeddings are concatenated and reduced to a maximum dimension of 729 × 9 using bilinear interpolation.
Effective approach to adaptation for video and multi-image: more "heavy" modalities — video and multiple images — are added only at the last stage of training. Embeddings of all modalities are brought to approximately the same size (6-8 thousand visual tokens per dialogue) before being fed into the LLM.

As in Video-LLaVA, video frames are sampled evenly, but thanks to compression to 196 tokens per frame, it was possible to qualitatively train the LLM on 32 frames instead of 8.
Conclusion
Today we talked about key works dedicated to training large language models for video understanding, and how the approach to this task has evolved over the past few years. These are not all the works, but we tried to cover the most essential and interesting ones. Next time we will tell you how we teach LLM to understand videos and maintain a dialogue about them in Russian, and how we evaluate this skill to compare different models with each other.
Thanks to everyone who participated in research in this area. And special thanks to the author of the article — Marina Yaroslavtseva @magoli, the lead of the video track in multimodality, in the RnD XR team.









Write comment