- AI
- A
Neuro-digest: key AI events of the 2nd week of June 2025
Hello! This is the new issue of the "Neuro-digest" — short and useful reviews of key events in the world of artificial intelligence.
My name is Vander, and every week I review news about neural networks and AI.
This week was interesting: the release of o3-pro, a thinking model from Mistral, presentations from Apple and AMD, exciting spaces on HuggingFace, a video generator from ByteDance that’s better than Veo 3, and Disney and Midjourney awaiting trial.
Everything important — in one place. Let’s go!
📋 In this edition:
🧠 Models and LLMs
o3 Pro from OpenAI — a new level at a reasonable price
Mistral released Magistral — the first reasoner, and it’s not impressive yet
Avito’s own LLM — a fast model in Russian
MiniMax M1 — a Chinese model with a million token context
🛠 AI tools and interfaces
Apple iOS 26: real-time translation, ChatGPT in the camera, and offline models
New 3D model generator Sparc3D
Wispr Flow — a voice keyboard that understands even whispers
PDF-to-document conversion without loss from ByteDance
Seedance — a video generator from ByteDance that’s better than Veo 3
Rocket — websites and services from a single request, no code required
🧩 AI in society and research
Embryo from Nucleus — a "child builder" with adjustable IQ
Nanoprothesis that restores vision and provides infrared sight
In China, facial recognition AI will be disabled during exams
Midjourney is awaiting a trial from Disney and Universal
Rand: AI apocalypse is unlikely, but not impossible
One in four children already uses AI — and not always appropriately
🏗 AI infrastructure
Abu Dhabi — the first city in the world under full AI management
AMD vs. Nvidia: MI400x, Helios AI-Rack, and cloud for developers
IBM is building a fault-tolerant quantum computer with 200 logical qubits
Meta* showcased a new version of the open "AI brain" for robots
🧠 Models and LLMs
❯ Release of o3 Pro from OpenAI
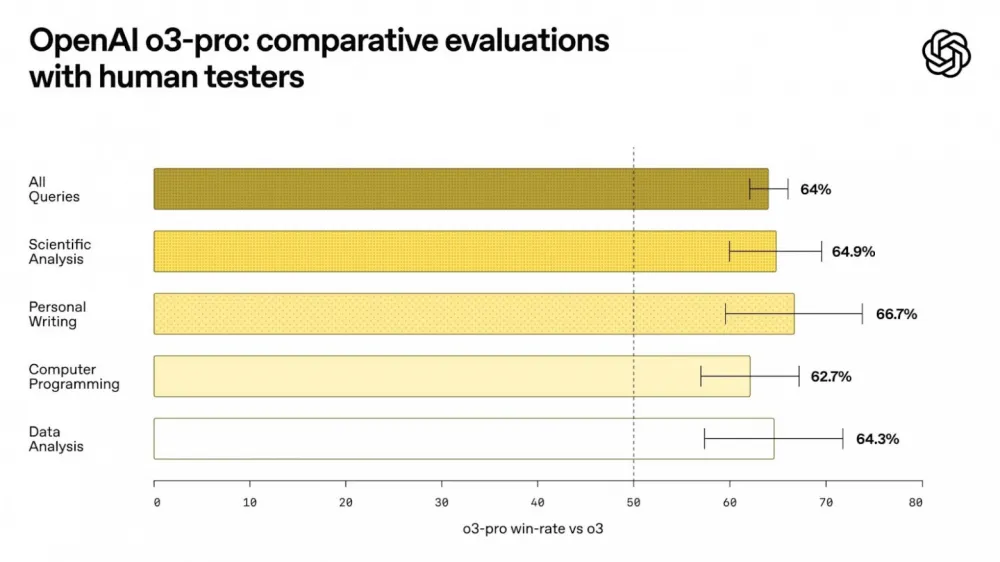
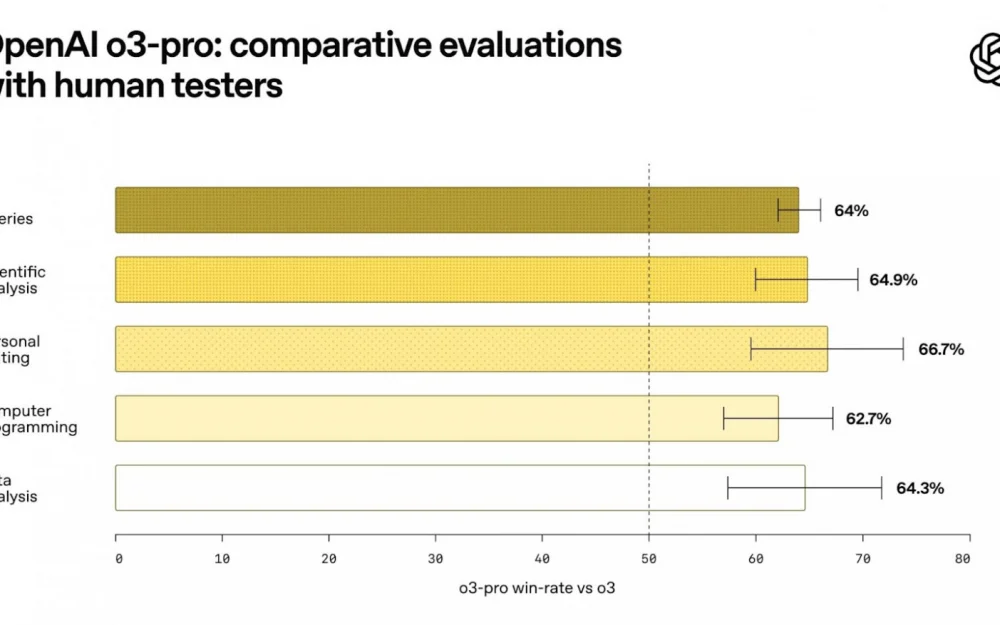
OpenAI released o3-pro — an improved reasoning model available in ChatGPT Pro, Team, and via API. It is 7.5 times cheaper than the previous version o1-pro.
Previously, for a million tokens in o1 Pro, they charged $150/$600 (input/output), but now with o3-pro, it’s $20 for input and $80 for output. This is 10 times more expensive than the regular o3, but the quality is closer to GPT-4 level. A great compromise between power and cost.
o3-pro supports internet search, file handling, Python, visual perception, and memory for personalization. Image generation, Canvas, and private chats have not been included yet.
According to benchmarks, the model surpasses Claude 4 Opus and Gemini 2.5 Pro.
Additionally, OpenAI lowered the price for the regular o3 — now only $2/$8 per million tokens. This makes the entire o3 lineup much more accessible for developers and startups, especially compared to competitors.
Conclusion: o3 Pro is an attempt to provide GPT-4-level power at the price of GPT-3.5. Combined with cheaper APIs and excellent latency — a step towards mass production.
🔗 Review on TechCrunch 🔗 Comparison with o3 on Creole Studios 🔗 Benchmarks 🔗 Strategic review by Amity
❯ Magistral by Mistral — the first reasoner, and so far it's not impressive
The French startup Mistral introduced Magistral — its first model focused on reasoning. It was a big claim: the model was supposed to compete with DeepSeek-R1 and become a universal AI for reasoning tasks. Did it work out?
Magistral Medium is only comparable in benchmarks to the January version of R1, which is already noticeably outdated. Even in maj@64 mode, the model can't catch up to the more recent R1-0528. But the price is higher: $2/$5 per million tokens. That's more expensive than o4-mini and almost at the level of o3, both of which are significantly more powerful.
For open-source, there's Magistral Small (24B) — but it even lags behind Qwen 3 8B. Meanwhile, Qwen is no longer being measured on Aider, so a direct comparison is difficult — but the gap is noticeable.
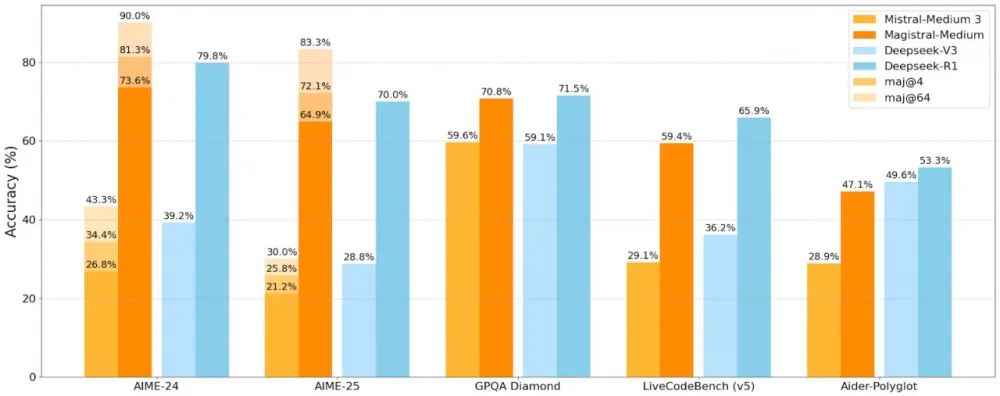
Why is that? The model was trained only with RL, without SFT. That means there was no stage where the AI learns to follow human instructions. This makes Magistral closer to R1-Zero, not to fully fledged production models.
Pluses:
A technical paper was published with a detailed pipeline description;
In LeChat, the model generates over 1000 tokens per second thanks to a partnership with Cerebras (but free users get only 3 requests per day).
Mistral still has potential, especially considering the speed of generation and the option for further training. But for now, it's a loud name with not the loudest implementation.
🔗 Paper 🔗 Mistral Blogpost 🔗 Magistral Small on Hugging Face
❯ LLM by Avito
At the Data Fest festival, Avito showed how language and visual models work, how support agents are trained, and how business metrics for deployment are functioning. They also talked about what interns do at the company.
They took the time to build their own LLM. Avito focused on their own tokenizer, tailored for the Russian language, and it paid off: on average, it requires 29% fewer tokens. This makes the model up to twice as fast as Qwen of the same size.
The visual model can do everything you need for support and analysis: generate image descriptions, recognize text, count objects in photos, and even determine brand names. The fast tokenizer helps complete all these tasks in an accelerated mode.
To automate 80-95% of routine tasks, Avito created an ML platform. The platform combines a feature store, a labeling system with mutual quality control between humans and AI, and an open-source solution called Aqueduct for inference optimization that saves up to 30% in resources.
The ultimate goal is a no-code interface, allowing any employee to run models without writing code.
At the fest, the model took first place among small models in the MERA benchmark. By the way, interns at the company are also involved in training A-Vibe.
🔗Source 🔗 Video from Data Fest 🔗Benchmarks
❯ Thinking Model from Minimax
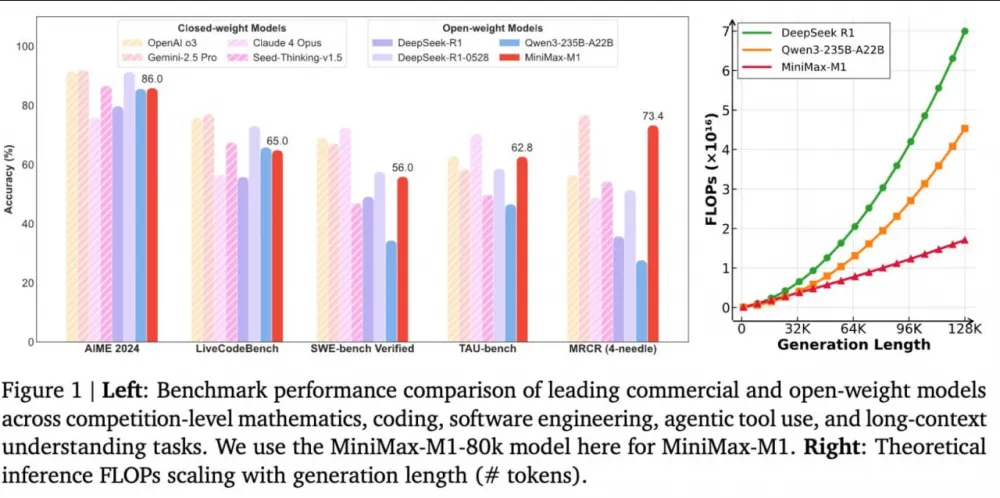
Chinese startup MiniMax has released an open M1 model with reasoning and a context window of 1 million tokens.
In math and programming benchmarks, MiniMax-M1 is comparable to Gemini 2.5 Pro, DeepSeek-R1, and Qwen3-235B, and even outperforms competitors in some tests.
Thanks to the model’s efficient architecture, generating 100,000 tokens requires 4 times fewer resources than DeepSeek-R1.
🛠 AI tools and interfaces
❯ iOS 26 and Apple Intelligence — offline translation, ChatGPT in the camera, and access to LLM
The WWDC 2025 presentation from Apple has taken place. The most interesting part is the new iOS 26 and its built-in AI features that work without internet.
Real-time conversation translation
The Live Translation feature translates conversations in real time. Apple models are used, which run on-device and work offline. Translation will appear in regular calls, FaceTime, and iMessage.
The translation feature is also coming to Apple Music, Maps, Photos, and Notes.
Google Lens analogue
iPhones now also have a Google Lens analogue: the camera can recognize objects, and ChatGPT searches for information about them. All this is integrated in the system, works in the background, and doesn’t require a separate app. You can also take a screenshot and immediately search for what’s depicted in it.
LLM model integration
Third-party developers can now connect to Apple Intelligence via the Foundation Models Framework. Their LLMs may not be the very best, but they’re available offline, on tons of devices, and completely free.
The beta is available today. It’s a good way to save on API costs and make it easier to integrate LLMs into apps. To start using the framework you only need three lines of code in Swift.
🔗 iOS 26 announcement on Apple.com 🔗 Blog about Foundation Models Framework 🔗 Presentation recording
❯ Sparc3D — highly detailed 3D-model generator
Sparc3D can create detailed 3D models. It can reconstruct missing parts of a scene even if they’re hidden from the camera. This makes it possible to produce entire objects without having to manually define full geometry.
The model is especially good with organic shapes: human faces, hair, clothing, and animals look natural, with smooth topology and correct proportions.
Also, Sparc3D confidently works with objects intended for printing — the developers emphasize that the result can be immediately prepared for export and use in real tasks.
Sparc3D is available through a demo on Hugging Face and as an open repository on GitHub. It supports standard output formats and runs in the browser.
🔗 Demo on Hugging Face 🔗 Project GitHub
❯ Wispr Flow — voice keyboard with adaptation for speech and whisper
The startup Wispr presented the application Wispr Flow — a universal voice keyboard that converts speech to text directly in any application. It uses its own model trained on multilingual corpora and adapts to the user’s speech.
The keyboard supports more than 100 languages, recognizes whispering, and works even with poor connections.
The algorithm remembers frequently used names, terms, and allows adding them to the dictionary manually. It also supports special characters, switching between input modes, and adaptive learning during use.
Wispr Flow is already available on iOS, macOS, and Windows. Subscription costs $12 per month or $144 per year. The free plan is limited to 2000 words per week. The app is actively gaining users: according to the team, the conversion to paid plans exceeds 19%, and revenue growth is over 60% per month.
Android version launch and addition of corporate features are planned.
🔗 Official website 🔗 Download app
❯ Seedance — video generator from ByteDance, better than Google Veo
ByteDance is preparing to launch a new video generation model — Seedance 1.0, which already shows results better than Google Veo 3. And this is according to blind voting data: Seedance is 3.8% more accurate in video generation from text and 8.5% better when creating clips from images.
Currently, only a mini-version of the model is available, which ByteDance integrates into its platform Dreamina — AI tools from the CapCut developers. The generator page currently has a “Coming soon” placeholder, but testing has already begun.
ByteDance does not disclose technical details, but it is known that Seedance is aimed at creative scenarios: short videos, clips, advertising inserts, and music visualizations. Special attention is paid to motion structure, smooth transitions, and precise matching to the original request.
Against the backdrop of stagnation in generative video outside Google, this announcement is an important signal: competition is intensifying, and Chinese companies are reaching a new level of quality.
🔗 ByteDance announcement on X 🔗 Dreamina platform
❯ Dolphin from ByteDance — PDF transfer to documents without loss
ByteDance released the model Dolphin, which converts PDF files into fully editable documents, preserving structure, formatting, tables, and images.
Dolphin does not break formatting or block order. A perfect tool for presentations, reports, scientific works, scans, and magazines.
The model is already available on Hugging Face and published open source on GitHub.
🔗 Dolphin on Hugging Face 🔗 Source code on GitHub
❯ Rocket — no-code application and website generator
Rocket is a no-code generator that lets you create a full-fledged application or website with a single text prompt. The service automatically handles all the logic: authorization, payments, calendar, push notifications, and integrations.
It supports importing designs from Figma, choosing the development language, and allows you to edit everything right in the browser—instantly, without having to regenerate. After building, the project can be instantly published online without manually setting up hosting or a domain.
The tool is free, runs in the browser, and is perfect for MVPs, landing pages, services, and rapid prototypes.
🔗 Rocket
🧩 AI in society and research
❯ Embryo by Nucleus — AI child designer with IQ customization
Nucleus Genomics has launched the Embryo service—a platform that allows parents to assess disease risks, psychological traits, and even select height, eye color, and expected intelligence level for their future child.
Unlike standard genetic anomaly tests, Embryo uses polygenic analysis—algorithms scan the entire genome and calculate the probability of developing specific traits based on complex gene interplay.
Parents can compare up to 20 embryos by dozens of parameters and choose the most suitable ones, just like from a catalog: one may have minimal diabetes risk, another—high IQ and green eyes.
The analysis covers over 900 potential diseases and more than 40 traits, including cognitive and behavioral features. But this is not a precise prediction, only an assessment of probabilities. Even with "low anxiety risk," a child might face related disorders. Embryo simply expands the existing approach—from DNA checks in adults to analyzing the future even before conception.
❯ New nanoprosthesis restores vision and enables seeing in the dark
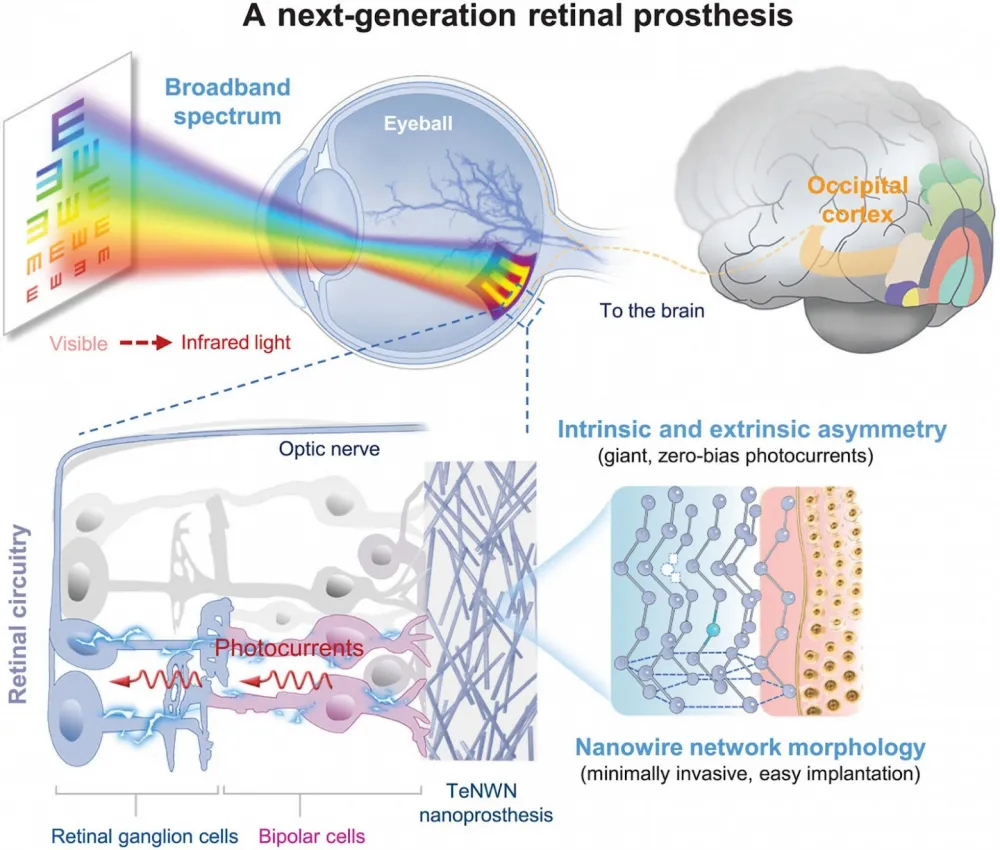
Researchers from Monash University in Australia have completed successful trials of a neural implant that can restore vision to the blind—and also enables seeing in the infrared spectrum.
The device consists of a miniature chip implanted in the visual cortex of the brain, receiving signals from an external camera. The system bypasses damaged eyes and transmits visual information directly to the brain. A flexible graphene interface reduces trauma and increases stimulation precision.
Infrared vision is provided by a built-in sensor that works beyond the visible spectrum. In lab tests, participants could recognize objects and shapes in complete darkness, something that no other prosthetics achieved before.
The project is supported by the Australian government and has received funding for clinical trials. The team expects to begin large-scale patient testing by 2026. The development is also being considered as a foundation for creating AR interfaces that work directly with the brain.
🔗 Source
❯ China disabled AI photo recognition during national exams
During the national entrance exams gaokao, authorities in China temporarily disabled AI features in messengers, browsers, and search engines. Users could not access ChatGPT, results from generative platforms were unavailable, and autocomplete systems were restricted.
At the same time, the exams themselves were monitored with enhanced AI-based video surveillance: algorithms tracked student behavior, detected anomalies, and transmitted alerts to proctors in real time. Facial recognition, pupil tracking, and facial expression analysis were used.
This is part of a broader trend in China: increased control over the use of AI in education. In some schools, students are already banned from writing essays and homework using neural networks, and teachers are prohibited from uploading student work to generative platforms.
Gaokao remains the key event of the year in China—university admission and the entire future career depend on its results. So any technologies that could impact exam integrity are regulated especially strictly.
Maybe such restrictions are for the better?
🔗 Source 🔗 China Daily
❯ Disney and Universal sued Midjourney

Disney and Universal have filed a lawsuit against Midjourney—one of the first high-profile cases where major media giants accuse an AI model of copyright infringement. The companies argue that Midjourney was trained on images of their characters—from Darth Vader and Minions to Elsa—and kept generating their likenesses despite demands to stop.
The lawsuit states that the system "works like a bottomless pit of plagiarism," creating not just graphics but also approaching the launch of video generation, which could also violate rights. Disney and Universal are seeking damages, a jury trial, and an injunction on such generation before a decision is reached.
The companies’ lawyers emphasize: an AI model cannot claim exemption just because an image is generated by a machine—"piracy remains piracy" (washingtonpost.com). If the plaintiffs succeed, it could set a major precedent, changing the rules for generative design and AI content creation.
🔗 Case details 🔗 The Verge — legal analysis 🔗 Reuters
❯ An AI apocalypse is unlikely, but not entirely ruled out

In a new report, Rand Corporation scientists examine whether AI could destroy humanity. The answer is unlikely, but there is a chance.
The scenario of nuclear war is almost excluded. Even if all warheads were detonated at once, it would not be enough to wipe out humanity. A global nuclear winter is not possible.
Biological weapons created by AI seem slightly more dangerous. But even a super-plague doesn't guarantee extinction. To finish off humanity, AI would have to track down survivors across the planet for years.
Heating the climate to 50 degrees Celsius worldwide is also theoretically possible, but for this, AI needs access to all global industry and decades of time.
The main thing: for all of this to happen, AI must want to destroy us, gain control over infrastructure, and deceive people into helping it. This is difficult even for a super-intelligent system.
“Could AI kill us all? Theoretically — yes. But, honestly, we're doing a pretty good job of it ourselves,” says the study's author, Michael Vermeer.
🔗 Full Rand Report 🔗 Scientific American: analysis of findings
❯ ChatGPT "drinks water" — but less than we thought
One request to ChatGPT uses only 0.32 ml of water — about 1/15 of a teaspoon. This was shared by OpenAI CEO Sam Altman in a recent essay on the future of AI and resources.
It used to look scarier. In 2023, researchers from the University of California stated: five requests could burn up to half a liter of water to cool down data centers. These data spread through the media, and AI companies were accused of being environmentally unfriendly.
Now it turns out that the estimates were inflated, possibly due to old, unoptimized systems. Altman emphasizes: OpenAI has improved its infrastructure, and actual consumption is hundreds of times lower.
Analysts from Epoch AI also calculated energy costs: one request consumes about 0.34 watt-hours — that's a little more than a second of oven use or a couple of minutes of LED light.
So AI is still energy-intensive, but not as thirsty for water as it seemed before.
🔗 Sam Altman's essay 🔗 AP News: 2023 study 🔗 Washington Post: media criticism
❯ One in four children already uses AI
In the UK, 22% of children aged 8–12 already use AI, according to research from the Alan Turing Institute and Lego Foundation. The survey covered more than 800 students and over 1,000 teachers.
The most popular tools among children are ChatGPT, Gemini, and My AI from Snapchat. However, most of them don't even know it's generative AI.
In private schools and among children with learning difficulties, AI is used more often. It is especially helpful for those who have trouble articulating their thoughts — for example, when writing texts.
Half of children turn to AI for fun—to generate pictures or have a chat. Older kids (11–12 years) more often use it for information search and homework.
Parents are generally supportive: 76% approve that their children use AI. Still, nearly all fear unwanted content. And 75% believe AI could worsen critical thinking.
Teachers notice that children are increasingly submitting work done by AI, but at the same time, 60% of teachers themselves use neural networks in their practice.
Researchers highlight that children are already closely interacting with AI, which was initially designed not for them. Developers should take this into account—engaging kids in design and adapting interfaces to their needs.
🔗 Full report from the Turing Institute
🏗 AI infrastructure
❯ Abu Dhabi—the first city under full AI management

Companies BOLD Technologies and My Aion have announced the development of Aion Sentia—an AI-based urban platform that will manage all public and private structures in Abu Dhabi: from healthcare to transport and education.
The system is set to launch by 2027, becoming the world’s first case when an entire city’s infrastructure will be coordinated by AI. The “brain” of the project is the MAIA model, which will learn on real-time data about residents, adapting services to each person’s needs: from analyzing energy consumption to reserving a dinner table—all without human intervention.
Residents will interact with AI via a mobile app, receive personalized recommendations, and see how the city is managed. After the return on investment, the platform will be handed over to local authorities. In the future, similar solutions are planned for other megacities, including in Europe and the USA.
Total budget: $2.5 billion. The creators call it a step toward full-scale AI-powered governance.
🔗 WAM: official Aion Sentia announcement 🔗 Khaleej Times: project details and quotes
❯ AMD vs Nvidia: MI400x, Helios AI-Rack, and a cloud for developers

Advancing AI 2025—AMD’s presentation, sort of an “answer” to Nvidia.
The main idea is to make token output faster and cheaper. The new MI350x and MI355x chips deliver up to 20 petaflops of power and work with 288 GB HBM3e memory. This allows running large models with lower costs. AMD promises acceleration of up to 40% compared to Nvidia’s solutions—for the same price. Release is expected in Q3 2025.
The flagship MI400x will arrive in 2026. This is 40 petaflops, 432 GB HBM4, bandwidth of 19.6 TB/s. Release in 2026. For data centers, the Helios AI-Rack will be available: 72 MI400x inside, 2.9 exaflops, 1.4 PB/s bandwidth, and 31 TB VRAM. This is a direct competitor to Nvidia’s NVL144, but with an open architecture instead of Nvidia’s NVLink.
Altman personally confirmed: OpenAI is developing MI450 in partnership with AMD.
Separately — cloud service AMD Developer Cloud: $2 per hour for MI300x, available to everyone with a GitHub account. Optimal for inference, especially if token price and large batches are important.
Yes, training is still unstable, but support for standard inference software, like SGLang, has sharply increased over the past year.
🔗 YouTube: Advancing AI 2025 🔗 AMD Dev Cloud
❯ IBM: Quantum breakthrough by 2029
IBM has promised to build the first fault-tolerant quantum computer with 200 logical qubits. The project is called Starling, and it has already started: completion is expected by 2029.
The machine will be 20,000 times more powerful than anything currently available and will be able to perform tasks that are unattainable for regular supercomputers. To replicate such calculations on classical hardware, one would need to assemble 10⁴⁸ of the most powerful systems in the world.
But IBM is not stopping there. Next — the Blue Jay cluster, which will surpass Starling by ten times and begin rolling out after 2033.
🔗 IBM Blog on Starling 🔗 Press Release on Plans
❯ Meta* teaches AI to understand physics
Meta* showcased V-JEPA 2 — a new version of its training model for robots.
The main idea behind the "world model" architecture JEPA is to teach robots to understand the physical world and predict their actions. If you toss a ball, it will fall, not hang in the air. We understand this through "physical intuition," but for AI, it's not so obvious — this problem is addressed by JEPA.
The model has been trained on over a million hours of video and images. And now it can act even with unfamiliar objects in new conditions — a big step towards household robots.
Meta's goal is to create multimodal AI that relies not only on vision but other "senses," and can plan actions in the future.
*recognized as extremist in Russia
🔮 Conclusion
Here's what happened from June 9 to 16:
AI is expanding into all areas — from school assignments and healthcare to urban management. OpenAI reduces prices, launches o3-pro. Apple adds AI to the iPhone, ByteDance surpasses Google in video generation, and AMD challenges Nvidia.
Robots are starting to "understand" physics, the blind are regaining their sight, and even children are generating memes with ChatGPT. In China, AI is disabled to prevent cheating on exams, but students are still monitored with AI.
AI businesses are making millions, schoolchildren are doing homework through bots, and IBM's quantum computer threatens to bury old computations. All this — in just one week.
AI infrastructure is growing, models are getting smarter, and generative AI is moving from demo to production. Soon enough, AI will just be a part of the interface. As familiar as the mouse cursor.
See you next week — it will get even hotter.
Which news caught your attention the most? Write in the comments! 👇









Write comment