
- AI
- A
How we carried out the AI transformation of Sber's strategic processes
Hello, tekkix! My name is Andrey, I am a technology entrepreneur, I work as a CTO in AI startups and help implement AI in companies. One of the high-profile cases for me was the AI transformation of Sber. Today I want to tell you how the AI transformation went, and what lessons should be learned from this experience.
Before the AI transformation of the bank (2020), I worked as the Chief Data Officer and Chief Data Scientist of Sber's strategic block. At that time, ChatGPT did not yet exist, and the AI revolution was hardly discussed seriously. Of course, AI and ML were actively used in banks for credit scoring and recommendation systems.
Our tasks included macroeconomic stress testing of the bank, analysis and forecasting of banking markets, launching new products to the market, resource planning, analysis of employee efficiency, as well as control over all bank processes. Every year, our block formed a new strategy for the development of the bank and the ecosystem.
One of the first AI projects of our team before the AI transformation was a model for predicting employee efficiency. To train the model, we collected a large amount of data from HR systems, control and access accounting systems, socio-demographic indicators, psychometry, employee assessments, and other data. At that time, it was the only AI model in the strategic block.
The direction was new and was used to solve the company's internal problems. But all the developments came in handy when the company announced the AI transformation.
Preparation for AI transformation
The news that Sber is massively implementing AI was announced literally in one day. Each department had to be digitized and AI had to be implemented in every described work process. This had to be done by me and my small team. At that time, six data engineers, two data analysts, and two data scientists worked with me.
In Sber, about 2500 processes have already been described in BPMN notation. There is a good article about working with processes in Sber, I will not go into details. The descriptions were done by the departments and process managers themselves, and then they were sent to us for validation. We extracted metrics from them and worked with the key ones.
The deadline was a surprise: we were given one quarter to complete the work. The timeframe seemed completely unrealistic. I don't think the people who set this KPI themselves considered it achievable. But I took the task as a personal challenge and an exercise in efficiency.
AI Maturity Index
The results were evaluated using the AI Maturity Index, which we jointly developed at the bank level. The AI Maturity Index metrics included 35 indicators across seven areas on a five-point scale. For those interested in details, check under the spoiler to see the metrics.
Metrics for assessing the AI maturity index
Strategy and management: percentage of financial effect from AI in business processes; quality of strategy development; quality of AI transformation management; self-learning in task setting; awareness and involvement of management.
People and culture: Time2Hire; productivity of data specialists; quality of talent management; quality of data function popularization; quality of competencies of data specialists and business customers.
Infrastructure: share of data scientists developing models in the Cloud; share of models in production in the Cloud; availability of infrastructure for data specialists; availability of open source libraries; share of processes on unified AI platforms.
Data: share of bank's IT systems connected to the Data Factory (DF); share of models in production using DF data; share of pipelines with quality checks in AI processes; quality of data management process; Time2Market data.
Models: share of models with quality above AutoML-baseline; share of "red" models of medium and high significance in operation; Time to Market models; share of models implemented not in industrial environments; share of models in production on auto-monitoring.
R&D: partnerships with universities and research institutes; quality of the R&D process; share of R&D initiatives; results and applicability of R&D; participation in conferences and publication of articles.
Implementation: share of AI processes in production; AI penetration in processes; share of models of high and medium significance in production; uniformity of AI implementation in the business unit by processes; quality of the AI implementation process.
AI implementation in strategic processes
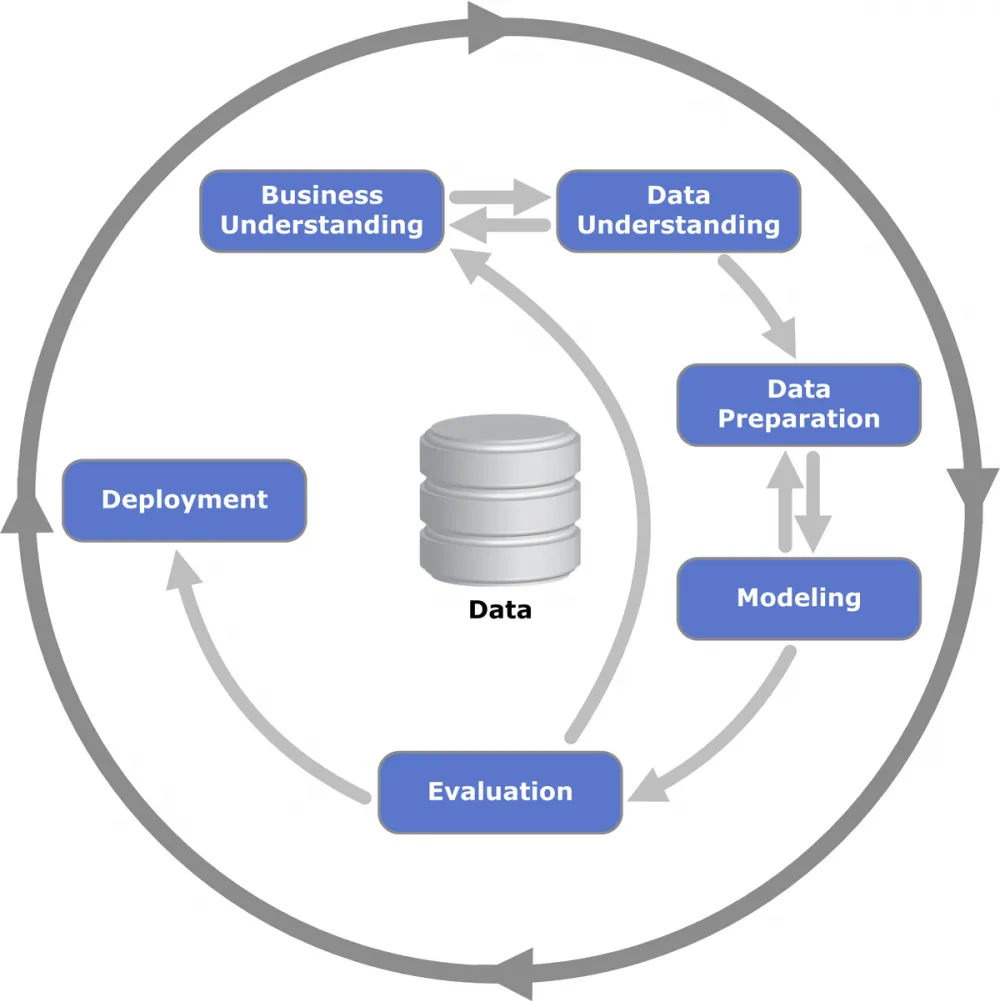
To implement AI in processes, we used the CRISP-DM (Cross-Industry Standard Process for Data Mining) methodology. Processes at Sber are divided into supporting, business processes, and management. Our unit was engaged in 30 key management processes. They needed not only to be described but also to calculate the economic effect.
The task is extremely challenging: how to digitize the decision-making process of a manager? And the preparation of a report based on the subjective feelings of experts? In most cases, the question: "what exactly do you do at work" baffles people. But as our experience has confirmed, any task is solved by decomposing it into elements.
Step 1. Process Definition
Before starting to transform anything, it was necessary to understand the current state of the processes, what goals we want to achieve, and how to achieve them correctly. We analyzed the current state of affairs: the AI maturity index in the strategic block was zero. The target indicator was 90 points on average for the bank.
The processes consisted of operations that initially seemed elusive. How to evaluate the intuition of an employee making a macroeconomic forecast? It was necessary to overcome enormous resistance and misunderstanding.
After dozens of in-depth interviews, we identified all strategic processes with their metrics, broke the processes down into individual operations, and found out which operations were the most resource-intensive.
Then we assessed how feasible and justified the implementation of AI in each operation was, and predicted the potential financial effect of implementation where it was possible. The result was a visual and prioritized list of processes and operations that needed AI transformation first.
After analyzing the processes into which we had to implement AI, the question arose: who would do this if we only had two data scientists on the team? I started looking for ten more data scientists. A quarter before the start of the work, I managed to close the hiring, and we launched the AI transformation of strategic processes.
Step 2. Data Collection
To develop any models, data is needed. Therefore, we studied the datasets that were already used in various processes.
In Sber, most of the data is available in the centralized Data Factory. The problem is that the data we needed was not stored there, as it was strictly confidential. We could only work with embeddings from a secure data repository, which we had previously developed together with colleagues from cybersecurity.
We also received raw data directly from access control systems, or automatically parsed some data from open access. In total, we used more than fifty data sources, and we ourselves supplied ten sources to the Data Factory. What data we used in our work:
Macroeconomics: GDP and dynamics, inflation rate, unemployment rate, exchange rates, interest rates, credit conditions, etc.;
Banking markets: interest rates on deposits and loans, data on the volume of lending and deposits, competitive banking offers, customer reviews, market share of various banking products, and others;
Performance: HR data on employees and their interactions, psychometrics, socio-demographic characteristics, goals, objectives and KPIs of employees, meeting topics, and others;
Customer journeys and processes: data on interactions with customers, description and metrics of processes, and other data.
Step 3. Data preparation and validation
Even a very detailed data set contains errors that we had to find and fix before starting work. For example, we found errors in the time accounting in the access control and management systems. It often happened that employees had an entry into the office without an exit, or vice versa. This could greatly distort the picture of internal efficiency assessment. The turnstiles were located at different sites, so there were often errors in the uploads themselves - an employee could not be found in the office at all, but he was active in other systems: had meetings in the calendar or closed work tasks in the task tracker; according to such criteria, we could evaluate the working time of employees.
We identified common data issues and automated the process of preparing datasets for model training. Often, we had to work with text (even before the LLM era), which also required special skills in data preparation: tokenization, normalization, and vectorization. In the process of data preparation, we selected the most relevant ones, excluding duplicates and gaps. We also generated new features for our tasks.
Step 4. Modeling
At the modeling stage, we selected appropriate machine learning algorithms. Logistic regression, decision trees, neural networks, survival models, and other methods were suitable for our tasks. Depending on the nature of the task and the data structure, we had to vary the approach and tools. For rapid model development, I managed the resources of the supercomputer Cristofari, (ranked in the top hundred of the TOP-500 supercomputers in the world). The result of the work was more than sixty different models. Under the spoiler is a large but far from complete list:
Hidden text
The bank's stress testing model, which allowed the bank to prepare in advance for potential economic shocks, as well as identify vulnerable areas and develop strategies to strengthen them.
Intelligent analysis of banking regulation allowed the bank to adapt to changes from the regulator and reduce legal and operational risks. We solved this task together with HSE University as part of R&D.
Models for forecasting banking markets helped analysts better understand which factors have the greatest impact on the markets, to improve the accuracy of expert forecasts.
Product feedback analysis allowed the bank to quickly improve its offerings based on customer opinions. Customer segmentation models allowed analysts to offer products that best meet the needs of each customer.
The results of the efficiency model allowed for an objective assessment of employee performance, identifying strengths and weaknesses, as well as developing training and motivation programs.
The employee attrition model allowed for preventive measures to retain key personnel, reducing turnover and hiring costs for new specialists.
ONA (Organizational Network Analysis) was used to analyze the functional-organizational structure through graph analysis based on employee communication data. It identified inefficiencies, improving resource allocation and reducing duplication of functions.
The intelligent calendar allowed for the optimization of schedules for managers based on task and priority analysis, increasing their productivity.
The employee idea recommendation system, as well as idea generation based on ruGPT-3, allowed top managers to find new solutions to current problems.
Intelligent document search and classification accelerated access to information and decision-making.
Intelligent analysis and forecasting of business process metrics allowed for the automatic identification of inefficient stages and optimization of processes, significantly improving the overall efficiency of the bank's operations.
Step 5. Model Evaluation
Technical evaluation of the developed models was carried out using metrics such as accuracy, F1, MAE, ROC-AUC, and Gini coefficient depending on the task.
After the models are developed, they must undergo A/B testing. We recorded the process metrics and launched the pilot models. If the process metrics improved as a result of using the model, the model was sent for further validation and subsequent implementation. All models were also validated by auditors to identify potential risks for the bank.
Step 6. Model Implementation
To deploy the models, we used a unified AI platform — SberCloud. All models went through the standard MLOps cycle and were retrained based on new data. We set up an automatic model monitoring system in production to respond to incidents in a timely manner. We also used AutoML and Process Mining tools for rapid AI implementation in processes.
For automatic model creation and retraining, we used AutoML. This tool works well with tabular data and binary classification. For banking markets, we built composite binary classification models where AutoML was very useful and accelerated the implementation process.
Time was pressing, and each of my employees implemented at least one developed model in production per month. Process Mining, set on direct rails, allowed us to model processes based on system logs in the shortest possible time, as well as to look for anomalies in them, identifying potential operations for automation.
Financial Impact of AI Implementation
The ONA (Organizational Network Analysis) model for analyzing the functional-organizational structure became one of the most successful models. It allowed top management to understand the true structure of communications based on employee interaction data to make decisions about the bank's staffing.
Optimization of duplicate functions also proved to be significant in the final assessment of our financial impact. We found 30 teams developing similar chatbots. Identifying teams that were unaware of each other and optimizing the number of employees helped avoid duplication of work and saved the bank about 3 billion rubles.
Conclusions
As a result, we managed not only to achieve the impossible KPI but also to bring the AI maturity rating to 93 points, exceeding the plan. For this, the bank's president recognized me as one of the best managers of 2021. In the future, all these models were used in the strategic dashboard and executive assistant.
A systematic approach, clear planning, and proper prioritization helped us cope with this task. Luck, enthusiasm, and soft skills for communicating with colleagues also came in very handy.
Working at Sberbank was an incredible experience for me due to the challenge that AI transformation represented. This process is not a one-time event but a continuous adaptation and improvement, requiring not only the implementation of technologies and working with data but also changes in culture, approaches, and team readiness to change. This is a difficult but necessary step for companies striving to remain competitive in the modern world.
One of the key success factors for me was the excellent team I was fortunate to work with. I realized that the success of AI projects is determined not only by the quality of data and models but also by the support of the team, clear management, and effective communication.









Write comment