
- AI
- A
Guide to Experiment Tracking in ML
Many are accustomed to the fact that metrics and simply saving the trained model are sufficient as the result of an experiment, but in the modern world of machine learning, experiment tracking is crucial for ensuring reproducibility, reliability, and efficiency. Let's look at the main stages of conducting an experiment and the problems that may arise. We will discuss the basics of experiment tracking in machine learning and explore how you can simplify your workflow with the right tools and practices. At the end, I will also share the benefits of one of the tools.
Hello, my name is Artem Valov, I am a leading specialist of the data analysis team at Sinimex. In the article, I will share how and why to conduct experiment tracking in ML.
We will discuss the basics of experiment tracking in machine learning and tell you how you can simplify your workflow with the right tools and practices. In conclusion, I will also share my experience of using one of the tools and talk about its advantages.
There will be no code examples here, as there are many tools and even more documentation and articles for them :)
Many are used to the fact that metrics and simply saving the trained model (checkpoint) are enough as a result of the experiment, however, in the modern world of machine learning, experiment tracking plays a key role in ensuring reproducibility, reliability, and efficiency.
To begin with, let's refresh the basic stages of developing solutions using machine learning.
Basic stages of experiments
Most tasks in the world of machine and deep learning include data collection, model building, and result evaluation. For different areas, each stage can be differently important and labor-intensive. For example, based on the experience of our projects, data scientists can spend up to half of their time on data preparation, and, as a rule, the results depend more on the quality of the dataset than on the model architecture, so the process of working with them is also important to record (similar to brewing coffee - you can use different coffee machines, but the taste largely depends on the beans). Let's briefly describe the main steps:
Target Definition and Model Evaluation
Target Definition
First of all, it is discussed what will be modeled within the framework of the experiment, as the approaches to the solution and evaluation metrics depend on this.Choice of Metrics
A metric is an external quality criterion that depends only on the predicted labels and does not depend on the process of obtaining them. Metrics can be both criteria for the quality of the model and specific assessments from the client that are important for the business (at the same time, they may contradict intuition and be fundamentally incorrectly set, but this is a completely different story).Splitting Strategy, Validation Period Allocation
At this stage, the strategy for dividing into training, validation, and test sets is determined. In some tasks, random splitting may be suitable, and in some cases, the sets may be divided over time.
Data Preparation
Initial Data Collection
Collection of raw data from various sources. Conducting exploratory data analysis (EDA). Analysis of the quality of raw data.Transformation and Augmentation
Cleaning and preprocessing data to make it suitable for model training. At this stage, you can also think about how to enrich the existing dataset with feature generation and external sources.
Model Training
Model Selection
Choosing the appropriate algorithm based on your task. It is most convenient to start with a basic option - quick and simple models or even heuristics for debugging and obtaining the first metrics, and then move on to testing more advanced algorithms.Hyperparameter Tuning
Tuning parameters to optimize the model's performance. Popular libraries such as optuna or hyperopt will be useful tools for this purpose.
Common Problems and Challenges
Manual formatting: transferring metrics from logs to notebooks, Excel, or wiki can be labor-intensive and prone to errors.
Risks of local storage: storing charts and analytics in a local environment increases the risk of losing the obtained results.
Separated models and codebases: storing models separately from the code over time can cause discrepancies between the expected and actual performance of the model.
Overloaded Git repositories: regularly pushing all data to Git can eventually overload the system and complicate version management.
In summary, such habits can lead to:
Insufficient reproducibility — inconsistent results that will be difficult to reproduce.
Unreliable metrics and models — the obtained results will be hard to trust.
Inefficient automation — the absence of automation or its presence leads to new manual processes.
Difficulty accessing results — difficulties in retrieving data from past experiments. An example of this could be the situation "this experiment was on Andrey's computer, but he is currently on vacation))."
Such problems are usually characteristic of rapid prototyping, where many hypotheses are tested, but errors during the experiment can ultimately give a false impression of the project's further development, so experiment tracking should be present even at the initial stages if possible.
What is experiment tracking in machine learning?
In short, experiment tracking in machine learning is a process that includes:
Saving = Storing artifacts for experiment reproducibility.
Organizing = Structuring experiments with customizable access.
Analyzing = Comparing results and exploring changes.
Artifacts
To reproduce the experiment, we need artifacts. Artifacts can vary significantly depending on the complexity of the pipeline and the modeling goals. In most cases, it is important for the team to work with a single "entry point" for building the model if the hypotheses are built at the modeling level. On the contrary, if we need to evaluate new features or our dataset has expanded, it is important to be able to quickly access the new version without losing the previous ones. Let's consider below what we can mean by artifacts:
Description of the experiment and metadata
It is important to describe what hypothesis we are testing in the experiment so that we do not guess after a few months what the goal was or what changes were made.Model and hyperparameters
Record all parameters that may affect the model and metrics. Store the trained model that can be deployed later.Datasets
You can store raw data and preprocessed data, but be careful with storage limitations. If your code is deterministic and you can track its changes, then the initial data is sufficient to obtain all derived artifacts, both intermediate and for training.Code and dependencies
Obviously, changes in data processing methods or model architecture will inevitably lead to new results. However, dependencies can also affect the result. It is especially valuable to be able to quickly restore a specific experimental environment if there were conflicts before or it could change during the study. What if the tracking system can record dependencies, build the environment, and run another experiment O_o? But more on that later.Metrics and indicators
Earlier we discussed what metrics we can save, but we can also record data-related indicators, such as data quality metrics — sizes, gaps, drift, etc. Have you ever seen someone get sota results just because they lost 80% of the test data?Logs and charts
Logs are useful for displaying EDA conclusions, data transformation, or tracking the training process. Charts can be part of the metrics or serve as additional analytics, which will then be reflected in the report (a common requirement, for example, for banks). They largely show what "went wrong" in the modeling framework.
You can simply "collect metrics", but the main idea here is not only to assess the consequences of the experiment, but also to have checkpoints for debugging if obvious or hidden problems are found. Be wise and try. Logging everything can be a difficult path, so follow your needs.

Tools for tracking experiments in machine learning

This is a sufficient part of the tools, but they all have many common functions. The most popular tools are likely to be regularly updated and maintained. Some trackers were originally used for another purpose, for example, DVC as a data versioning system received an extension for experiment tracking.
Popularity of tools
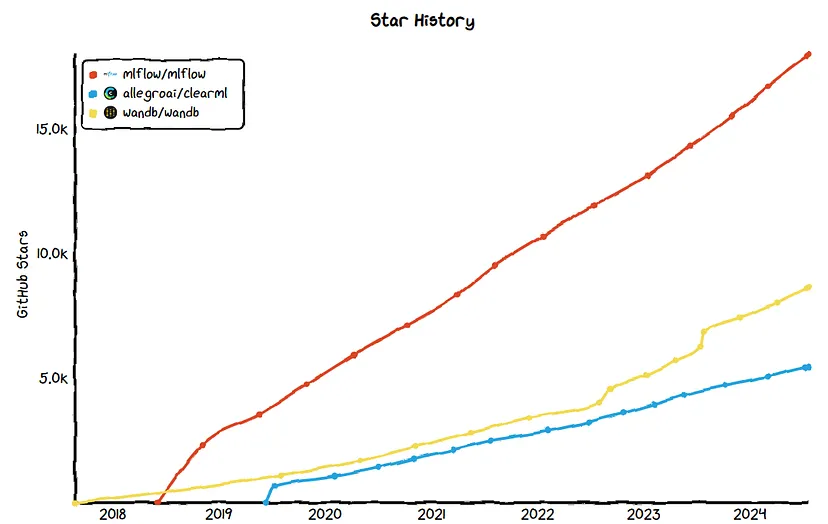
Previously, I used MLFlow and ClearML, and currently my team mainly uses ClearML. For basic tasks such as logging metrics and saving models, both tools are suitable. MLFlow is easier to set up and now offers new features focused on LLM and prompt engineering. If resources allow, ClearML provides a more robust and scalable solution with a huge list of development features.
It should be noted that many large companies use wandb, and ml enthusiasts often share the results of experiments in the cloud. I have not used this tool, so I cannot compare from personal experience, but you can always google why A is better than B, and vice versa.
In my experience, ClearML has proven to be an effective tool in both large production projects and small research projects or hackathons.
Why we use ClearML
Before listing a whole list of features, I will give a few situations that ClearML helped us resolve:
We had several parallel projects, each with its own branches of hypotheses for development. In MLFlow, we lacked project grouping and could have ended up with a mess of experiments, but ClearML has a hierarchy, so research can be conducted in isolation down to each developer or hypothesis, or filters can be used. In addition, it was convenient to define access rights: which experiments are seen by developers, managers, or stakeholders.
We were engaged in time series forecasting for pharmacy chains. When developing a prototype in notebooks, our results stopped reproducing, but since the tracking saved the notebook as an artifact, we quickly restored the lost version and checked what was wrong or what influenced the new results. Also, for quick analytics, we logged "debug samples": graphs of the target and forecast of random series, the best and worst by metric — this gave an understanding of which cases required refinement and allowed us to formulate new hypotheses. Accordingly, we applied the same practice to CV and NLP projects, as the interface works with different data formats.
The company has its own product for organizing interviews, and the idea arose to add ML for automation, and we decided to start with resume parsing using open LLMs. We prepared the environment, prompt, scripts, data, and metrics. Since we were mostly engaged in prompt engineering, we decided to use clearml.agent to run experiments directly from the interface and distribute them to available nodes without manually cloning the project, assembling the environment, and running scripts.
On the lip synchronization project for creating digital twins, we tested various open-source solutions. There was a need to evaluate the current pipeline runtime and in case of optimization. ClearML logs the load on RAM, CPU, GPU, disk, network, which allowed us to quickly assess the current requirements and the potential for acceleration.
Summarizing and supplementing:
Convenient team and project separation, beautiful UI with out-of-the-box usage examples.
Sufficient autologging and broad framework support.
The ability to log various artifacts through autologging or manually (tables, charts, metrics), while almost any object can be saved as a pickle or even a folder (this is noted in the documentation). There is also the possibility to use various storage for artifacts, such as S3. Models when saved locally are also uploaded to the Model Registry automatically (depending on the framework).
Code versioning (including notebooks) is key to reproducing results and debugging.
Unified versioning of data and models with easy access.
Interface for data review and change assessment.
Some teams use clearml.pipeline as an alternative to Airflow.
Resource consumption monitoring (CPU, GPU, disk) is extremely useful for assessing requirements at preprocessing, training, and inference stages or identifying bottlenecks.
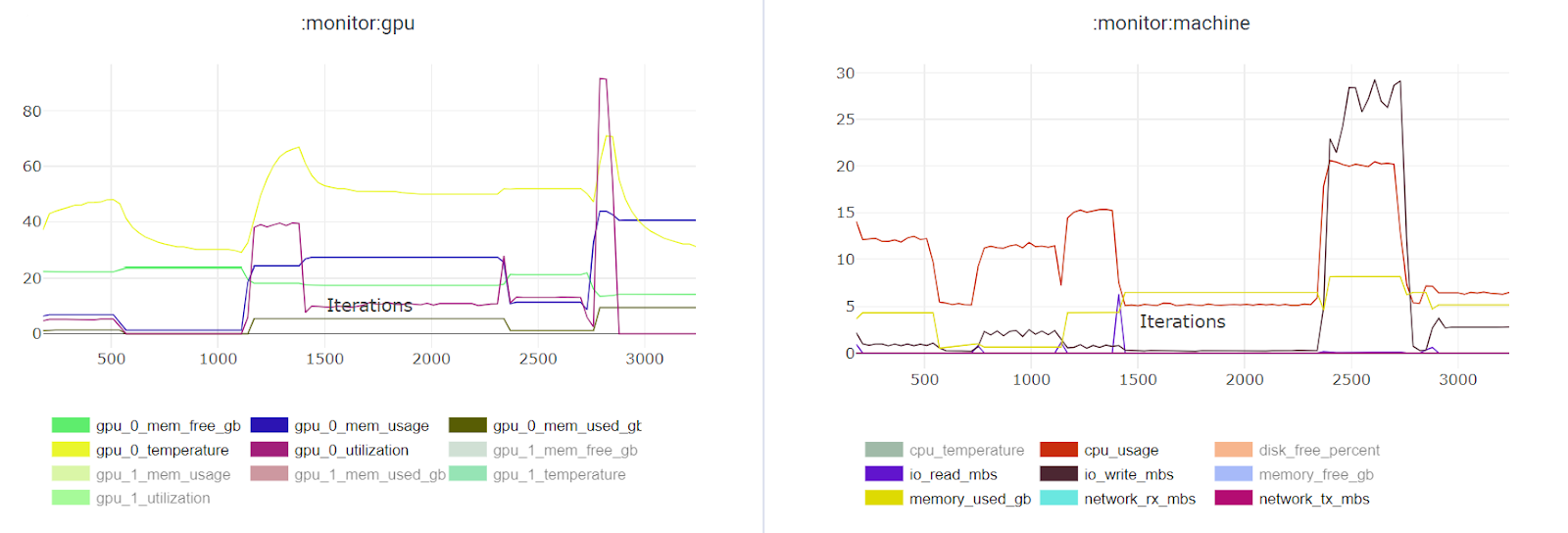
Remote execution via clearml.agent — easily add new computing resources for experiments that can be defined in the queue.
Fast experiments — for example, duplicate an existing experiment, change parameters or prompt, and run it on a free node. Thanks to dependency and code change tracking, the system can create a Docker container and run the experiment remotely via the agent.
Responsive maintainers who have their own channel in Slack.
And many other features aimed at creating a unified development system, such as CI/CD setup, deployment, embedded report creation, and cluster load balancing (some features are paid).

What should you choose?
Like any product, people often choose what is more accessible, simpler, or familiar. Here are some aspects that may help you:
Open source vs commercial solution — open-source is often suitable for small teams, whereas large companies require support for the solutions they use and advanced features.
Cloud or on-premises deployment — if you have confidential data, an on-premises service is preferable. If you don't have your own resources, you can use the cloud.
UI, convenience of organizing experiments, and aesthetic interface — some tools lack project hierarchy, and if there are many projects, this can lead to chaos.
Integration with your frameworks — auto-logging is more of a nice bonus, but overall not critical, as you can still save artifacts manually.
Support for team collaboration — role-based access model and permission restrictions enhance security and reliability (so that no one accidentally deletes important results), and improve structure. Sometimes it's hard to find your experiments in a team, let alone search among all possible experiments.
Access security and the ability to share results — providing results to external audiences, clients, or managers.
Additional features such as application deployment, support for working with LLM.
Conclusion
As tools evolve and cover missing features, it makes sense to compile a list of the most popular and supported ones, test them on real tasks, and choose the one that best suits your needs.







Write comment