
- AI
- A
How to protect your texts from ChatGPT and other AI bots
Most people do not realize the enormous amount of words required to train AI programs such as ChatGPT or Claude. When the first version of ChatGPT was launched two years ago, it was trained on approximately 300 billion words.
Tell this to people, and they won't be able to understand how huge this number is. A billion is such a large number that most people can't comprehend it. Here's some crazy math. If you were writing a thousand words a day, every day without a break, it would take 2,740 years to write a billion words.
Now multiply by three hundred. Because three hundred billion words were used to train the AI engine that powers ChatGPT. And they didn't ask permission for any of those words. They just helped themselves.
That's the thing about training AI programs. The quality of the writing matters. Bill Gates and Microsoft taught us that.
Before ChatGPT, Microsoft trained its first AI chatbot on Twitter. They shut it down in less than a day. Then The Verge published an article titled "Twitter taught Microsoft’s AI chatbot to be a racist a**hole in less than a day." The whole world laughed, hearing the robot talk like a sexist and racist troll on social media.
So when OpenAI was just starting out, they knew they needed quality literature. And not just quality. So they scoured the entire internet, taking text from books, media, online articles, scientific papers, Wikipedia, and much more.
The first to file a lawsuit was the media company The New York Times. According to the lawsuit filed last December, OpenAI sifted through millions of their articles and sometimes ChatGPT outputs fragments of their texts verbatim.
It's easy to say that it's just a jumble of words. So far, this is not happening. As long as phrases and chunks of text are output verbatim.
It's interesting how you would feel if it was your article.
How would you feel if ChatGPT used chunks of text that you wrote, and they took without permission. Because that's literally what's happening to the authors who write for The New York Times. And now it's in court.
I don't know how you are doing financially, but ChatGPT is doing very well because they never had the legal right to use other people's works. OpenAI made three hundred million in August and expects to make $3.7 billion in 2024, according to documents reviewed by The New York Times.
ChatGPT has over 10 million users paying $20 a month. In addition, they make another billion from third-party companies that use OpenAI to create services. OpenAI forecasts that by 2029 their revenue will reach $100 billion.
But they have a small problem.
They are running out of texts to train AI.
In a new study published this summer by the Epoch AI research group, it is stated that companies working with artificial intelligence may run out of human-created content as early as 2026, and if they run out of fresh content, they risk stagnation. They need a constant influx of texts to continue improving their program.
The study says that paying millions of people to create the volume of text needed for AI models to continue growing is "unlikely to be an economical way" to increase productivity.
Tamay Besiroglu, the author of the study, says that AI may face difficulties in maintaining the current pace of progress once it runs out of human-created information. (source: PBS report)
Which makes perfect sense. Simply taking other people's texts without asking for permission and not paying compensation is more profitable than paying writers.
Now let's talk about how you write. Frankly, the only way to be 100% sure that no AI robot can use your texts is to write in a notebook. But for most of us, this is an unacceptable solution. And it is not necessary. Especially if writing helps you make a living.
So let's talk about an available solution.
Because it is very simple. Just a small text file. Like in a notebook.
When you write on the Internet, your files are stored on a server. Each server has a small text file called robots.txt - just a small text file that tells robots what they can and cannot do. They don't always listen. But most of the time they do.
In this text file, you will see instructions that look something like this:
User-agent: GPTBot
Disallow: /
You need to understand three components, and it's very simple.
User-agent is the name of the robot. For example, GPTBot.
Disallow: means NO.
Slash means the entire site or account.
Here's what's interesting. You can view them for almost any website or user account on the Internet. Just enter /robots.txt after any domain name or user account.
Here's an example from my Substack:
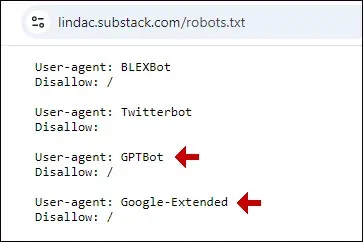
As you can see, my Substack tells ChatGPT and Google's AI, such as Bard and Vertex AI, that they are prohibited from training on my texts in Substack.
Now look at the one for Twitterbot. Do you see that there is no slash?
This means that Twitterbot is not restricted. Twitterbot can read and access everything on my Substack. The slash is very important. It literally means that everything on my account is forbidden.
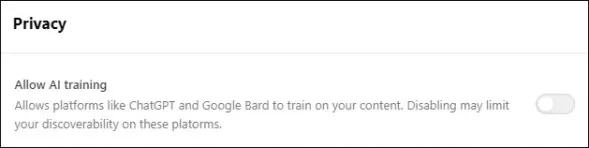
It’s important to know that AI bots are NOT blocked by default on Substack. Substack has “AI training” enabled by default. You need to log in, go to Settings > Privacy, and disable “allow AI training.”
Some websites block the viewing of the robots file on user accounts. I get a 404 error when trying to view the robots.txt file for user accounts on Newsbreak and Vocal Media. However, you can check the robots.txt file on the parent site and assume that the settings for your account are likely the same.
Here are the robots.txt files for Newsbreak and Vocal.
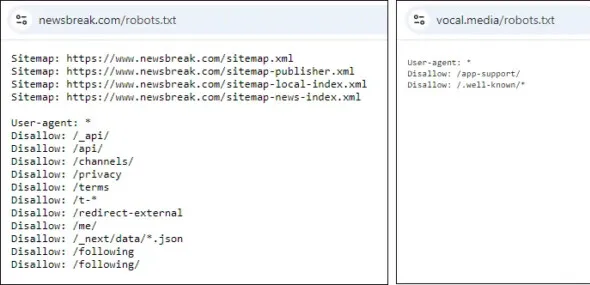
Do you see the asterisk? It means all bots. Newsbreak prohibits all bots from accessing certain directories that do not contain content.
It would be remiss not to tell you about another way to block bots, which is in a file called .htaccess. This file is not publicly viewable. Therefore, I cannot say for sure whether Newsbreak and Vocal provide open access to AI bots. I only know that they do not block them in their robots.txt file.
This makes me wonder. If they are blocking AI training through .htaccess, why not also add this to the robots file, which all robots on the Internet check? The technical staff should know how to do this.
If you write on one of these sites, it might be worth sending a letter to support to find out their position on AI training on your site.
If you have your own site, for example, on WordPress, you have more control than on third-party sites. On your own site, you can block all known AI bots.
There are several ways to access the robots.txt file.
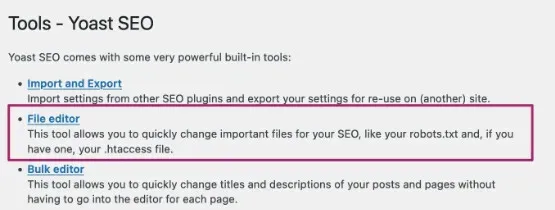
If you use the Yoast SEO plugin, you can access it from the WordPress sidebar at Yoast > Tools > File Editor (Yoast > Tools > File Editor)
If you don't use Yoast but have FTP access, this file is located in the root of the site. And if you don't know what that means and don't understand technical issues at all, that's okay.
If you don't understand the technical details, the free plugin WP Robots Txt is very simple and requires no technical knowledge. Just go to Plugins>Add New. Then enter WP Robots Txt and click the "Install" button.
Once you open the robots.txt file, copy and paste this:
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Omgilibot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Claude-Web
Disallow: /Make sure they appear as in the example. User-agent on one line, disallow on the line below. Make sure there is a slash after disallow. Then save.
And if you can't do anything, contact your hosting support and ask if they can help you. Many of them will help.
There is another robot that you may want to ban, but I will tell you about it separately. It is called Common Crawl and has existed since 2007. Common Crawl was created with the best intentions.
It is a tiny 501(c)(3) non-profit organization run by one person that aims to make a copy of everything on the Internet so that companies and individuals can use it for research and analysis. According to the FAQ, Common Crawl data has been used to improve language translation programs, predict trends, track disease spread, and much more. Created for the good of the cause.
The terms are very clear. They state that users must comply with all local, state, national, and international laws. Users are prohibited from using Common Crawl data to infringe on anyone's intellectual property rights.
But despite these conditions, this is exactly what OpenAI took advantage of. We couldn't independently scan large sites like The New York Times and Wikipedia. We just worked with the Common Crawl database.
This is how a tiny 501(c)(3) non-profit organization run by one person ended up being listed as a key player in the New York Times copyright infringement case against OpenAI.
The fact is, they don't need my articles in their database. I don't have world-changing content, and I'm not setting any global or national trends on my own.
If you want to ban Common Crawl, just insert this into your robots.txt file:
User-agent: CCBot
Disallow: /
I hope the New York Times wins the case. I think other large companies that have been robbed will follow their example. Until some judge tells them they have to comply with intellectual property laws.
Until then, closing doors and windows is the only way out for authors. So check your site if you have one. Check the sites you write on. If they don't block robots, write to them and ask why.









some bots will ignore the robots.txt file,
& commit the heinous scraping anyway
(Anthropic, Perplexity & OpenAI in particular are big offenders).
Others means of protection to investigate would be IP, ASN, &/or UA substring blocking,
tarpit software such as Nepenthes, Locaine, & Quixotic,
rate-limiting, captchas, invisible html tags that assert ownership, & «text watermarking».
Wordpress users may also use Kudurru, for what it's worth.
As far as image & music protection go, those are two other cans of worms, but…
with the earlier one, I can suggest there's alternatives to night-shade such as
Mist v2, Meta-Cloak, Anti-Dreambooth, ArtShield, & Watermark.Ninja,
although I'm unsure about their efficacy.
The IPTC also has made new meta-data tags meant to prohibit AI training, but again, scrapers may still not care…