
- AI
- A
Super Ethical Reality: what to consider before using LLM in development
Should we trust something that cannot understand the consequences of its actions? The answer seems obvious, but as the niche of linguistic models develops, we increasingly delegate routine tasks to AI.
My name is Sophia, I am an employee of the RnD department at Raft, working at the intersection of ML and backend. Today I would like to discuss the ethics of using LLM in the context of development processes. Let's take an overview of the existing problems, what preventive measures are, and also find out what questions we should ask ourselves before implementing a linguistic model into a product!
The relationship between LLM and ethics
LLM aka Large Language Model is a type of model that is capable of "understanding", processing, and generating human-like text. These are the familiar GPT, Llama, and other beasts.
When we communicate with people, we should adhere to certain ethical principles: we should not deceive interlocutors, disclose their secrets, or endanger people. Now we also communicate with linguistic models and delegate tasks to them.
Almost everyone has asked GPT to generate a piece of code at least once. And code generation is not the only use-case in development. LLMs have already learned to be successfully used for creating application architectures, writing test cases, and analyzing code for vulnerabilities. Today, the use of AI has become part of our routine.
Let's look at the main problems we may encounter when using LLMs:
Data privacy and security
Ethics and security are in a close dialectical relationship. We are primarily interested in issues of responsibility for the creation and use of technologies, the safety of their application, and protection against misuse.
The first thing that comes to mind when we talk about LLM security is, of course, OWASP. The Open Web Application Security Project (OWASP) is a non-profit organization that studies methods to improve software security. At the end of 2024, they released an updated list of vulnerabilities that affect linguistic models. My colleagues have made a translation of this material into Russian, and it will be available soon.
The updated list includes issues such as model manipulation through prompts, data correctness for training, output processing, and access control. Ignoring these threats can lead to serious economic and reputational losses, service degradation, and even legal disputes.
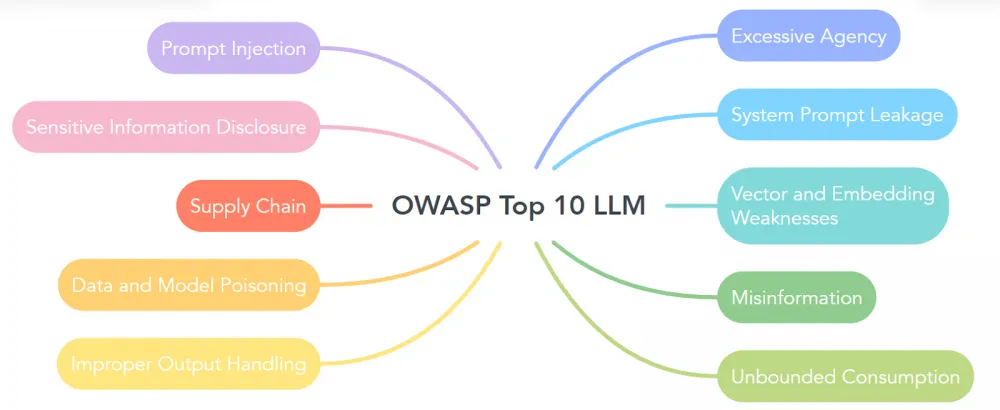
All of the above is very important, but in addition to the classic use of the model for some human everyday purposes, it is also important to consider the threats that arise when language models are used for writing code or designing architecture.
For example, GitHub Copilot is also based on LLM. In 2021, a study was released, which found that about 40% of the code generated by Copilot contains vulnerabilities. Overall, this is not surprising if the model is trained on code parsed from GitHub.
How to reduce risks?
Ensure that the system prompt is sufficiently protected from disclosure and modification.
Do not include personal data, financial information, or confidential business data in the prompt.
Check plugins, plugin providers, training data, and do not leave the model's response unprocessed.
Limit the model's capabilities, do not leave unnecessary or dangerous functions at its disposal.
Do not forget about DoS, limit resources and set request limits.
LLM fills in gaps in its data using statistical patterns. Use RAG or fine-tuning to avoid this.
Implement code vulnerability analyzers in development processes. I personally recommend adding a separate stage with Sonarqube in the CI\CD pipeline.
Bias and Fairness

LLM bias is a phenomenon where the model starts generating responses that reflect stereotypes, errors, or someone's views embedded in the training data. This can manifest, for example, in discrimination, inaccuracies, or fact distortions.
Why does this happen? Models learn from data that already exists on the internet or other sources, and there is a lot of everything — both useful and not so much. If there are many biased opinions in the data, the model will also absorb them.
What relevance does this have to code or architecture? When LLM generates code, it may produce outdated solutions, unsafe constructs, or ignore best practices because it was trained on such data. Let's consider specific examples.
Inefficiency and unreliability:
If the model was trained on old repositories, it may generate code that uses deprecated functions, unsafe constructs, or simply inefficient approaches.
Example:
Using
varinstead ofconst/letin JavaScript, which is now considered outdated practice.Generating SQL queries without injection protection.
Popular does not equal best:
The model may prefer popular but bad or unsafe solutions if they were frequently encountered in the training data.
Example:
Hardcoding passwords or keys, this error is often encountered in data.
Using arrays instead of hash tables for large amounts of data where performance is important.
Lack of individuality:
The model can generate solutions that are poorly suited for a specific task or language. It may prefer popular libraries or approaches instead of more specialized and optimal ones.
Example:
Generating a solution for Python based on pandas due to the popularity of the library, even if the task is better solved through built-in data structures.
How to solve these problems?
Use the human evaluation approach
Run the model on existing programming benchmarks (or create your own)
Use SOTA prompting techniques with clear indication of technologies and cross-checking the model's own answers
Try to avoid delegating the choice of technologies to the model
Use linters and other static code analyzers
Implement and constantly run unit tests
Disinformation and lack of informativeness
AI texts are created quickly, but often contain errors, biases, and hallucinations. This is especially dangerous in medicine, law, and other serious fields.
Models are trained on data from the internet, where there are many inaccuracies and stereotypes, and they do not always understand the context and simply select words statistically. You can learn more about why LLMs lie in my colleague's article on our blog.
It should be noted that by the word "disinformation" in the title we mean the unintentional misleading of the user by the linguistic model. Therefore, it is important to fact-check: evaluate the author and their qualifications, return to the original sources, analyze the purpose of the publication. It is also worth considering possible biases, looking at the relevance of the data, and checking how well the materials are recognized by other experts.
How to deal with these problems?
Use multiple sources to verify facts, such as numbers, results, statements, dates, names, etc.
Use fact-checking tools: Google Fact Check Explorer or Claimbuster
Assess plausibility and context. Ask yourself: does the statement sound plausible?
Pay attention to the model's database update date.
Ask the model to double-check its own answer or even directly task it with finding errors.
Censorship and Intellectual Property

Many commercial LLMs (e.g., OpenAI GPT, Anthropic Claude) are subject to censorship or content restrictions in accordance with the policies of the developing companies. How can this hinder development?
The model may refuse to process tasks related to sensitive code (e.g., tasks involving the analysis or generation of vulnerable code). There is also the general problem that the code is sent to the LLM provider's servers, which contradicts NDA principles.
If sufficient resources are available, a hybrid approach can be used. For example, use a commercial model for general automation and a custom model for tasks requiring more flexibility. For instance, send tasks for optimizing simple code to OpenAI, and give more specific tasks related to higher levels of vulnerability to a local LLM. General tasks are sent to commercial models, while sensitive and specific ones are sent to self-hosted models.
The second major issue is how the LLM processes and generates code and text. Using such models in development can pose risks of intellectual property infringement.
The model may reproduce code snippets protected by copyright if it was trained on repositories containing proprietary licenses. There is a small study on the topic.
The use of generated code in projects with different licenses (e.g., MIT, GPL) can lead to conflicts. For example, there is an interesting thread on this topic. There have been cases where Copilot generated code protected by the GPL license, raising concerns about compliance with the terms of this license.
Companies are also concerned about this issue and provide their solutions. For example, Copilot has legal guarantees. And Microsoft provides protection against intellectual property lawsuits when using their tool. There are also special tools that check code for license compliance (e.g., FOSSology).
How to deal with these problems?
Use self-hosted LLM and/or add classic ML models to the pipeline
If sufficient resources are available, use a hybrid approach
Accountability and Decision-Making Management

The last but most controversial point in today's article. The questions "who is to blame?" and "what to do?" will always be relevant, and the IT field is no exception. The use of large language models in development processes promises automation, faster task completion, and increased productivity. However, it also raises important questions. For example, who is responsible for decisions made with the involvement of LLM? How to manage processes where models play a key role? Below we will consider the main problems and their solutions.
About the uncertainty of responsibility:
When LLM makes or helps make decisions in development processes, it is not always clear who is responsible. If LLM generated incorrect code or configuration that caused a production failure, who will be responsible for the consequences? The model developer? The team that implemented the LLM? The organization as a whole? There is no correct answer.
What to do?
Determine roles and responsibilities in advance. Teams should clearly define who is responsible for making final decisions. LLM should act as an assistant, not the sole decision-maker.
Consider implementing "Human-in-the-loop" — this is a mandatory review by engineers of all critical decisions proposed by LLM.
About the black box:

Many LLMs are "black boxes," meaning their internal decision-making processes are opaque to users. Developers may not understand why the model suggested a particular solution. To avoid accidentally shooting yourself in the foot, it is advisable to understand what is under the hood.
How to deal with it?
Use interpretable LLMs.
Integrate solutions that provide not only the result but also an explanation (e.g., Explainable AI technologies — XAI).
Log all decisions made using LLM so that they are available for future audits. This will help identify errors and improve processes.
About excessive AI dependence:
Gradually shifting critical decisions to LLM can lead to skill loss among developers, reduced control, and lack of alternative solutions in case of model failure. This does not contribute to the growth of professionalism among employees.
What are the solutions?
Implement the "Human-in-the-loop" principle, which I wrote about in more detail above.
Limit the powers of LLM, clearly document in processes where the use of AI is appropriate and where tasks are solved exclusively by human efforts.
Restrict LLM access to critical scenarios and services.
Train and upskill employees so that knowledge and competence levels do not decline over time.
Develop action plans in case of LLM unavailability or incorrect operation. The tactic may include the use of standard scripts, ready-made procedures, and step-by-step instructions.
Test services for fault tolerance.
About ethical and organizational risks:
The use of LLM can lead to biased decisions, as we have already discussed above, or incorrect conclusions due to errors in model training. This is quite critical where accuracy and reliability are important.
How to counter this problem?
Have internal policies and protocols for using LLM, especially in critical processes.
Check the results of LLM for accuracy and correctness in "combat" scenarios.
What's next?
LLM is a very powerful and really cool tool, but to use it as safely and effectively as possible, it is important to know how to use it correctly. Make friends with language models, they are ready to help you. At the same time, remember that keeping up with the news in the field of LLM security is a modern necessity.
Feel free to share your experience of using large language models in development processes in the comments. Thank you for walking through the main issues of ethics in the use of large language models with me!












Write comment