
- AI
- A
Wolfram Natural Language Understanding or salvation for students
Wolfram is a cool thing. How many schoolchildren got an A because of it, and how many students passed the exam, you can't count...
Everything is simple: a bad student uploads a task and gets a pleasant result with a good grade. All tasks are calculated algorithmically.
Even copy a physics lab report...
Therefore, the main mystery of this service is the translation of unprepared student information into a form suitable for algorithms.
The language model (NLU) is the key.
What is NLU in the most general sense?
Natural Language Understanding (NLU) in the Wolfram system is an architecture that combines symbolic methods, NLP. And here it is necessary to emphasize. NLU is not about statistical methods that can constantly make mistakes. The accuracy of interpretation and translation into a form suitable for recalculation is the most important thing in the architecture.
"Complex linguistics, not statistics".
Symbolic methods are based on the use of formal grammars, syntactic rules, and logical calculations to extract semantic information.
Symbolic processing also includes building dependency trees and using "ontologies" to work with formal definitions of objects and their relationships.
This is not classic transformer NLP with distributed weights, where there is no "curation" of meaning or context, whatever those words mean.
Semantics, meaning, and sense, constant understanding of what is happening "in the notebooks" — this is the basis of Wolfram.
In the stream, we can insert intermediate records of our decisions and get NLU "understanding" of the situation, the meaning of the input data.
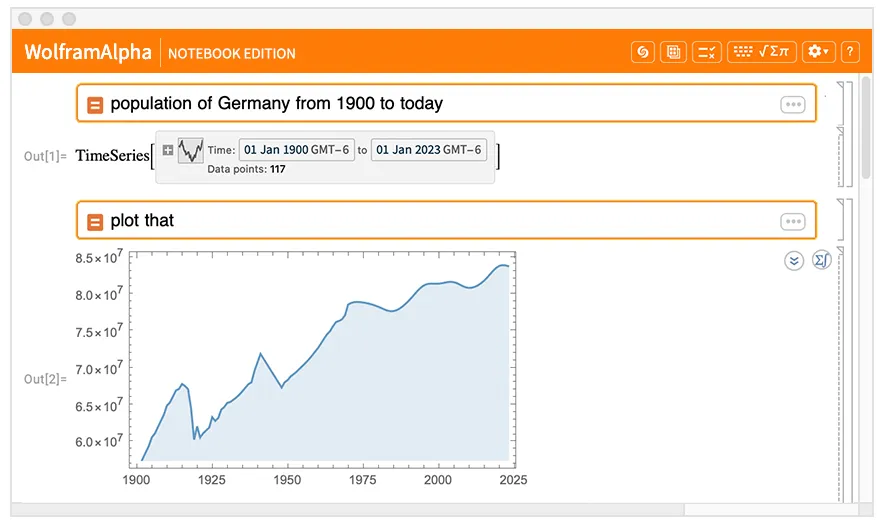
Question-answer systems use NLU to process natural language queries, extract information from the knowledge base, and generate relevant answers. It's simple. ChatGPT level in action, but usually students or schoolchildren go to Wolfram not for this.
To process multilayered or contextually rich texts, the Wolfram system uses methods of logical inference and deep semantics.
These mechanisms allow the system to go beyond simple data extraction and move on to reasoning about logical connections between entities, event chains, and relationships.
Semantic interpretation here is not only about analyzing explicit data, but also latent dependencies that may be important for a complete understanding of the query. For example, Wolfram can work with scientific texts, analyze equations and formulas, structure information, and provide meaningful answers taking into account all layers of context.
Wolfram works on all levels of the input data.
Synthesis of symbolic and attention mechanisms:
The integration of machine learning models and symbolic processing in Wolfram NLU is based on the fundamental idea of the complementarity of these approaches, where each solves problems for which the other is ineffective or inapplicable.
Symbolic processing operates with deterministic rules, formal grammars, and ontologies, which allows for strict logical conclusions and text interpretation based on predefined data structures.
This is methodologically related to the use of dependency graphs, syntax trees, and context-free grammars, which accurately model syntactic and semantic relationships in sentences.
In turn, machine learning models based on probabilistic approaches provide adaptability and the ability to learn from data, identifying patterns that are not amenable to deterministic analysis.
The integration of these two approaches requires a complex architecture where both methods work closely together at different stages of processing. Symbolic processing is used to build the initial structural interpretation of the text: parsing sentences, extracting key entities, determining their relationships and dependencies.
These structures are formed based on rigidly defined rules that work effectively in cases where syntactic and semantic connections can be formally defined. At the same time, machine learning models, such as transformers or neural networks, come into play at stages where a more flexible approach is required.
They allow for contextual dependencies at the level of the entire text, work with ambiguous terms, and process variable formulations that cannot be described through fixed symbolic rules.
The integration mechanism is that at the first stage, a formal structure is created that ensures the basic coherence of the text in terms of grammar and syntax. Then, machine learning models use this structure as the main framework on which probabilistic estimates are superimposed.
These models are able to identify latent dependencies in the data that symbolic rules cannot cover, such as contextual polysemy, distortions caused by incomplete or incorrect formulations, and other complexities that arise in natural language.
The result of the integration is the construction of a model that combines strict rules of syntactic and semantic logic with probabilistic estimates, which significantly improves the quality of predictions in conditions of uncertainty and data complexity.
Thus, there is an overlap of functionality: symbolic rules create a rigid structure, and statistical models adjust it based on probabilistic dependencies.
As for multi-modal approaches in Wolfram NLU, their significance goes beyond working with purely textual queries and includes the analysis of data from various sources: textual, graphical, numerical, temporal, and spatial.
This data is fed into the system in the form of various modalities, each of which represents a separate feature space with its own structure and specifics.
The essence of the multimodal approach lies in combining these different sources of information into a single semantic space, where complex relationships and dependencies can be modeled. For example, textual data can be enhanced with numerical or graphical data, such as time series or images, which significantly improves the contextualization and understanding of the query.
Wolfram NLU uses multi-level representations to process different modalities. Each modality at the preprocessing and data representation stage is transformed into a feature vector space, where their subsequent combination is performed.
Next, a semantic map is constructed, where each element of the query, whether it is text, a graphic image, or a numerical sequence, receives its vector representation and is connected with other elements through multilayer neural networks.
This process requires the use of latent encoding methods, such as autoencoders or variational autoencoders, which allow "compressing" information and identifying hidden dependencies between different modalities.
Multimodal approaches provide the ability to work with queries that include heterogeneous data and allow integrating them into the context of analysis.
Knowledge representation models: from symbols to vector representations
Disambiguation methods used by Wolfram to work with polysemous words and contexts rely on several key techniques, including context-dependent models, Bayesian methods, and logical inference rules.
When processing polysemous words, the system faces the need to determine which of the possible meanings the word is used in.
To do this, Wolfram uses a hybrid approach, combining probabilistic models that predict the meaning of a word based on data, and symbolic methods that provide deterministic interpretation based on predefined grammatical and semantic rules. Transformers are certainly involved here.
These models are capable of building word embeddings (vector representations) that depend on the context of their use. For example, the word "bank" in the sentence "I sat on the river bank" and in the sentence "I went to the bank" will have different contextual representations in vector space thanks to attention mechanisms.
This allows the system to classify the meaning of tokens depending on the nearest context and even take into account more distant dependencies.
For more complex disambiguation cases, Wolfram also uses Bayesian methods that build probabilistic models based on posterior distributions.
Each word is considered a random variable, and its possible meanings are events with certain probabilities.
The model takes into account the probabilities of each value depending on the context, creating a dynamic system for predicting the meaning of a word. For example, if the text mentions "bank" along with the terms "loan", "money", and "account", the system will create a scheme based on contextual probabilities.
Semantic memory in the context of Wolfram NLU is a structure in which knowledge is organized into hierarchical models, providing the ability for contextual and multi-layered understanding of natural language.
These knowledge models are based on ontologies and semantic networks, where entities and their relationships are formalized as nodes and edges. This allows Wolfram not only to analyze text at the level of surface syntactic structures but also to deeply delve into meanings, extracting hidden dependencies between concepts.
Hierarchical knowledge models built in the context of semantic memory organize data into multi-level structures.
At the top level, the most general concepts and relationships are presented, while at the lower levels, more detailed and specific knowledge is found.
For example, when working with the concept of "animal", the top level may represent the general category "animals", below are narrower classes such as "mammals" or "birds", and at an even lower level are specific species: "cat" or "falcon". The main task is the construction
One of the key mechanisms used in Wolfram to represent semantic information is embedding technology, in particular, Word2Vec and its extended versions.
Word2Vec is a method of distributed word representation in the form of vectors in a multidimensional space, where words with similar context are located closer to each other.
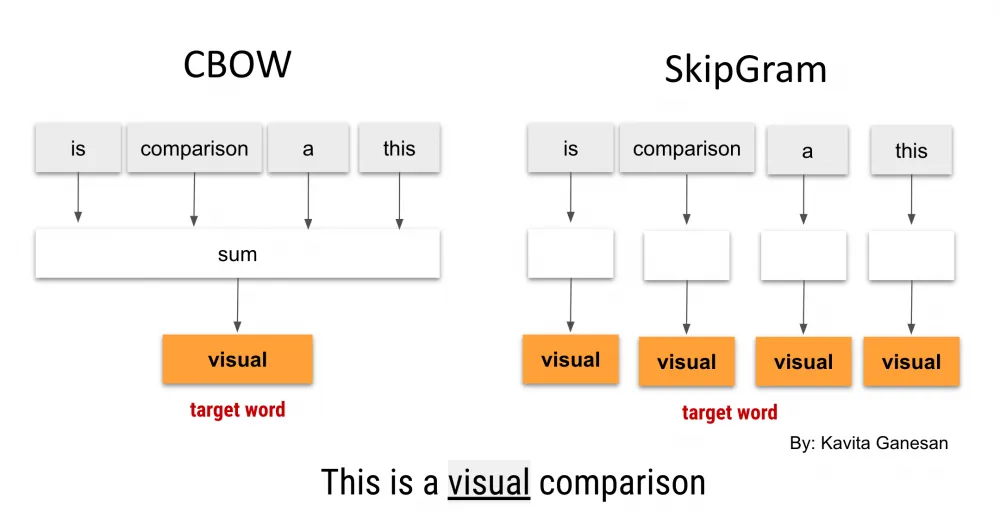
To build such representations, an architecture based on two methods is used: Continuous Bag of Words (CBOW) and Skip-Gram. In CBOW, the task is to predict the central word based on the context (i.e., surrounding words), whereas in Skip-Gram, the opposite is true: the surrounding words are predicted based on the central word.
For example, for the sentence "the cat sits on the carpet", the Word2Vec system will analyze which words most often appear next to the word "cat", such as "animal", "pet", or "mammal". This allows Word2Vec to build distributed word representations that generalize their meanings depending on the context of use.
However, for a deep representation of complex semantic dependencies and multilayered contexts, one Word2Vec may not be enough.
Wolfram uses advanced embeddings, such as contextualized models based on transformers (e.g., BERT), which allow taking into account not only the nearest context but also more distant connections in a sentence or even in a document.
Advanced embeddings are also used to build more complex semantic relationships between entities.
For example, the system can use contextualized embeddings to analyze sentences where complex metaphors or implicit semantic dependencies occur.
Suppose, in the sentence "The wind screamed through the forest", the system can use contextualized embeddings to recognize that the word "screamed" in this case is a metaphor, not a literal action.
Dependency Trees and Context-Free Grammars
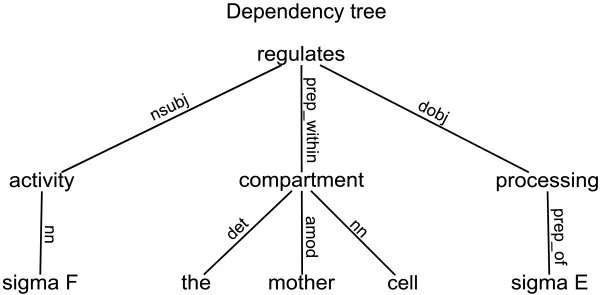
The use of dependency trees and context-free grammars (CFG) for syntactic analysis in Wolfram plays a key role in natural language processing and understanding.
These approaches provide the system with formal structures for parsing complex sentences and building syntactic links, which is necessary for accurately interpreting the meaning of user queries.
Dependency trees are graph structures where nodes represent words in a sentence, and edges show syntactic dependencies between these words. An important advantage of dependency trees is their ability to model grammatical relationships between words, regardless of word order in a sentence.
This is especially important for languages with flexible word order, such as Russian, where syntax heavily depends on context. In a dependency tree, each word is connected to another through grammatical links, such as subject, object, or modifier.
For example, in the sentence "The cat catches the mouse", the dependency between "catches" and "cat" (subject) and between "catches" and "mouse" (object) is clearly expressed through the edges of the tree. This helps Wolfram analyze the sentence structure and extract entities such as subject, predicate, and object.
Wolfram uses dependency trees to identify key elements in a query based on grammatical dependencies and build a structural representation of the sentence.
In more complex queries, such as "What is the level of CO2 in the Earth's atmosphere in 2020?", the system builds a dependency tree where "level" is the main entity, and "CO2", "Earth's atmosphere", and "2020" are attributes modifying the entity. This allows the system to structure the query in such a way as to link key entities and their characteristics for further processing.

Context-free grammars (CFG) are formal grammatical systems that describe the structure of sentences using a set of rules, where each rule recursively decomposes a phrase into its constituent parts.
In CFG, each sentence can be described as a sequence of syntactic categories (e.g., sentences, phrases, and word combinations) that are expanded according to predefined rules.
These grammars are effective for formalizing the syntax of a language, as they allow describing a multitude of sentences through a small number of grammatical rules.
Wolfram uses CFG for syntactic analysis and breaking down complex queries into components.
For example, for the question "Find the average temperature in Moscow in July 2020", CFG will break down the sentence into the main phrase (verb and complement), sub-phrases (place, time), and separate modifiers (month, year). This allows the system to structurally identify that "average temperature" is the main entity, "Moscow" is the place, and "July 2020" is the time modifier.
Wolfram can then use this information to extract data from the knowledge base or perform calculations based on known data.
The structural analysis of complex queries requires the interaction of these two methods. Dependency trees provide an intuitive, graphical representation of grammatical dependencies between words, which is important for accurately identifying key entities and their attributes.
At the same time, CFG sets strict rules for sentence deployment, allowing for a formal approach to syntactic parsing. Wolfram uses these methods in tandem to create a multi-level syntactic and semantic analysis, allowing the system to identify entities, relationships, and events in queries.
When the system encounters a multi-layered query, such as "What is the probability of rain in Paris next week?", it uses dependency trees to determine key entities such as "probability", "rain", "Paris", and links them to the time modifier "next week".
CFG, in turn, helps break this sentence into grammatical components, identifying main and secondary phrases and helping to build the correct structure for further semantic analysis and query execution.
Inference: how Wolfram solves problems based on NLU
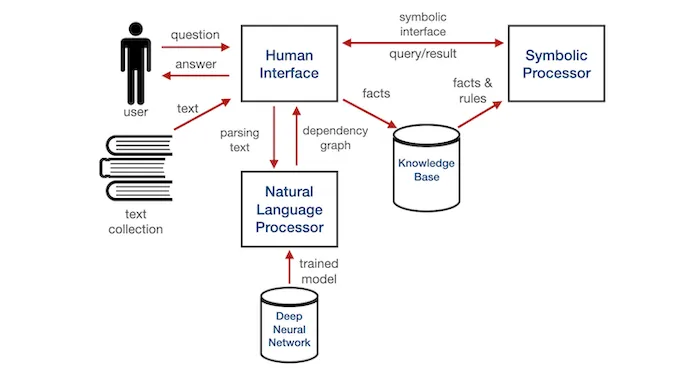
The principles of logical inference in Wolfram are based on the integration of reasoning engines with NLP modules, which allows the system not only to understand natural language queries but also to perform calculations based on strict logical and mathematical principles.
Logical inference in this context is the process of deriving new facts and conclusions based on known data and rules. It allows the system not just to answer questions directly, but to analyze, interpret, and generate answers based on deep reasoning and modeling.
When a user inputs a complex query that requires reasoning, the Wolfram system first processes the textual query through the NLP module, transforming natural language into formal data structures.
This is done through syntactic and semantic analysis. Syntactic analysis is responsible for parsing the grammatical structure of the sentence, identifying key entities and relationships, while semantic analysis is for understanding the meaning of these entities in context. After this, logical inference comes into play.
The integration of reasoning engines with NLP in the Wolfram system is achieved by building connections between natural language constructs and mathematically expressed rules.
Reasoning engines include not only deductive and inductive methods but also heuristic and probabilistic approaches, allowing the system to analyze data even with incomplete information or ambiguity in the query.
For example, when processing the query "What is the probability that it will rain in Paris tomorrow?", the system uses statistical weather data and synoptic models, integrating them with probabilistic analysis rules to generate a response based on logical inference from the available data.
For more complex queries, Wolfram uses deep semantics techniques, which allow the system to understand not only the surface meanings of words but also the hidden semantic connections between them.
Deep semantics is based on the analysis of ambiguous, multi-layered concepts and the construction of multi-level networks of meanings. This is especially important for complex scientific or technical queries where precise understanding of terms and their relationships is required.
For example, in the query "What is the solution to the Schrödinger equation for a particle in a potential well?" the system must recognize the "Schrödinger equation" as a complex scientific entity and then apply logical inference and symbolic computation to find the solution to the equation in the specific context of the "potential well".
To do this, Wolfram uses semantic networks that link mathematical and physical terms with algorithms and computational procedures.
An example of the inference mechanism at work can be seen in a query that includes complex mathematical and scientific tasks, such as "How to calculate the area of a figure given by parametric equations?" or "What is the energy of an electron in the third energy level of a hydrogen atom?".
First, the NLP module identifies key mathematical entities: "area", "parametric equations", "energy", "electron", "hydrogen atom".
These entities are then passed to the reasoning engine, which, based on the rules of mathematical analysis or quantum mechanics, uses symbolic computations to solve the problem.
For example, for the query "What is the energy of an electron in the third energy level of a hydrogen atom?" the system starts by applying the energy formula for an electron in a hydrogen-like atom. After the system recognizes the entity "third energy level," the reasoning engine automatically substitutes n=3 into the equation and performs the calculations, returning the result.
In this case, Wolfram uses a combination of symbolic computations, logical inference, and numerical methods to generate the answer.
This is a simplified model of the functioning of Wolfram Language and, in general, their unique Alpha ecosystem.
It is important to emphasize that the complexity of constructing their system lies in the need to correlate the knowledge base, symbolic patterns, quantum mechanics, and mathematical analysis with unstructured and simple human queries.
And according to some students' feedback - it does quite well)









Write comment