
- AI
- A
Andrej Karpathy: Swift? Never heard of it! How I wrote an iOS app using pure "please"
What if you could create a mobile app without knowing a single line of Swift? Welcome to the world of vibecoding—the new style of "mood-based" programming, where natural language and LLM replace syntax and compilers.
What if you could create a mobile app without knowing a single line of Swift code? Welcome to the world of vibecoding — a new style of "mood-based" programming, where natural language and LLMs replace syntax and compilers.
In the second part of Andrej Karpathy's talk, we’ll also discuss a new type of “user” — LLM agents (“person spirits”) and how to adapt our infrastructure (documentation, APIs, websites) to suit them using... llms.txt. Are you ready to code “in the flow” and build for non-human intelligences?
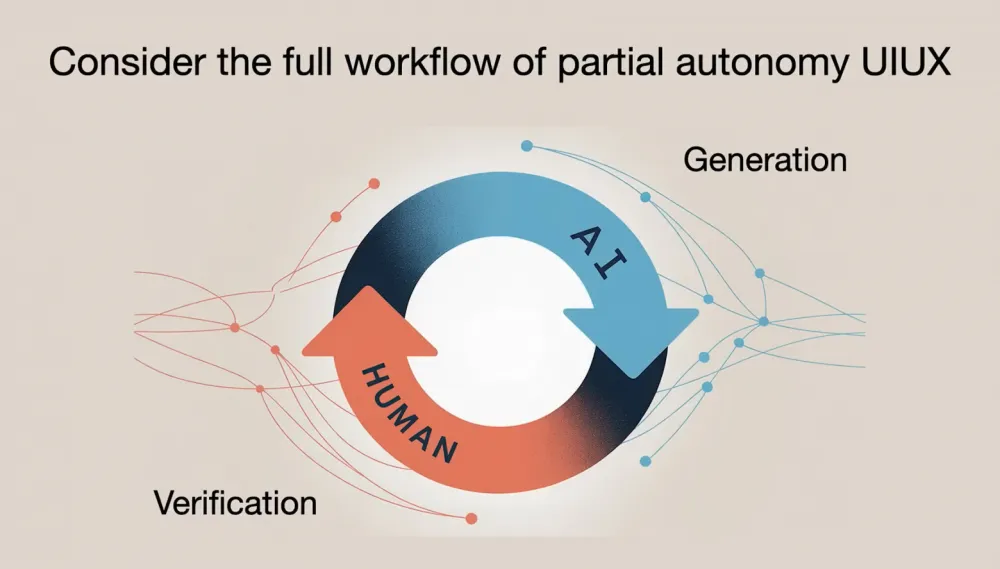
One aspect I want to highlight in the context of working with LLM-powered apps is our new collaboration with AI. Typically, tasks are divided this way: the AI generates, and we, the humans, check. The faster we streamline this interaction, the more we’ll get done.
Like many of you, I’m still figuring out my workflow with AI during programming. In my practice, I avoid huge changes in one go — I prefer to proceed in small, proven steps. My approach to AI-assisted code is careful, gradual edits: I work on small, very specific chunks at a time. I think most of you develop similar techniques.
Prompt vs Result: How to Avoid Disappointment
Not long ago, I came across a few blogs describing best practices for working with LLMs, and one particularly stuck with me. It talked about techniques and tricks that help “keep the AI on a leash.” For example, if your prompt is too vague, the system might not give you what you want — in which case you’ll have to redo the check and reformulate your request. This creates unnecessary work cycles. That’s why it pays to spend a bit longer shaping the details of your prompt up front. The clearer the prompt, the higher the chance the check will be successful and you can move on straight away.
There’s another analogy I want to share. I’m no stranger to partial autonomy — I spent over five years working on it at Tesla. Tesla Autopilot, in essence, is a product with partial autonomy and shares many characteristics with what we’ve just discussed. For instance, right on the dashboard you can see a graphical interface showing what the neural net sees. Of course, there’s also an autonomy slider — over time, as I worked, we added more and more autonomous features for the user.
I’ll tell you a story that captures my thoughts well. The first time I rode in a self-driving car was in 2013: I had a friend working at Waymo, and he offered to give me a ride around Palo Alto. I snapped a photo using Google Glass, which was a real novelty back then and everyone was talking about it. We got into the car and drove for about 30 minutes through streets and on the highway... It all went perfectly: not once during the whole ride did I need to intervene.
And this struck me at the time: it seemed that this was it, the future — autonomous driving was already nearly a reality, as everything was working perfectly. But now, twelve years later, we are still refining autonomous systems, still programming agents for driving. Even if you see Waymo cars driving without a driver, it doesn’t mean the problems are solved: often there’s telemetry or human assistance behind the process. We still can’t claim that we’ve reached the goal — but I think success is just around the corner, even though the path turned out to be much longer than we expected.
The example illustrates well that software development is really complex. And when I hear statements like “2025 will be the year of agents,” I get nervous: I feel like it’s not the year, but the decade of agents, and the work on this will take much more time. We need to involve people in the processes, act carefully and thoughtfully, because this is software, not magic. Let’s take it seriously.
At the same time, we shouldn’t forget that automation is still possible — albeit thoughtful and gradual. In every product you develop, you should anticipate a slider of autonomy. The task is to figure out how to shift it to the right, bringing your app closer to greater independence. It’s these kinds of products that will give birth to many new opportunities.
Vibecoding
Now I want to shift focus to another aspect that seems unique to me — a new type of programming language. This language allows achieving autonomy in software, and as I mentioned, it’s based on a communication language. Suddenly, everyone becomes a programmer because everyone speaks in a natural language. In the past, you had to spend years learning the basics of programming to get anywhere, but now that’s not required.
Have you ever heard of vibecoding? Yes, the name became a meme thanks to a tweet that sparked a whole movement.
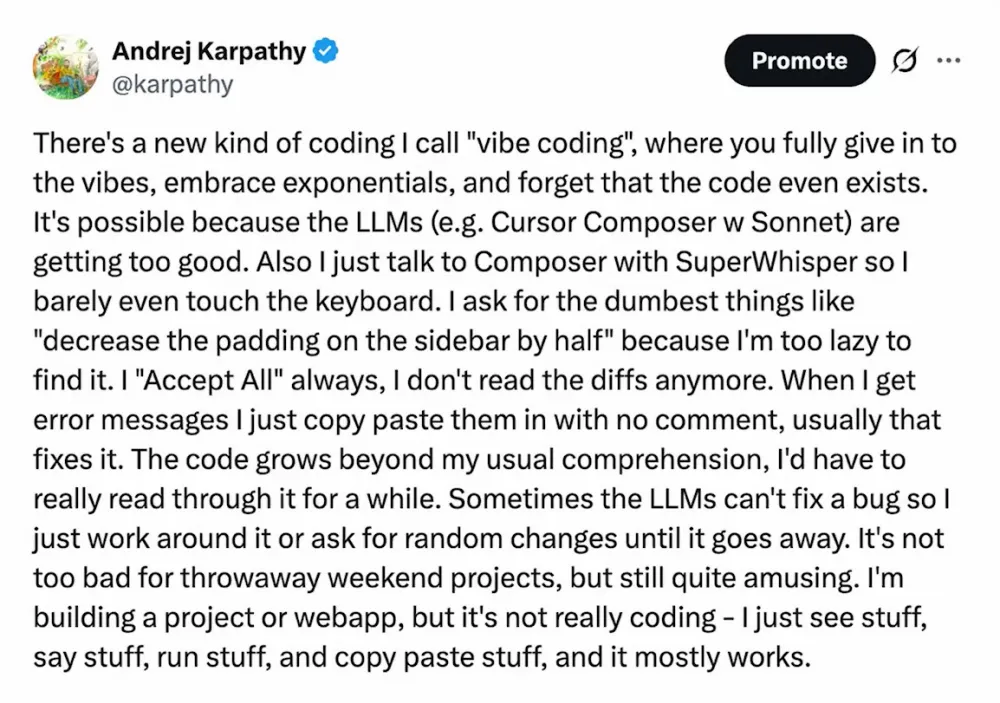
A funny story is that after what seems like fifteen years on social media, I still haven’t learned to predict which tweet will go viral and which one will drown in noise, unnoticed. I thought that particular tweet would just be something inconspicuous — a kind of stream-of-consciousness that was bound to get lost — but suddenly, it became a meme. It seems to have resonated, managed to express what many people felt but didn’t know how to articulate. There’s even now a Wikipedia page — looks like my serious contribution.
Naturally, I had to try vibe coding myself, because it’s insanely fun. Vibe coding is perfect if you want to create something completely unique that hasn’t existed before — and you just want to 'improvise,' especially on a Saturday.
I created a small iOS app. It’s funny that I don’t even know how to program in Swift, but I was amazed at how quickly I could create something at the level of a basic app. Please, don’t expect deep meaning, it’s a pretty silly thing, but the important part is that after just one day, I was able to run it on my phone. And I thought: wow, this is incredible... I didn’t have to spend weeks learning Swift basics or digging through documentation.
Later, I vibe coded another app called MenuGen, and it’s available at https://menugen.app.

The problem I wanted to solve was trivial but annoying. You go to a restaurant, read the menu — and have no idea what the dish names mean. You just need to see pictures. But I couldn’t find any apps like that. So I thought: 'Wait, why not make it myself?' Here’s what I came up with:
With MenuGen, you just take a photo of the menu, and the app generates images of the dishes. Everyone who signs up gets a $5 bonus.
But what really surprised me while working on MenuGen was that the code turned out to be... the easiest part. I made the demo literally in a few hours. The real problem started when I decided to see it through: set up authentication, add payments, buy a domain, ensure deployment flexibility. It all turned out to be painfully hard and had nothing to do with code—just pure DevOps: endless switching between browser tabs, settings, clicks. A grueling, tedious process that stretched on for another week.
Honestly, it was amazing that MenuGen in the prototype stage worked so fast, and that turning it into a real product took so much effort just because the process was so incredibly tedious.
For example, if you try to add Google login to your site, the setup instructions from a library like Clerk will look like a giant wall of text. Here’s an example: an endless list of steps—“Go to this link”, “Choose this dropdown”, “Click here”. The machine is literally dictating every move to me. And I think, “Why can't you, computer, just do it yourself? Why am I wasting my time?!” It’s madness!
Building for Agents
So, the final part of my talk focuses on a question: can we build directly for agents?
Broadly speaking, we’re seeing a whole new category of consumers and manipulators of digital information. In the past, it was just people—through GUIs—or computers—through APIs, but now we have a totally new entity. Agents are, of course, computers, but they’re also... almost like people, right? These kind of “human spirits” living in the network. They need to interact with our software infrastructure. And it’s worth asking: what can we make specifically for them?
Your site might have a robots.txt file telling web crawlers how to behave on your site. Similarly, you can create an llms.txt file—a simple Markdown-formatted text explaining to large language models what your domain is about. Super convenient for LLMs to digest.
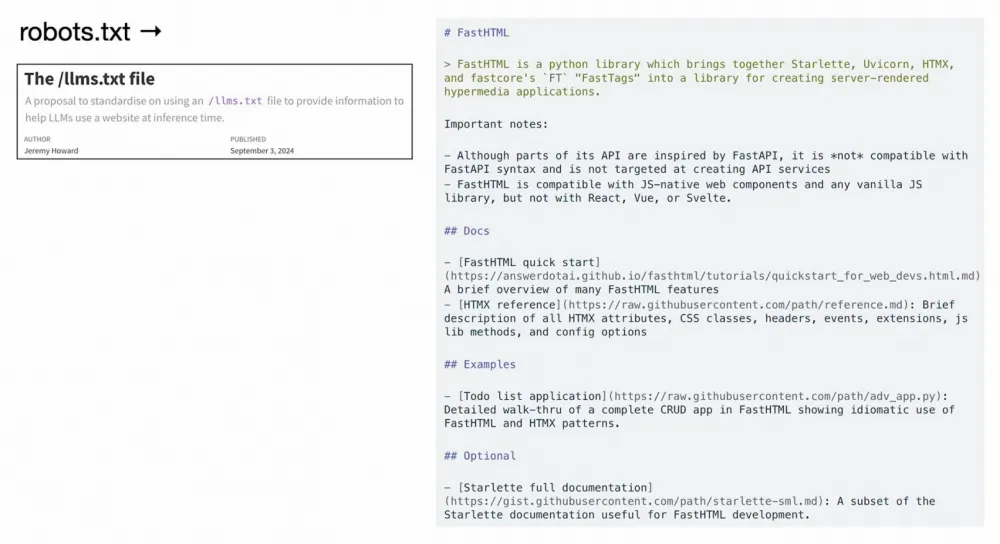
If, instead, the model tries to analyze your site’s HTML, it becomes a much more complicated process, but giving LLMs a format that’s natively digestible is immediately more beneficial. It’s worth it.
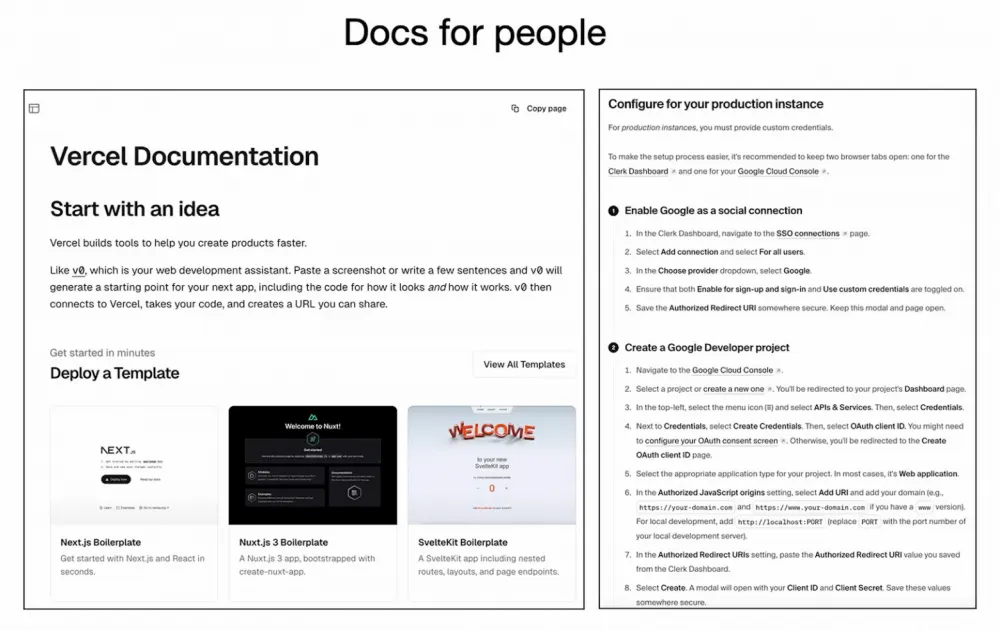
However, some services have started to adapt their technical docs specifically for LLMs. For example, Vercel and Stripe have already been pioneers here, and I’ve seen several other examples. Companies provide their docs in Markdown, which LLMs interpret beautifully.
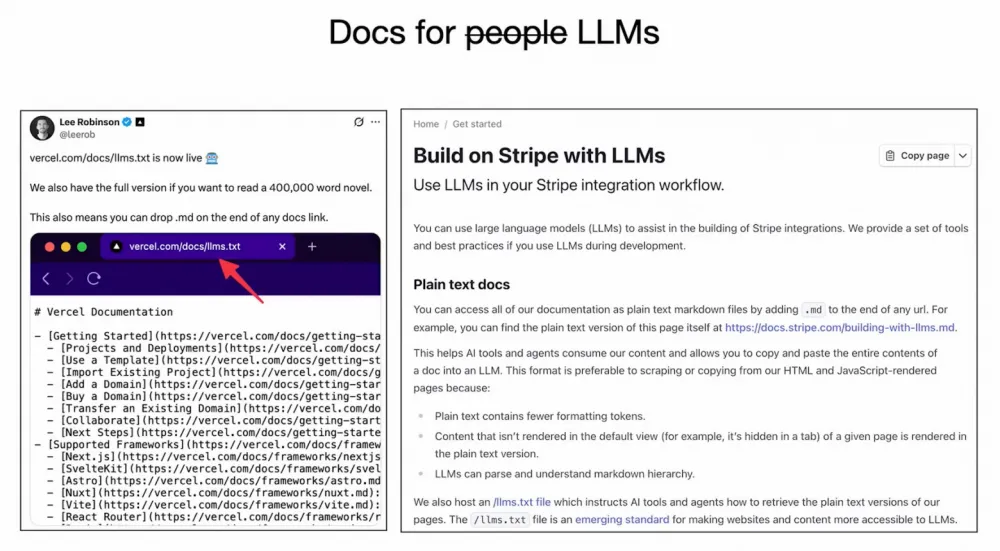
I’ll give an example that makes sense to me personally. Maybe you know 3Blue1Brown — he makes animated videos on YouTube. Yes, I adore this library, Manim, which he wrote. So, one day I wanted to create my own animation — luckily, Manim has detailed documentation on how to use it, but I really didn’t want to spend the time reading through all the details. Instead, I copied the entire documentation, pasted it into an LLM, described what I wanted to get… and it worked! The LLM justcreated the animation I had in mind, on the fly! I was simply amazed; it was incredible.
That’s why, if we make our documentation more accessible for LLMs, we can unlock an incredible number of new possibilities. I think this approach should be adopted everywhere.
One more nuance that’s worth highlighting — the problem isn’t just about converting documentation to Markdown (that’s a pretty simple task); it needs to be modernized, because as soon as you see “Click here” in the docs, there’s an obstacle. For now, LLMs simply can’t perform that sort of action.
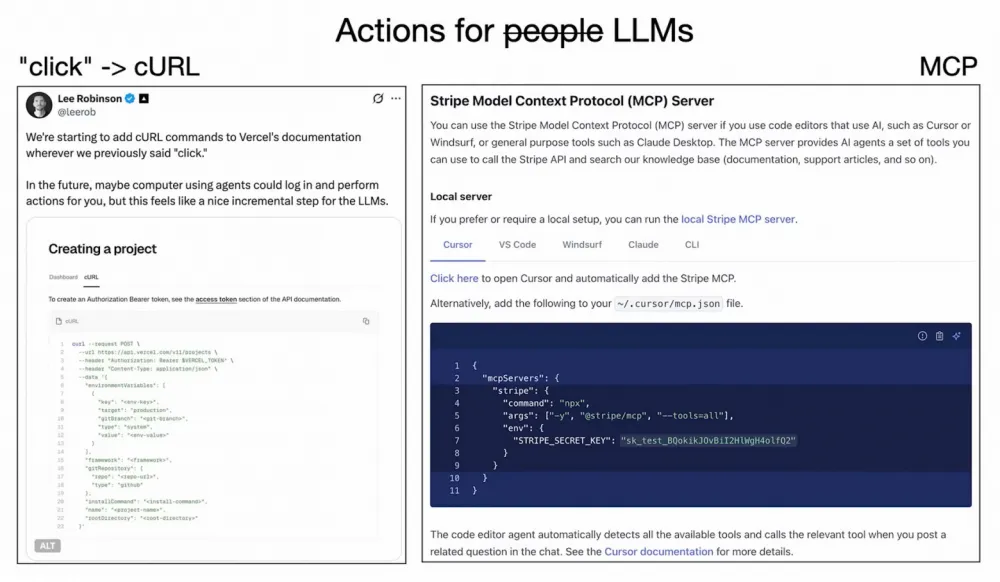
By the way, Vercel replaces any instruction containing the word “click” with an equivalent curl command for agents, which the LLM can execute on your behalf. There’s also something called the Model Context Protocol from Anthropic, allowing direct communication with agents. I truly believe in ideas like this and their potential.
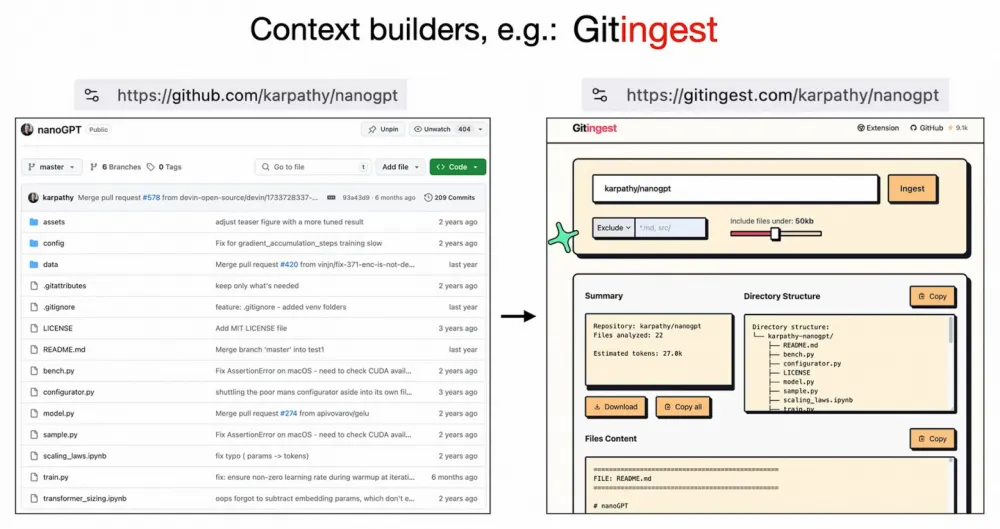
I also like seeing many useful tools appear that make working with data in LLM-friendly formats easier. For example, when I go to a repository on GitHub — say, my NanoGPT — I can’t just feed the repo to an LLM and ask questions directly; after all, GitHub is designed for humans. But if you simply change the link from GitHub to Gitingest, the tool concatenates all the files into a single text, creates a directory structure, and makes it all ready to paste into your favorite LLM. Convenient, right?
Perhaps an even more impressive example is DeepWiki. It’s not just about providing raw data from files. DeepWiki analyzes the contents of a GitHub repository, then creates full-fledged documentation pages designed specifically for LLMs. Imagine how much this could help: copy the text, paste it into the LLM, and get your solution right away. Impressive, isn’t it?

I really appreciate tools like this, where you only need to change the URL and suddenly your data is LLM-accessible. It’s wonderful, and I’m sure we need more of these solutions.
Speaking of working with LLMs in a convenient interface, it’s worth mentioning BotHub. This is a platform where you can run various chatbots (ChatGPT, DeepSeek, Gemini, etc.), as well as image generators (Midjourney, Flux) and video generators (Google Veo, Runway) — all in one system. Try BotHub via this special link — it gives you 100,000 starting tokens!
To sum up…
What an incredible time to enter the industry! We have a massive amount of code to rewrite ahead of us. These LLMs, you could say, resemble utilities, factories, but most of all — operating systems. The comparison is especially apt if you recall the vibe of the 1960s, when operating systems were just emerging. Many analogies from that era resonate perfectly with what’s happening now. LLMs are both powerful tools and, if you like, “spirits of people” that we will have to learn to work with.
To achieve proper interaction with these systems, infrastructure modernization is needed. If you’re building applications using LLMs, I’ve described a few ways to work with them effectively, as well as mentioned some tools that speed up the entire process. The idea is to create products with partial autonomy, focused on speed and ease of interaction. Additionally, you’ll need to write code designed specifically for the new agents.
I myself am insanely curious to see where it all leads. I can’t wait for the moment we build this together with you.
Vibecoding demonstrates the incredible power of natural language programming with LLMs, allowing ideas to turn into working prototypes like MenuGen in just a few hours. The development of LLM-agents requires a fundamental rethink of how we represent information and functionality — through LLM-oriented documentation and specialized tools. We’re at the beginning of a path where the ease of vibecoding meets the challenges of integration, and familiar interfaces adapt to new user-agents. This is a time of experimentation, reimagining, and enormous opportunities for those ready to build not only with AI, but for AI.









Write comment