- AI
- A
AI in logistics: tracking vehicles on the production site using a neural network
In the spring at tekkix, I talked about how I created an application for tracking objects at a sporting event for my diploma project. My pet project has grown into a full-fledged real project. The knowledge and skills in neural networks, tracking libraries, and computer vision that I acquired were used to develop a vehicle tracking system on production sites. This system is based on the application of a convolutional neural network — a technology that allows computers to "see" and interpret visual information. In the text, I will explain the essence of this system, dwell on the principles of operation, tools, and architecture.
Hello! My name is Vlad Gubaidulin, I am a full-stack developer in the Logistics department of KORUS Consulting. In the spring at tekkix, I talked about how I created an application for tracking objects of a sporting event for my diploma project. You can read about it here.
Defining the goal
I consider our application as a complement to existing yard management systems (YMS) and as a way to more intelligently track vehicles in industrial areas.
In modern systems, the tracking of vehicle movement stages (entry to the territory/unloading/loading, etc.) is mainly carried out using secondary tools: license plate reading cameras, parking sensors, and cards. I am interested in implementing a similar function exclusively using ordinary surveillance cameras without additional "hardware" - this will simplify and automate the process.
Imagine a video surveillance system where tracking is carried out from multiple cameras, each with its own tracking tag. When a vehicle comes into the camera's field of view, it assigns it a unique identifier. The vehicle moves and enters the visibility zone of another camera — the new camera also assigns an ID. There is also an adapter that matches these identification numbers when the vehicle leaves one frame and appears in the next one according to the frame logic. Based on this logic, improvised checkpoints are formed.
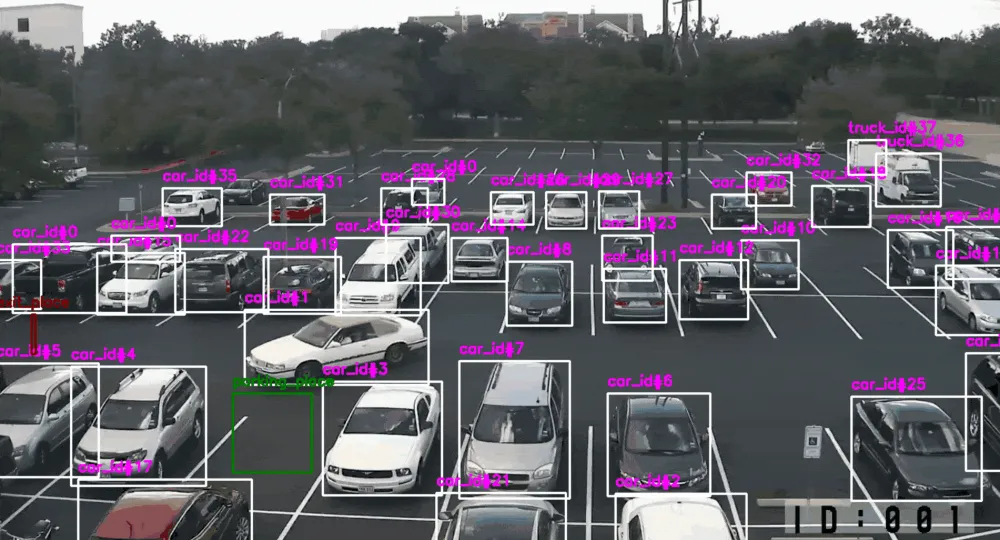
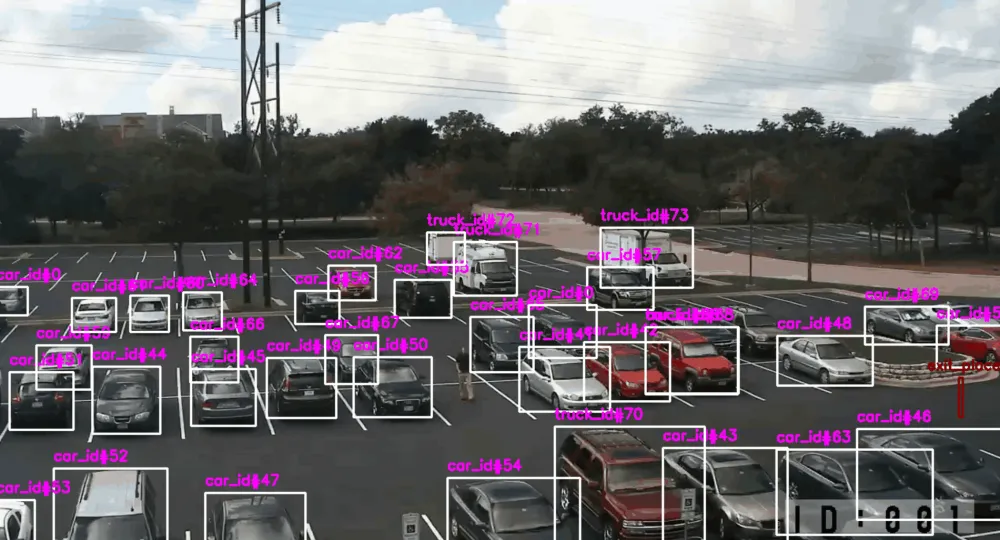
As advantages of such an application — in addition to automation itself — I will highlight several functions:
1. Analysis of the actual location of the vehicle at each stage of unloading. Helps maintain and optimize the performance of loading and unloading points.
2. Instant response if the vehicle is in a restricted area.
3. Accounting for the time the vehicle stays outside the parking space or unloading dock — if the vehicle stands still for a long time, the system will notify of a possible breakdown.
4. Identification of a free parking space or unloading dock — the next vehicle can be called to the place automatically.
5. Calculation of the vehicle's speed: if the permissible speed is exceeded, you can talk to the driver upon exit.
I have not yet found such ready-made solutions on the market from either Russian or foreign suppliers — only research papers on this topic are found. But if I missed something and you have information about such developments, please share in the comments.
Unpacking the tools
Here we do DataScience, so, of course, Python is our best friend.
We use SQLite for data storage, a simple and lightweight database.
To avoid dealing with database queries and immediately work with the necessary objects, we will take SQLAlchemy.
Now let's move on to the more interesting part - object tracking in video. Here, two powerful libraries come to the rescue: ByteTrack and YOLOv8.
ByteTrack is a tool that helps track multiple objects in video. It does this easily and efficiently, even if the objects are partially hidden or far from the camera.
YOLOv8 is one of the most advanced models for object detection, known for its speed and accuracy, making it ideal for real-time tasks such as video surveillance or autonomous driving.
And, of course, the OpenCV library is a great tool for working with images and videos. It allows you to do almost everything: from simple reading and writing videos to complex operations such as face recognition or image filtering.
With its help, you can resize, rotate, enhance image quality, and detect object contours. And all this sometimes even works.
The video processing pipeline is presented in Listing 1. It shows an example of connecting YOLO and ByteTrack, as well as rendering with OpenCV.
Listing 1
async def main(self, is_show_frames):
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f'Using device: {device}')
model = YOLO('yolov8l.pt').to(device)
cap = cv2.VideoCapture(self.VIDEO_PATH)
ret, frame = cap.read()
byte_tracker = BYTETracker(BYTETrackerArgs.BYTETrackerArgs())
while ret:
results = model(frame)[0]
detections = Detection.Detection.from_results(
pred=results.boxes.data.cpu().numpy(),
names=model.names)
car_detections = filter_detections_by_class(detections=detections, class_name="car")
truck_detections = filter_detections_by_class(detections=detections, class_name="truck")
detections = car_detections + truck_detections
tracks = byte_tracker.update(
output_results=detections2boxes(detections=detections),
img_info=frame.shape,
img_size=frame.shape
)
tracked_detections = match_detections_with_tracks(detections=detections, tracks=tracks)
for detection in tracked_detections:
tracked_objects_aud_id = await Recording().record_tracks_async(detection, self.CAMERA, self.AREA_EXIT)
if is_show_frames:
cv2.rectangle(frame,
(int(detection.rect.x), int(detection.rect.y)),
(int(detection.rect.x + detection.rect.width), int(detection.rect.y + detection.rect.height)),
(255, 255, 255), 2)
cv2.putText(frame,
f'{detection.class_name}_id#{tracked_objects_aud_id}',
(int(detection.rect.x), int(detection.rect.y) - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 0, 255), 2)
if is_show_frames:
if self.IS_PARKING_EXIST:
parking_color = self.COLOR.get_current_parking_color(tracked_detections, self.AREA_PARKING_PLACE)
# add bounding box for parking
cv2.rectangle(frame,
self.AREA_PARKING_PLACE[0],
self.AREA_PARKING_PLACE[1],
parking_color, 2)
cv2.putText(frame,
f'parking_place',
self.TEXT_PARKING_PLACE,
cv2.FONT_HERSHEY_SIMPLEX, 0.6, parking_color, 2)
# add bounding box for exit
cv2.rectangle(frame,
self.AREA_EXIT[0],
self.AREA_EXIT[1],
(0, 0, 150), 2)
cv2.putText(frame,
f'exit_place',
self.TEXT_EXIT,
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 128), 2)
cv2.namedWindow('frame')
cv2.imshow('frame', frame)
k = cv2.waitKey(33)
if k == 27:
break
ret, frame = cap.read()
cap.release()
cv2.destroyAllWindows()
Determining the architecture
The architecture of our application consists of two key components: the client-side and the server-side. The client-side is responsible for sending video frames to a remote server, using a message broker to transmit the data in byte format. The server-side handles the processing of these frames, extracting the necessary information and storing it in a database. After that, the aggregated data can be displayed in the user interface.
IP cameras are installed at the production site to monitor parking areas and loading zones. Each of the cameras transmits frames to the server for further processing. An algorithm using neural networks is applied on the server to identify and analyze objects of interest.
• New object: If the system detects an object with a new identifier (ID), the algorithm attempts to match it with a vehicle that has a similar previous location and last record within the allowable time interval.
• Old object: If the object already has an existing ID, the system simply updates its location.
To reindex objects, the exit_zones table is used, containing information about the presence of objects within the associative boundaries of the cameras. This table includes the ID of the last vehicle in the boundary, the ID of the camera with a common boundary, and the status of the vehicle's presence in this zone.
For example, if an object leaves the visibility zone of Camera 1 and enters the visibility zone of Camera 2, the data from Camera 2 is processed to determine if this object is new to it. If so, the system checks if it has been tracked by other cameras. If the result is positive, reindexing occurs. If not, the object is assigned a new index. For old objects, only the location information is updated.
All data is transmitted to the interface and available for viewing in the storage. Other systems can connect to the database via API or message broker.
System Functionalities
Functionally, the system is divided into two parts:
1. Logging the movement of objects on video;
2. Comprehensive tracking of objects on the territory by several cameras, taking into account the transition of objects from the visibility area of one camera to another.
The first part is currently fully implemented. A UML class diagram has been designed, which formed the basis of the database schema. For the minimal operation of the system, three classes are required:
- cameras;
- tracked_objects_aud;
- associative boundaries (exit_zones). The class of associative boundaries is necessary for reindexing objects when moving from one camera to another.
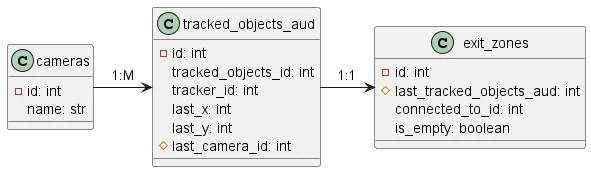
The second part — object tracking itself — is partially implemented. An algorithm is already in place that is responsible for reindexing tracked objects when an object moves from one camera to another. It is called on every processed frame for any detected object after recording a new vehicle or updating the data of an old one in the database.
It remains to refine the moment with the calculation of the identity of two detected objects and the decision on indexing. That is, now the algorithm is rather stupid: when crossing the boundaries of cameras, it will assign the old index to any car, and the essence of the final idea is that it can accurately determine that a new vehicle has entered the visibility zone or that we continue to observe the old one.
Now I am thinking about creating my own neural network that will compare two objects by convolution and give out the percentage of their identity. So far, everything is at the experimental level.
Such a system can be launched in any production. It is enough to manually configure the associative zones-boundaries of the cameras — the rest it will determine itself. The Achilles' heel of the solution is performance, since powerful resources are needed for the normal operation of the system out of the box: CPU, video card, RAM. As a compromise, you can consider limitations: process every n-th frame, instead of processing each one. With this approach, it will be necessary to calculate how many frames can be skipped.
Pseudocode
The method responsible for reindexing tracked objects when an object moves from one camera to another is called on every processed frame for any detected object after recording a new vehicle or updating the data of an old one in the database. The reindexing algorithm is presented in pseudocode A1.
Algorithm A1
Procedure actualize_exit_zones_data
Input exit_area_rect – coordinates of the bounding box of the associative boundary
Input transport_rect – coordinates of the bounding box of the vehicle
Input camera_id – identification number of the camera from which the frame came
If exit_area_rect and transport_rect intersect then
Retrieve from the database the current state of the associative boundary model from the exit_zone class
If the value of tracked_objects_aud_id is NOT equal to the current vehicle then
Assign tracked_objects_aud_id the value of the current vehicle id
Assign the flag is_empty the value 0
End
End
Else if the value of tracked_objects_aud_id for the associative boundary from the exit_zone class is equal to the current vehicle then
Assign the flag is_empty the value 1
Retrieve pairs of object ids and associative boundary ids that are linked, provided that the linked boundary also has the is_empty flag equal to 1
If such a pair of associative boundaries exists then
Overwrite the coordinates and camera in the older model for tracked_objects_aud with the current ones, delete the new id from the table
Assign the pairs of associative boundaries last_tracked_objects_aud NULL and the flag is_empty 1.
End
End
End actualize_exit_zones_data
Developing
The development went through the following stages:
Transferring existing methods from the pet project.
Designing the application's ER model.
Implementing the reindexing algorithm.
Implementing and integrating the neural network with the calculation of the identity of two detected objects and making a decision on indexing (in progress).
During the implementation of the reindexing mechanism, I encountered difficulties. Firstly, I was not closely familiar with the SQLAlchemy ORM, which led to mistakes during development. Secondly, I initially did not come up with "triggers" that should initiate reindexing. Now they exist and are entered into a separate table that records entries and exits from the camera boundaries. When describing the principles of the system, I talked about it.
Determining further steps
Plans:
implement and deploy a neural network to calculate the identity of two detected objects and make a decision on indexing (when I manage to do this, I will definitely share the results);
implementation of the application API and separation of the monolithic application into client and server.
I will emphasize my personal result: from a pet project developed for the defense of a diploma, it has grown into an (almost) full-fledged tool applicable in real business. I hope that I will quickly cope with all the listed difficulties and finalize it. It will be great if my example encourages some of the readers to develop their pet projects or create such.
I will be glad to your comments and questions. If anyone has ideas and suggestions on how to improve or optimize the system and solve the problem of calculating identity, please share in the comments.









Write comment