
- Security
- A
How to securely erase sensitive information from a database
Why securely erase data at all? The main thing is that the user cannot retrieve it through the DBMS interface. Who cares about data remnants in files, it's not a problem. Or is it?
In fact, data leaks through memory and files sometimes occur. Because of this, there is a requirement to erase variables that stored passwords or keys. In such situations, optimizing compilers sometimes introduce bugs by removing memset for a buffer that is no longer used.
For databases, for example, there is an FSTEC requirement:
13.1. Database management systems of protection classes 6 and 5, either independently or with the use of a certified operating system, must ensure the deletion of databases and logs used by the database management system by repeatedly overwriting the objects of the file system to be destroyed (erased) with special bit sequences.
It turns out that (certified) DBMSs should not just mark records as deleted, but also overwrite the deleted data in all places where it was stored.
We became interested in this topic and decided to test publicly available DBMSs to see if they delete data or if something remains. And since we are developing Natch - an attack surface search tool, we decided to use it to investigate data flows in DBMSs.
After all, working with sensitive data and searching for leaks is not much different from working with untrusted data and searching for attack surfaces.
The testing idea was as follows:
Create a database.
Write "sensitive" data there.
Track the flow of this data in the system.
Delete the data using DBMS tools.
Check the places where the data got in step 3 to see if it is still there or not.
Write an article on tekkix.
PostgreSQL
To check if the data is deleted, you need to understand where it is stored. Of course, you need to create a database first:
CREATE DATABASE my;
USE my;
CREATE TABLE mytable (col text);Natch can track "sensitive" data coming from the network or read from a file. Then you can either connect to the DBMS remotely, marking the network traffic (which will contain the data added to the database). Or write the INSERT command to a file and mark the file content for tracking.
We used the second method, so we ran PostgreSQL under Natch control, passing the pg_insert.sql file with the following query to the DBMS:
INSERT INTO mytable VALUES (‘dhfgkjhewdrtg;kljhwekjthekjthkjwehtkjhertkjhewrkjthekjthkjwerhtkjhertkjhekljthekjgkjdsngkjnikjuh43kiujhtkj3ntkj3j3ntkj34hnrtkjh 3kjhtk3hrlkj oruq97g98weytg nui3ht k3h4trkhglkeoi;tru 8o934urowjrh qwtuikh3489tuyoiktghiljpoqwro;iwotrhyt’);The added string is not very random, but we were lucky, and it was not heavily compressed in storage. As a result, Natch determined that the data inserted into the table ended up in the files data/base/16389/16390 and data/pg_wal/000000010000000000000001.
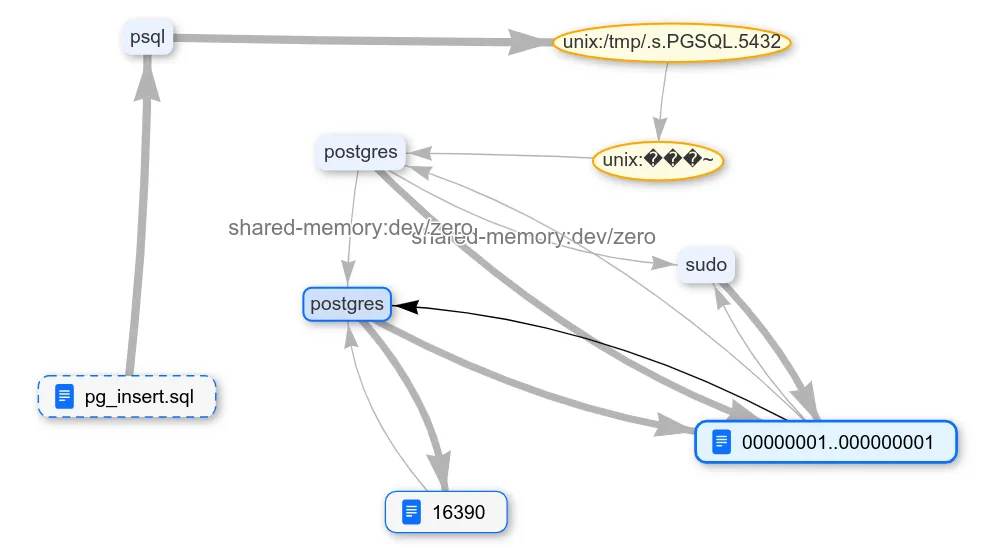
The first file contains the table row data, and the second is the write-ahead log (WAL). This is a change log used at least to recover the database after failures.
Now, when we delete the data, we need to make sure it is gone from both files. After all, this is sensitive data, and we don't want to scatter it around.
Here you need a little trick. Natch tracks data while it is being moved or processed somewhere. But if the data is gone, what can it show? To solve this problem, you can simply refer to the contents of the files where the sensitive data was stored (using find, grep, or even md5sum). Then either we will see the desired pattern in the file transaction log, or a process diagram will show an arrow with the transfer of sensitive data to a new process.
Why might the arrow not appear?
The fact is that Natch does not yet track the spread of tagged data on disk drives. Therefore, if something is written to disk and then read again, the tags will be lost.
But if the OS optimizes this process and saves the data in the RAM cache after writing, then the tags for them will also be saved. In such situations, the Natch data stream is successfully tracked.
So, let's try to delete the data from the table, and then calculate the md5 for the files we are interested in. The md5sum utility will be forced to read all the data from the files, and that's exactly what we need.
DELETE FROM mytable;The DELETE command probably does not physically delete rows. To completely delete, you will have to do something else. Let's test this hypothesis.
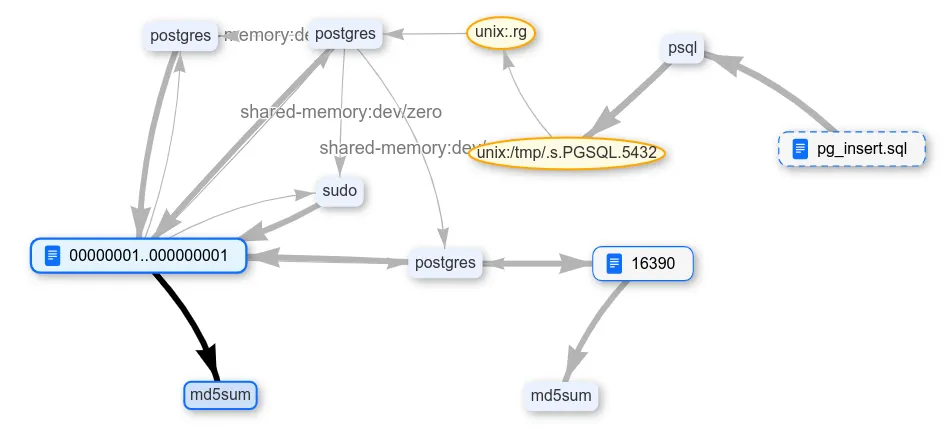
File transactions did not even have to be watched, all the data remained in the OS cache. And indeed, the deleted rows did not disappear from the table. But there is also the VACUUM command. It will definitely delete all unnecessary data.
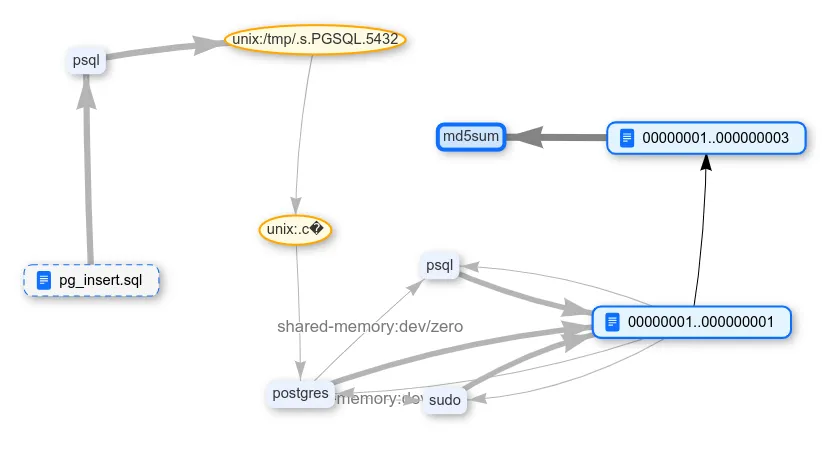
The data is still there, in the WAL. True, already in a new file. And indeed, everything was deleted directly from the table.
How else can you influence the database? Delete it entirely. Now everything should definitely disappear.
DROP DATABASE my;
VACUUM FULL;For certainty, let's stop the DBMS so that nothing remains in memory. And check if the added data is in place, only this time using grep, not md5sum:
systemctl stop postgresql
cd /usr/local/pgsql/data/base
grep -r oruq97g98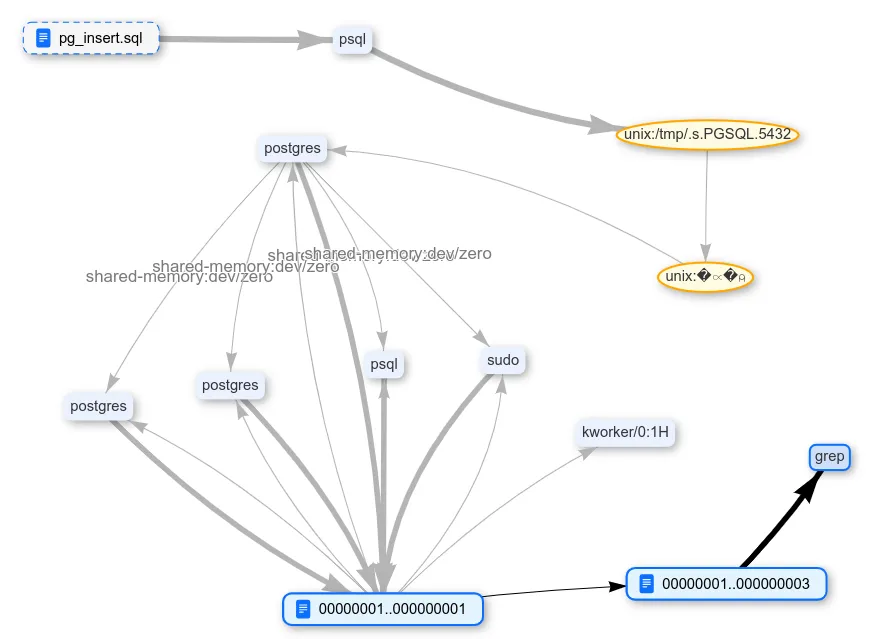
So, the DBMS was stopped, the entire database was deleted, and the "sensitive" data not only remained in the file, but also hung in the OS file cache.
MySQL
The next DBMS for research is MySQL. We will do about the same with it. First, let's find out which files our data will go to after INSERT:
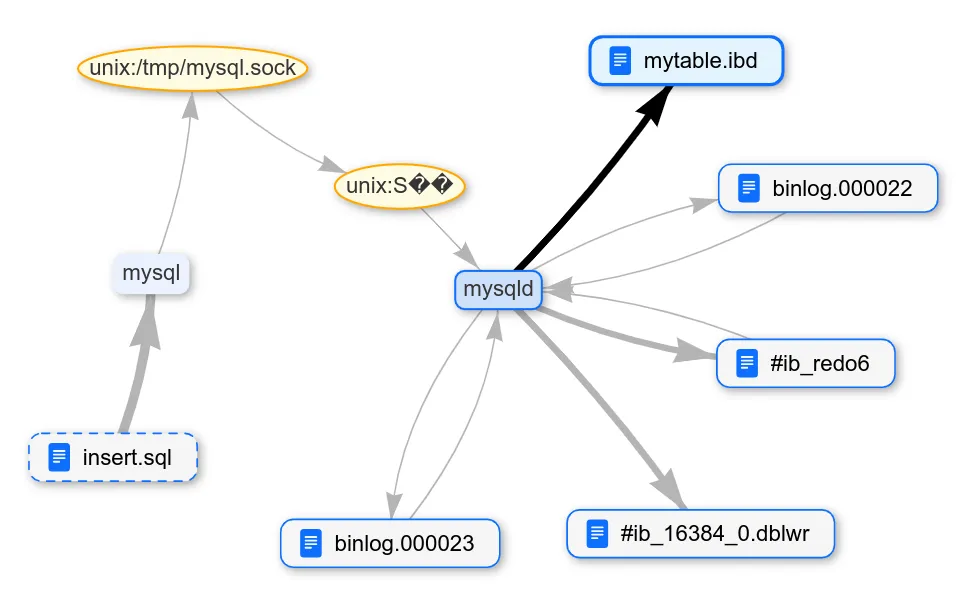
Here, as in postgres, in addition to the table file, there are also additional files with transactions - binlog and redo log.
Let's see what happens after deleting data from the table:
DELETE FROM mytable;
FLUSH TABLES;
FLUSH BINARY LOGS;
FLUSH ENGINE LOGS;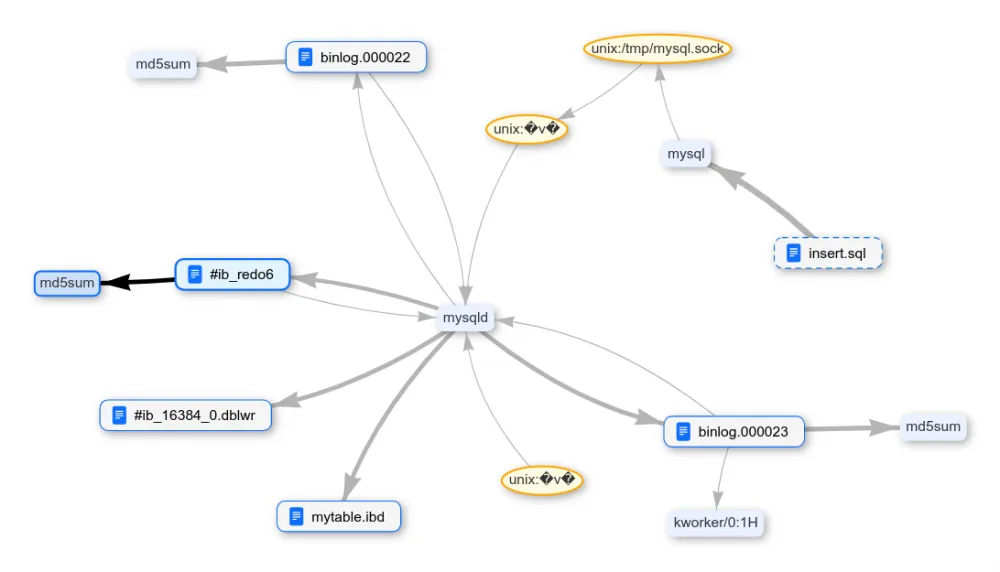
The data was expectedly saved in the transaction logs. It turns out that the binlog can be cleaned up using the RESET BINARY LOGS AND GTIDS command.
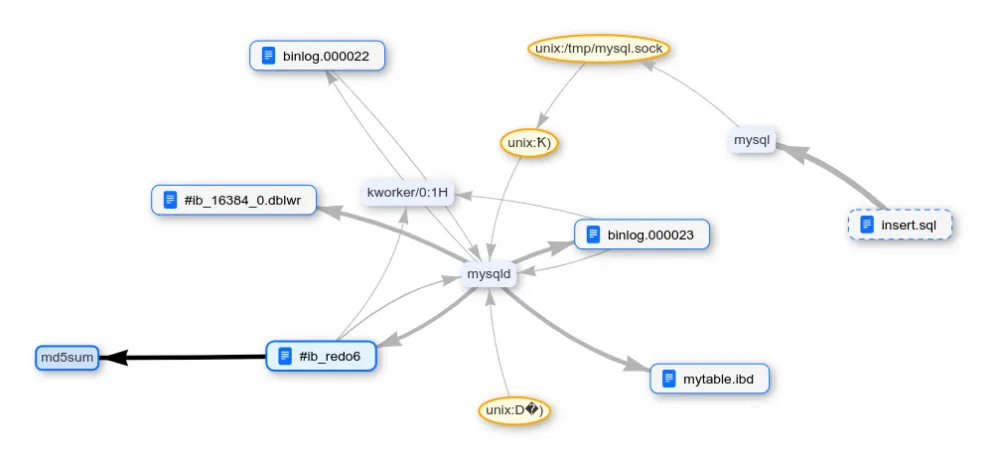
There is still a redo log. Deleting the database.
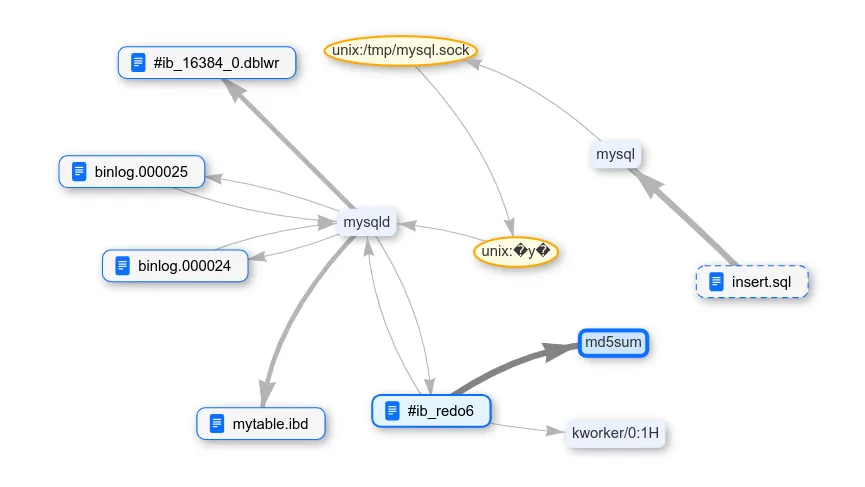
And again, it was not possible to erase the data from the change log.
MariaDB
Our third test subject is the MariaDB DBMS. First, we find out where the data added to the table is stored.
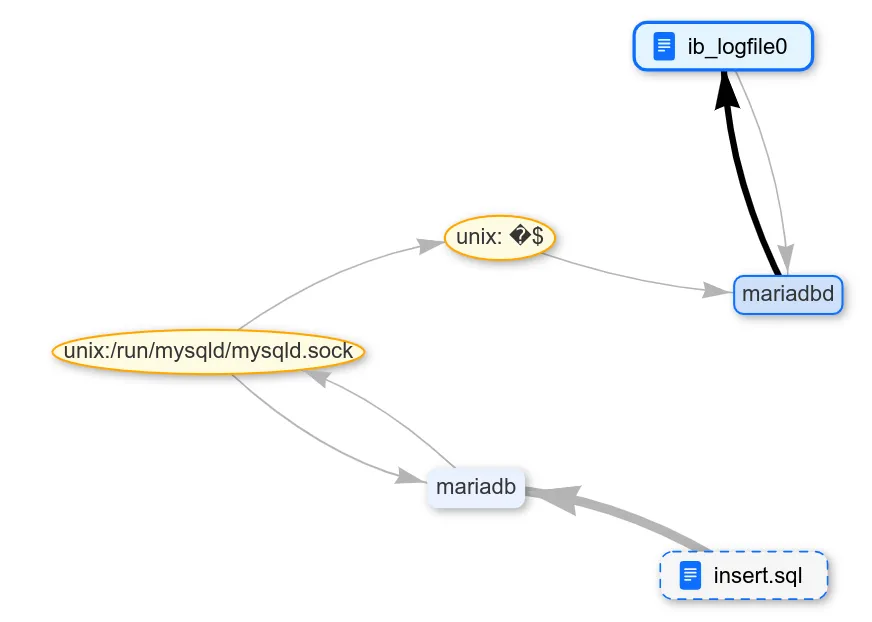
Natch shows writing only to the logfile. This is quite strange because there should also be a table file. Let's grep our pattern string in /var/lib/mysql, where this logfile and other mariadb files are located.
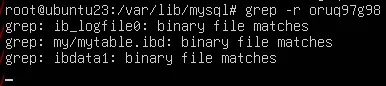
Indeed, there is both a table and some additional file. What grep read there can be checked using Natch:
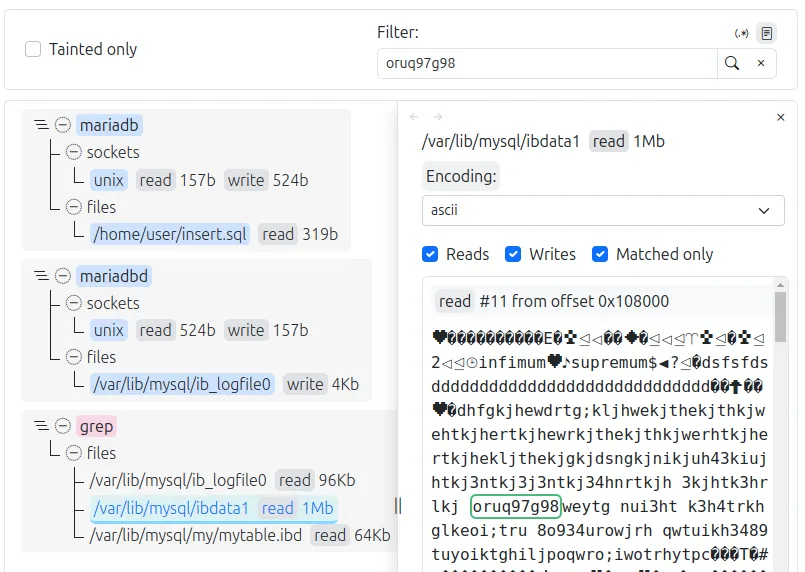
Now let's try to delete data from the database using the DELETE command. After deletion, we stop the DBMS service and do a grep. The data stream from ib_logfile0 was not detected in grep, which means MariaDB knows how to make the OS not cache the data of this file in memory.
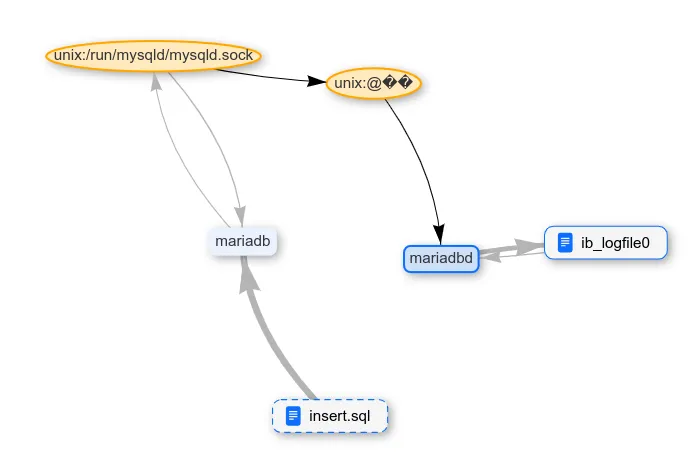
Since Natch does not see grep on the graph, let's look at the file operation logs.
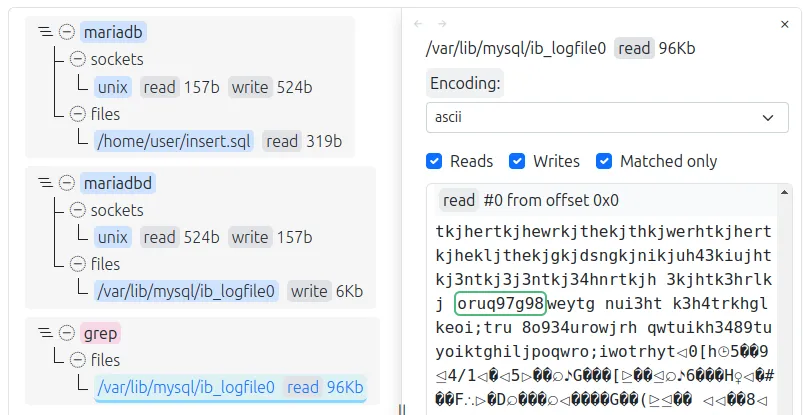
Surprisingly, the data from the table disappeared after a regular DELETE. Now let's try to delete the entire database using the DROP DATABASE command.
The same thing happened. The table files are no longer on the disk, but the data in ib_logfile0 remained. As with other DBMSs, "sensitive" data is saved somewhere. So MariaDB only differs in its strategy for working with table files.
Conclusion
It turns out that certified and enterprise versions of open products exist for a reason. None of the tested free DBMSs allow you to clean up deleted data from all files. Therefore, if you are building a certifiable system, you cannot just install a DBMS from some debian repository.











Write comment