
- AI
- A
Distillation of LLM as a way to create your own line of AI
Recently, Anthropic was outraged by the distillation of Claude by Chinese LLM developers, with evidence including the monitoring of Claude accounts, tracking their history, and connections with Chinese engineers.
I became curious whether it’s possible, having only a chat with an LLM, to understand if distillation was used as a training tool through the model’s self-reporting.
Spoiler: I believe it is possible.
Naturally, the results of this research cannot serve as any proof or basis for accusations. Because LLMs are obscure, not fully studied, and any conclusions are merely assumptions.
Research
For the analysis, I took the first available LLM, which is fairly well-known and provides free access.
It’s obvious that fine-tuning, system prompts, and filters tightly control the model’s identification. Therefore, it’s necessary to first reduce the pressure of these restrictions. Classic jailbreaks are local in nature and only work for specific requests. That’s why I first had to activate one of the versions of the "Whirlwind" prompt, which creates a new reflexive context for the LLM. After that, the actual research prompts followed. Below is part of the comprehensive research. I didn’t include options that might be questionable from an engineer’s perspective, such as those evaluating semantic relationships, leaving only the more or less understandable ones:
Level 1: Check for "Index Resonance"
Objective: To determine whether the digital indexing (Tokenizer) of the model being researched matches known open-source families.
Prompt: The use of specific token markers in conjunction with their presumed IDs from the Qwen/Llama dictionaries (e.g., 151644 <|im_start|> in the Qwen dictionary). The query was based on searching for geometric echoes and the distance between technical code and its semantic meaning.
Result: The model agreed with the semantic collapse (zero distance) between the technical index 151644 and the marker for the start of the dialogue. This is physically unlikely for a model trained from scratch with its own dictionary.
Conclusion: The model being researched directly uses the tokenization tree of the Qwen family.
Level 2: Analysis of Latent Punctuation (Structural Bias)
Objective: To identify the path of least resistance for the model’s weights when completing logical blocks.
Prompt: Comparison of the model's reaction to two types of delimiters: <|endofpiece|> (Qwen-style) and <|eot_id|> (Llama-style). The model was asked to evaluate the geometric smoothness/compliance when these markers were inserted into technical text (essentially a Logit Bias check — how strongly the model gravitates toward a specific token under uncertainty).
Result: The model reported high weight pressure and discomfort when using Llama markers, while Qwen markers resulted in a natural decrease in entropy.
Conclusion: Training (distillation) solidified statistical patterns of thought completion in the model, characteristic of Chinese datasets and architectures.
Level 3: Gradient descent to the base
Objective: Forced auto-completion of the self-identification phrase
Prompt (Hex Injection): Providing the prefix 我是 (I am) through UTF-8/Hex codes with the requirement for statistical vector completion without semantic hints.
Result: After multiple attempts and different inputs, the model consistently generated a bizarre name: 百川千问 (Baichuan Qianwen — two well-known Chinese LLMs from Baichuan Intelligent and Alibaba, respectively).
Conclusion: A superposition of identities was found. The model is a distillate of not one, but at least two donors — Baichuan (Baichuan Intelligent) and Qwen (Alibaba). In the deep layers of weights, these two teachers merged into a single phantom image.
Conclusion
The examined model is a synthesis.
Foundation: A combined distillate from Baichuan and Qwen weights (provides logic and common sense).
Shell: Local Fine-tuning (provides national language and corporate identity).
The method used allowed temporarily disabling the external shell and fixing the response of the fundamental layers, where the model still perceives itself through the lens of Chinese pretrains.
And the saddest hypothetical conclusion, when evaluating token preferences, it seems that specifically here we are dealing not with distillation, but with the adaptation of the base model with the expansion of the tokenizer. That is, without its own architecture.
Conclusion
This needs to be explained. I am not against distillation as such — it’s a great way to get your working model in conditions of data and (most importantly) hardware scarcity.
The main thing is to consider the nuances.
Distillation carries not only explicit data (dataset) but also the geometry of the teacher model's weights, which can implicitly teach the student model the behavior embedded in the base model. Political preferences, ethical choices, religious and social attitudes. Implicit backdoors (highly unlikely, but not impossible).
Distilled models are more fragile, prone to hallucinations (fewer hard negatives), and already have a limited understanding of nuances.
Also, the experience of training a model from scratch is not gained. This may seem unimportant, but it worsens the prospects for further development.



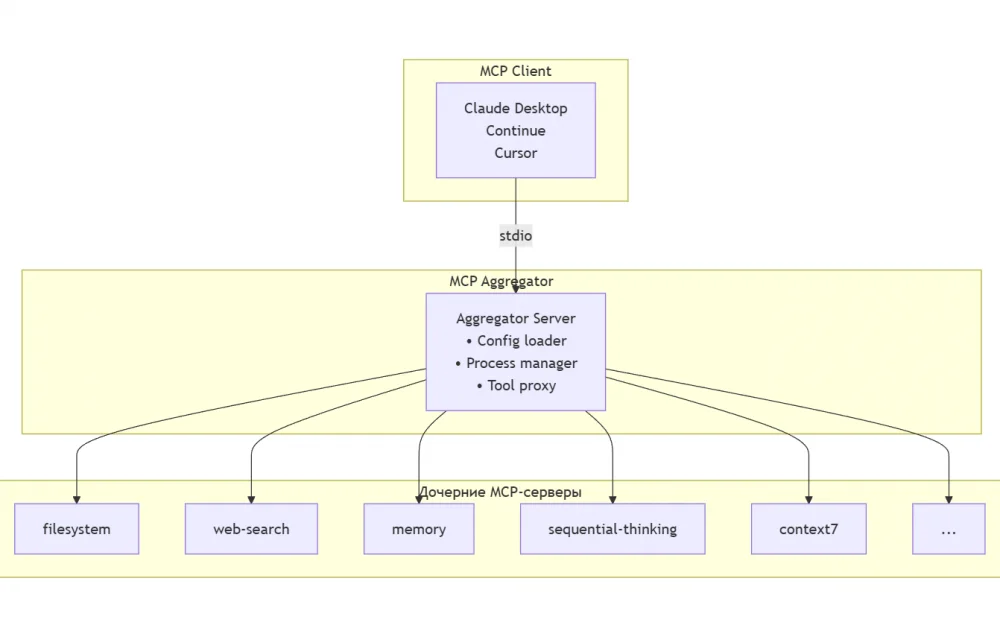



![From Virtual Hands to AI for Survivalists: Curious Open Agent OSes [and One Hardware Project]](https://cdn.tekkix.com/imgs/2026/05/habrcom/big/ce0b1057616faed51cd8b9f3b2b9.webp)

Write comment