
- Hardware
- A
Considering the processor cycles in the CH32x035 controller
When I have to start working with a new microcontroller, I usually look at its GPIO performance. How many cycles per write it actually takes. This is my tradition. Once, I found out that Chinese clones of STM32 work with GPIO slightly faster than the original. For cheap controllers, such checks usually do not reveal anything more interesting, but tradition is tradition. I did not change it when I started mastering the CH32x035 based on RISC-V. And for it, the pictures turned out to be so interesting that I decided to share them with the public. Not that there was anything revolutionary, but they are definitely different from what I am used to.
And I will also add some conclusions to them... And I have a gut feeling that in the comments I will be explained that I understand everything wrong, but in fact... But I will only be glad to reasoned statements. Together we will establish the truth.
A little bit of theory
When I told my colleagues about my conclusions, everyone felt it was their duty to say: "Forget about cycles, in modern controllers everything is so complicated that counting cycles is pointless." They are, of course, right... But not quite. Once, I played with Cortex A9 as part of the Cyclone V-SoC FPGA, and there was a complete mess. A bunch of buses. Bridges with buffers for 7 transactions between them. Different caches on different buses... There, yes. It was impossible to get the same result twice in terms of cycles from run to run. Here the system is much simpler. But let's first figure out what we have. What we can expect from it.
The CH32x035 controller is the ideological successor of the STM32. For example, when something in the Chinese documentation on its peripherals is unclear to me, I open the document on the branded STM32F103 and look at the pictures or descriptions in it. It is clear that this is no longer a clone, in which only the processor core was changed. But the ideology's roots come from STM32. And since the hardware idea is inherited, so is the description idea. So there are a couple of documents for it: Reference Manual and Datasheet. You can download them here: https://www.wch-ic.com/products/CH32X035.html
Just as ST engineers do not describe system-wide things in a similar pair of documents (even SysTick), here too, for system-wide things, manufacturers require referring to the core document. They say, look for QingKeV4_Processor_Manual. Google finds it here: https://www.wch-ic.com/downloads/QingKeV4_Processor_Manual_PDF.html
And now let me summarize the key points. First. We have no cache. This follows from a chain of facts scattered across two documents:

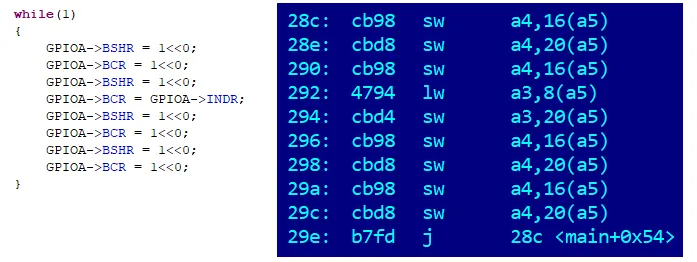
This code writes to the Bit Set Register and the Bit Clear Register. We either set or clear a bit in the port. In assembly, it looks like this chain of commands:
We see typical groups of four ones and four zeros. Let's continue to show one group at a time, indicating the number of cycles corresponding to the period of each of its elements. So:
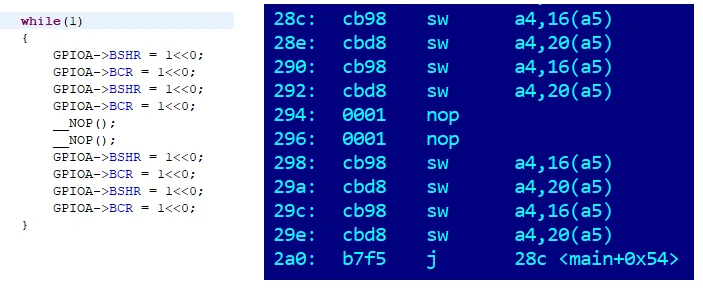
We get:
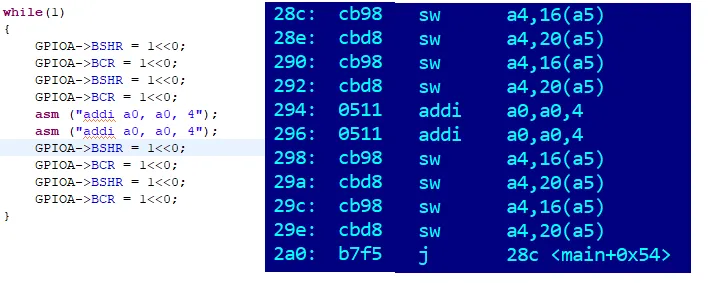
The oscillogram is not provided, it is no different from the previous one. Four cycles per pair of commands. That is, two per command!
Disabling accelerators
When I presented the calculations to my colleagues, they began to advise me to find out what the current mode of the prefetch system is, and whether branch predictors are enabled. Actually, a good question! Only nowhere in the documentation is it described how this can be checked. But two heads are better than one! One meticulous colleague reasoned as follows: Here we have a line in the Startup code:
For the same reason (increased volume), I will say that only the case when everything is disabled is of particular interest for the review article. Both prefetch and predictors. Then the oscillogram for the last version of the source code looks like this:
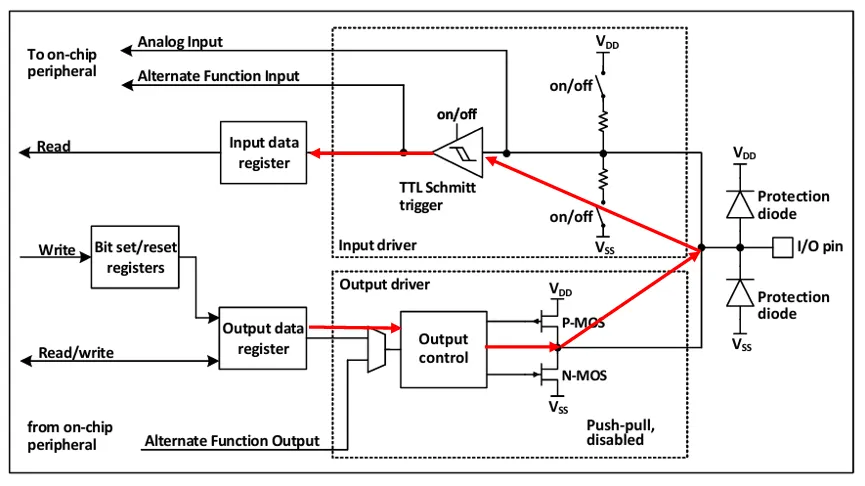
Therefore, if there is a unit in the port, writing the contents of the Input Data Register to the Bit Clear Register will reset the current pin, not using a constant from the program, but using the bit mask read from the port. Thus, we will definitely trigger a read transaction. Shall we?
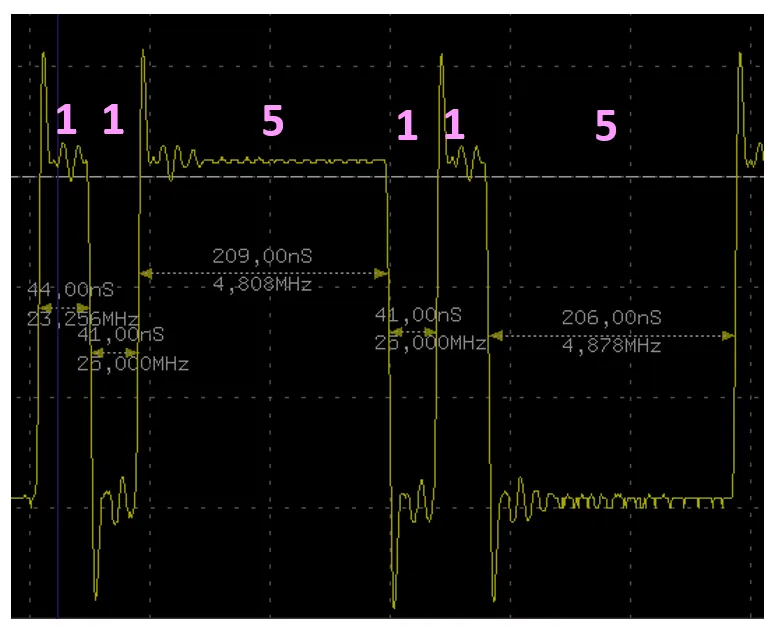
What nonsense? Where is another drop? I have a feeling that the read transaction started before the write transaction was completed. So the bit was not cleared. We disable prefetching (instead of the constant 0x1f, we write the constant 0x1c to CSR 0xbc0). We do not change anything in the code, we get:
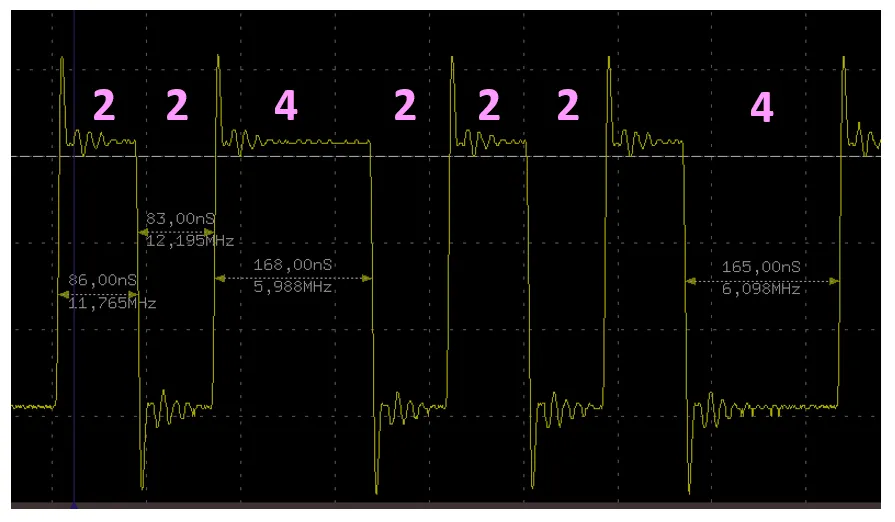
Hooray! Not only does everything work, but the reading is done in the same number of cycles as the writing (2 cycles). In STM32, the hardware creates such a slowdown in this place! But there are no such problems. Here, we conclude that the applied accelerators are good for calculations, but not for pin control. Which is actually strange, because in controllers, unlike simple processors, predictability is more important. Okay, we increase the frequency back to 48 MHz. We do not change the code again. We also leave the accelerators turned off.
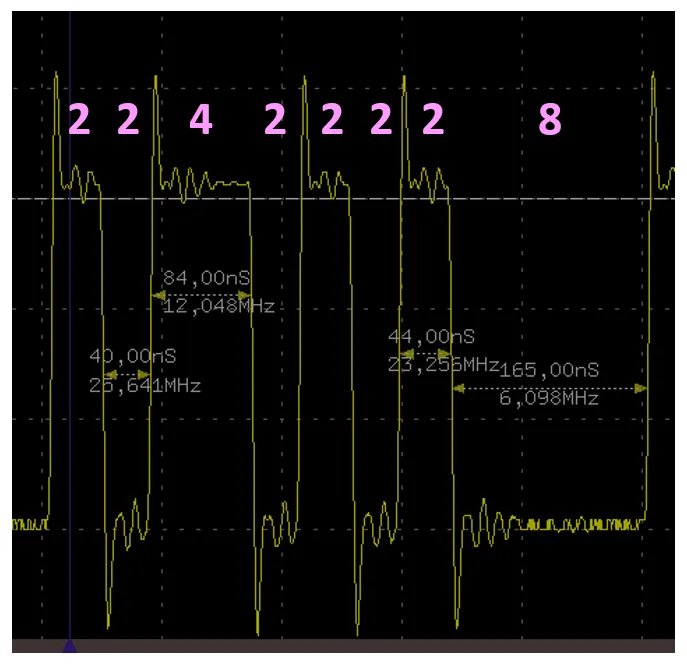
No glitches, while the performance has increased again. Branching in nanoseconds is performed in the same way as in the case of 24 MHz, but in cycles - longer.
Conclusion
The article shows that in general, the clock frequency of 48 MHz for the CH32X035 controller does not provide advantages for the processor core compared to the clock frequency of 24 MHz. It can be useful for accurately setting the UART frequency, for higher timer accuracy, but not for command execution. Commands will be executed at a frequency of 24 MHz.
Most likely, this is caused by the latency of flash memory at the maximum frequency. At the same time, prefetch accelerators cannot provide full pipeline loading, but create uneven operation. At a frequency of 24 MHz, the effect of accelerators is already beginning to manifest itself, although it is not a fact that it is fully, because zero latency, according to the source codes, is activated only at a frequency of 16 MHz.
But if there is work with ports, not separated by other commands, all these accelerators are evil. The article shows that in one case, the system managed to read data from the ports before the previous ones had time to write to them. To prevent such situations, it is better to set the clock frequency to 48 MHz, but disable command prefetching (in the code shown in the article, the constant 0x1f, not recommended by the manufacturer, is written to CSR 0xbc0, and the constant 0x1c).
Those who wish can continue research at lower frequencies, where latency becomes zero, but the author is not so interested in low frequencies of the processor core. Perhaps it is there that the branch predictor will begin to work at full capacity. But maybe, for this it is necessary to make the frequency ratio on the system bus and the APB bus different from 1. But such modes are also not of interest to the author, so they were not considered.



![From Virtual Hands to AI for Survivalists: Curious Open Agent OSes [and One Hardware Project]](https://cdn.tekkix.com/imgs/2026/05/habrcom/big/ce0b1057616faed51cd8b9f3b2b9.webp)


Write comment