
- Network
- A
How Linux creates and counts sockets
Details about what happens under the hood in the Linux kernel when you make the next system call when working with sockets.
Hello!
If you already have some experience with web servers, you have probably encountered the classic situation "address already in use" (EADDRINUSE).
This article will not only detail the prerequisites that allow you to judge whether such a situation will occur in the near future (for this, it is enough to view the list of open sockets), but also explain how you can trace specific code paths in the kernel (where such a check occurs).
If you are simply curious about how the socket(2) system call works, where all these sockets are stored, then be sure to read this article to the end!
❯ What are sockets?
Sockets are constructs through which communication between processes running on different machines is provided, and this communication takes place over a network that is basic for all these processes. It also happens that sockets are used for communication between processes running on the same host (in this case, we are talking about Unix sockets).
A very accurate analogy illustrating the essence of sockets and truly impressing me is given in the book Computer Networking: A top-down approach.
In the most general sense, you can imagine a computer as a "house" with many doors.
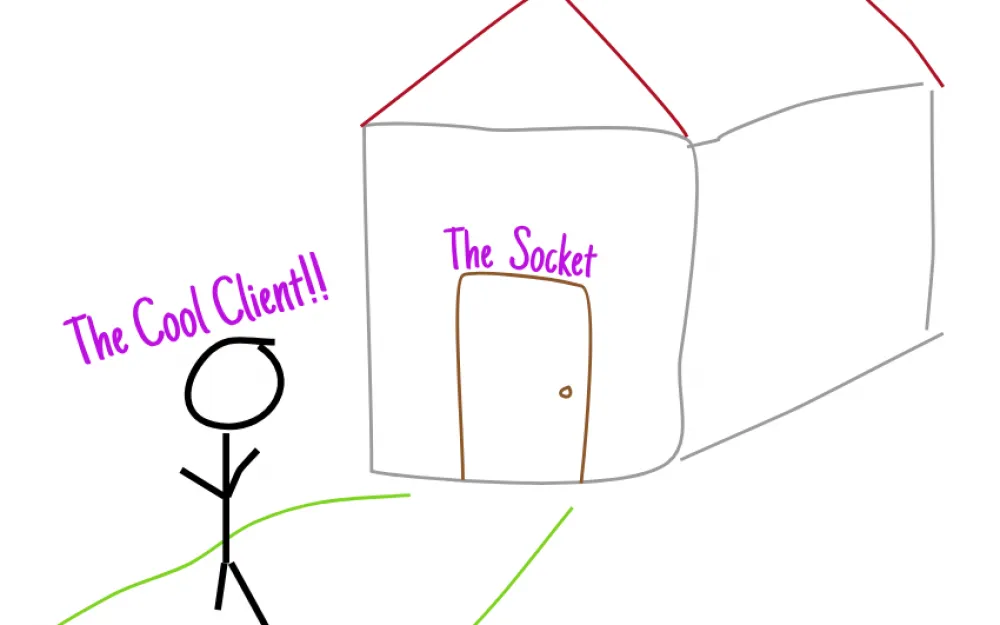
Here, each door is a socket, and as soon as a client approaches it, they can "knock" on it.
Immediately after a knock on the door (sending a SYN packet), the house automatically responds to it by issuing a reply (SYN+ACK), which it then confirms itself (yes, such a smart house with a "smart door").
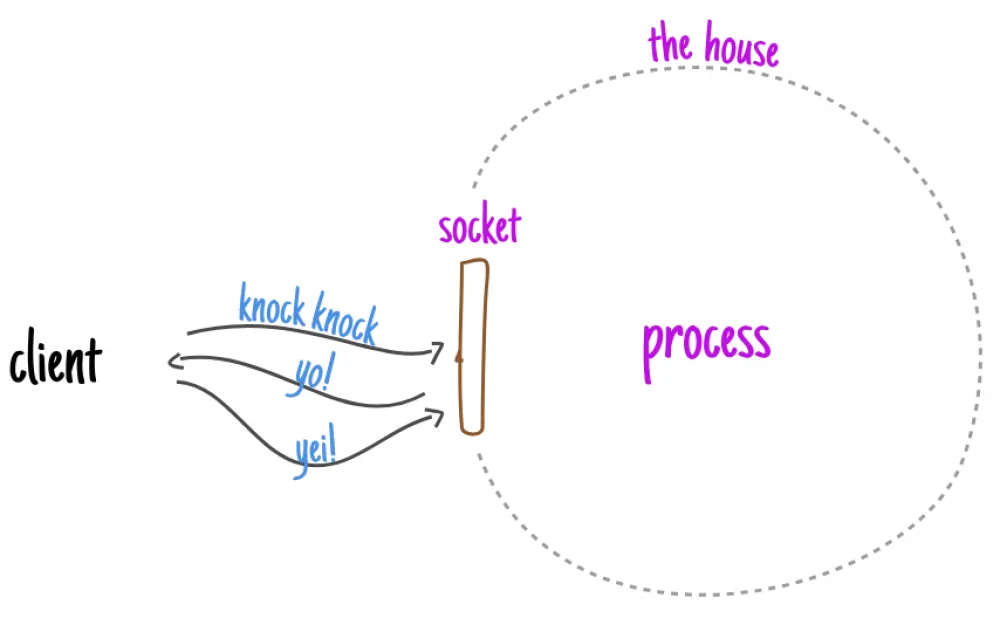
Meanwhile, while the process itself is just sitting there in the house, the "smart house" coordinates the work of the clients and builds two queues: one for those who are still exchanging greetings with the house, and another for those who have already completed the greeting stage.
As soon as those or clients are in the second queue, the process can let them in.
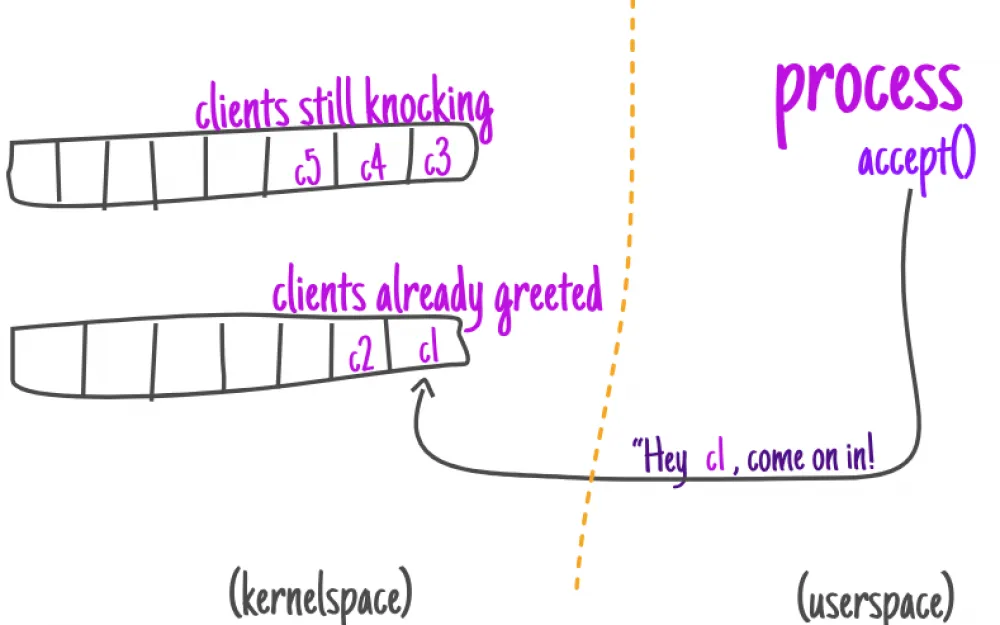
When the connection is considered accepted (the client is told to enter), the server can communicate with the client, sending and receiving data depending on what is required.
It is worth noting here that the client is not actually "let into" the house. The server creates a "private door" (client socket) in the house, and then communication with the client goes through it.
This article will be clearer if you step by step imagine how a TCP server is implemented in C. If this topic is not yet very familiar to you, be sure to study the article "Implementation of a TCP server".
❯ Where can I find a list of sockets available on my system?
Once you have an idea of how exactly a TCP connection is established, we can "enter the house" and explore how the machine creates these "doors" (sockets). We will also find out how many doors we have in the house and in what state each of them is (closed or open).
For this, let's take as an example a server that simply creates a socket (a door!) and does nothing with it.
// socket.c – creates a socket and then sleeps.
#include
#include
/**
* Creates a socket for TCP IPv4 communication, then goes into
* waiting mode.
*/
int
main(int argc, char** argv)
{
// The system call creates an endpoint for further
// communication, and then returns a file descriptor referring to
// this endpoint.
// It takes three arguments (the last one is provided for more
// specificity):
// - domain (within which communication takes place)
// AF_INET Internet protocols IPv4
//
// - type (communication semantics)
// SOCK_STREAM Provides properly ordered
// reliable bidirectional byte streams,
// based on connection type
int listen_fd = socket(AF_INET, SOCK_STREAM, 0);
if (err == -1) {
perror("socket");
return err;
}
// Just wait ...
sleep(3600);
return 0;
} Under the hood, such a simple system call triggers a whole bunch of internal methods (more on them in the next section), which at some point will allow us to look for information about active sockets, recorded in three different files: /proc/, /proc/, and /proc/.
While the fd directory lists the files opened by the process, the /proc/ file reports which active TCP connections (in various states) currently exist, related to the network namespace of this process. On the other hand, the sockstat file can be considered a kind of summary.
Starting from the fd directory, it becomes noticeable that after calling socket(2), the socket file descriptor appears in the list of similar descriptors:
# Run socket.out (gcc -Wall -o socket.out socket.c)
# and leave it running in the background
./socket.out &
[2] 21113
# Make sure these are the open files used by the process.
ls -lah /proc/21113/fd
dr-x------ 2 ubuntu ubuntu 0 Oct 16 12:27 .
dr-xr-xr-x 9 ubuntu ubuntu 0 Oct 16 12:27 ..
lrwx------ 1 ubuntu ubuntu 64 Oct 16 12:27 0 -> /dev/pts/0
lrwx------ 1 ubuntu ubuntu 64 Oct 16 12:27 1 -> /dev/pts/0
lrwx------ 1 ubuntu ubuntu 64 Oct 16 12:27 2 -> /dev/pts/0
lrwx------ 1 ubuntu ubuntu 64 Oct 16 12:27 3 -> 'socket:[301666]'Given that a simple call to socket(2) does not establish any TCP connection, we will not find or gather any important information from /proc/.
From the summary (sockstat), it can be inferred that the number of allocated TCP sockets is gradually increasing:
# Let's look at the file that contains information about the socket.
cat /proc/21424/net/sockstat
sockets: used 296
TCP: inuse 3 orphan 0 tw 4 alloc 106 mem 1
UDP: inuse 1 mem 0
UDPLITE: inuse 0
RAW: inuse 0
FRAG: inuse 0 memory 0To ensure that the number of alloc indeed increases during our work, let's modify the above code and try to allocate 100 sockets at once:
+ for (int i = 0; i < 100; i++) {
int listen_fd = socket(AF_INET, SOCK_STREAM, 0);
if (err == -1) {
perror("socket");
return err;
}
+ }Now, checking this parameter again, we will see that the number of alloc has indeed increased:
cat /proc/21456/net/sockstat
bigger than before!
|
sockets: used 296 .----------.
TCP: inuse 3 orphan 0 tw 4 | alloc 207| mem 1
UDP: inuse 1 mem 0 *----------*
UDPLITE: inuse 0
RAW: inuse 0
FRAG: inuse 0 memory 0❯ What exactly happens under the hood when the socket system call is executed?
socket(2) is like a factory that produces basic structures designed to handle operations on such a socket.
By using iovisor/bcc, you can trace all the calls happening in the sys_socket stack to the maximum depth and, based on this information, understand each step.
| socket()
|--------------- (kernel boundary)
| sys_socket
| (socket, type, protocol)
| sock_create
| (family, type, protocol, res)
| __sock_create
| (net, family, type, protocol, res, kern)
| sock_alloc
| ()
˘Starting with sys_socket itself, this system call wrapper is the first layer affected in kernel space. It is at this level that various checks are performed and some flags are prepared for use in subsequent calls.
Once all preliminary checks are completed, the call allocates a pointer to struct socket in its own stack — a structure that contains non-protocol-specific details about the socket:
/**
* A socket is defined as a system call
* with the following arguments:
* - int family; - the domain in which communication takes place
* - int type; and - the semantics of communication
* - int protocol. – a specific protocol within
* a given domain and semantics.
*
*/
SYSCALL_DEFINE3(socket,
int, family,
int, type,
int, protocol)
{
// A pointer that should be directed to
// a structure that contains the full definition
// of the socket after it has been properly allocated from
// the socket family.
struct socket *sock;
int retval, flags;
// ... information is checked, flags are prepared ...
// Basic structures for working with sockets are created.
retval = sock_create(family, type, protocol, &sock);
if (retval < 0)
return retval;
// A file descriptor is allocated for this process so that
// it can consume the specific socket of interest from
// user space
return sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK));
}
/**
* High-level wrapper for socket structures
*/
struct socket {
socket_state state;
short type;
unsigned long flags;
struct sock* sk;
const struct proto_ops* ops;
struct file* file;
// ...
};Given that we are currently creating a socket, and we can choose from various types and protocol families (e.g., UDP, UNIX, and TCP), this is why the struct socket contains an interface (struct proto_ops*) that defines the basic constructs implemented by the socket. These constructs are independent of the type and protocol family, and this operation is initiated by calling the method that follows: sock_create.
/**
* Initializes by allocating the necessary
* memory for it, as well as filling in
* all the necessary information related to
* the socket.
*
* Method:
* - Checks some details related to the arguments;
* - Performs the planned security check for
* - Initializes the memory allocation operation itself for
* (so that it performs it according to the rules that apply to it)
*/
int __sock_create(struct net *net,
int family, int type, int protocol,
struct socket **res, int kern)
{
int err;
struct socket *sock;
const struct net_proto_family *pf;
// Checks the protocol range
if (family < 0 || family >= NPROTO)
return -EAFNOSUPPORT;
if (type < 0 || type >= SOCK_MAX)
return -EINVAL;
// Initiates its own security checks for socket_create.
err = security_socket_create(family, type, protocol, kern);
if (err)
return err;
// Allocates the object and binds it to the file,
// located in the file system.
sock = sock_alloc();
if (!sock) {
net_warn_ratelimited("socket: no more sockets\n");
return -ENFILE; /* Not quite an exact match, but this is the closest
analog available in posix */
}
sock->type = type;
// Attempts to retrieve the protocol family methods to
// create a socket according to the rules specific to this family.
pf = rcu_dereference(net_families[family]);
err = -EAFNOSUPPORT;
if (!pf)
goto out_release;
// Executes the socket creation method specific to
// this protocol family.
//
// For example, if we are working with the AF_INET family (ipv4)
// and we are creating a TCP socket (SOCK_STREAM),
// then a specific method is called to handle the socket
// of this type.
//
// If we were specifying a local socket (UNIX),
// then another method would be called (provided that
// such a method would implement the interface
// and such a method would be loaded).
err = pf->create(net, sock, protocol, kern);
if (err < 0)
goto out_module_put;
// ...
}Continuing this detailed study, let's take a closer look at how the struct socket structure is allocated using the sock_alloc() method.
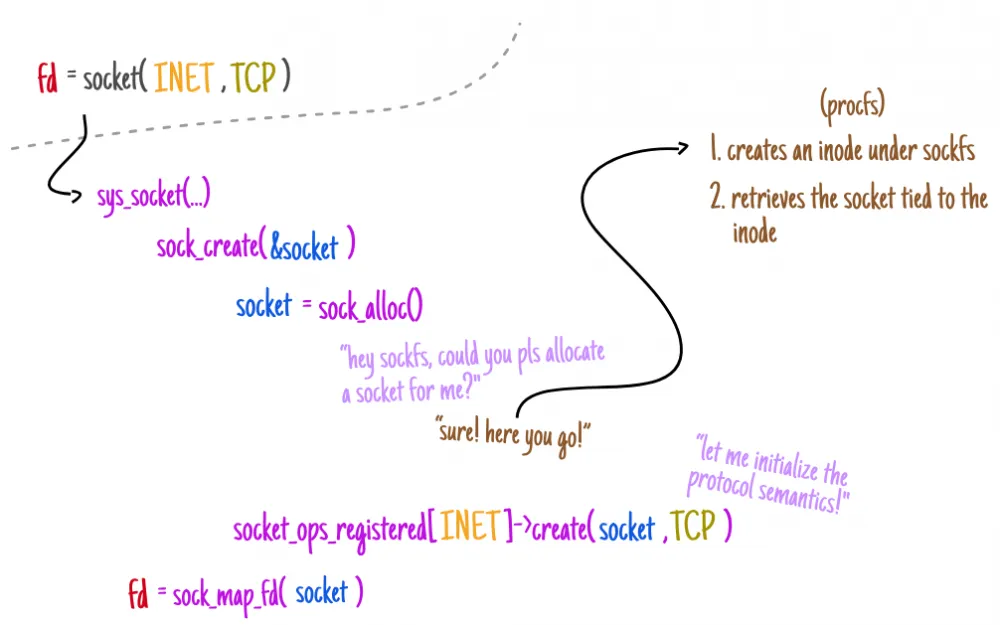
❯ The task of this method is to identify two entities: a new inode index descriptor and a socket object.
They are linked at the sockfs file system level, which not only tracks socket information in the system but also provides a translation layer through which regular file system calls (e.g., write(2)) interact with the network stack (regardless of the underlying domain in which such communication occurs).
By tracking the operation of the sock_alloc_inode method, which is responsible for allocating the index descriptor in sockfs, we can observe how this entire process is organized:
trace -K sock_alloc_inode
22384 22384 socket-create.out sock_alloc_inode
sock_alloc_inode+0x1 [kernel]
new_inode_pseudo+0x11 [kernel]
sock_alloc+0x1c [kernel]
__sock_create+0x80 [kernel]
sys_socket+0x55 [kernel]
do_syscall_64+0x73 [kernel]
entry_SYSCALL_64_after_hwframe+0x3d [kernel]
/**
* sock_alloc - socket allocation
*
* Allocate new inode and socket objects. The system first binds them together,
* and then initializes them. After that, the socket is allocated. If we run out of inode objects,
* NULL is returned.
*/
struct socket *sock_alloc(void)
{
struct inode *inode;
struct socket *sock;
// Provided that the filesystem is in memory,
// allocate objects using
// kernel memory.
inode = new_inode_pseudo(sock_mnt->mnt_sb);
if (!inode)
return NULL;
// Extract structure from
// located in
sock = SOCKET_I(inode);
// Set some aspects of the filesystem, such that
inode->i_ino = get_next_ino();
inode->i_mode = S_IFSOCK | S_IRWXUGO;
inode->i_uid = current_fsuid();
inode->i_gid = current_fsgid();
inode->i_op = &sockfs_inode_ops;
// Update the counter, accounting for each CPU core separately,
// which can then be used by other systems,
// if a quick count of sockets is needed.
this_cpu_add(sockets_in_use, 1);
return sock;
}
static struct inode *sock_alloc_inode(
struct super_block *sb)
{
struct socket_alloc *ei;
struct socket_wq *wq;
// Create a record in the kernel cache and
// allocate the necessary memory.
ei = kmem_cache_alloc(sock_inode_cachep, GFP_KERNEL);
if (!ei)
return NULL;
wq = kmalloc(sizeof(*wq), GFP_KERNEL);
if (!wq) {
kmem_cache_free(sock_inode_cachep, ei);
return NULL;
}
// Perform the simplest possible
// initialization
ei->socket.state = SS_UNCONNECTED;
ei->socket.flags = 0;
ei->socket.ops = NULL;
ei->socket.sk = NULL;
ei->socket.file = NULL;
// Return the basic vfs inode.
return &ei->vfs_inode;
}❯ Sockets and Resource Limiting
Given that a filesystem inode can be referenced from user space using a file descriptor, the situation is as follows: after we set up all the basic kernel structures, sys_socket comes into play. It generates a file descriptor for the user (performs all resource limit validation steps as described in the document Process resource limits under the hood).
If you ever wondered why the error "too many open files" might occur when working with socket(2), it's all about these resource limit checks:
static int
sock_map_fd(struct socket* sock, int flags)
{
struct file* newfile;
// Remember it? This is the very method
// by which the kernel checks the
// limit of available resources and helps ensure
// that we do not exceed this limit!
int fd = get_unused_fd_flags(flags);
if (unlikely(fd < 0)) {
sock_release(sock);
return fd;
}
newfile = sock_alloc_file(sock, flags, NULL);
if (likely(!IS_ERR(newfile))) {
fd_install(fd, newfile);
return fd;
}
put_unused_fd(fd);
return PTR_ERR(newfile);
}❯ Counting sockets in the system
If you have been following closely what the sock_alloc call does, I would like to draw your attention to this: it is the one that increases the number of sockets that are currently "in use".
struct socket *sock_alloc(void)
{
struct inode *inode;
struct socket *sock;
// ....
// Updates the counter value, which works on each processor core
// and after that is used so that other systems can also
// quickly find out the number of sockets.
this_cpu_add(sockets_in_use, 1);
return sock;
}Since this_cpu_add is a macro, you can look into its definition and find out more about it:
/*
* this_cpu operations (C) 2008-2013 Christoph Lameter
*
* Optimized manipulations related to memory allocation on specific CPU cores,
* or on specific CPUs, or on CPU variables.
*
* These operations guarantee exclusive access for all other operations
* when working on *the same* processor. It is assumed that only one instance
* of the processor (current) accesses any data at the same time per core.
*
* [...]
*/ Now, assuming that we are constantly adding sockets to sockets_in_use, we can at least assume that the method registered for /proc/net/sockstat is going to use this value — indeed, this is exactly what happens. This also means that we will sum all the values registered on each CPU core:
/*
* Report socket allocation statistics [[email protected]]
*/
static int sockstat_seq_show(struct seq_file *seq, void *v)
{
struct net *net = seq->private;
unsigned int frag_mem;
int orphans, sockets;
// Extract counters related to TCP sockets.
orphans = percpu_counter_sum_positive(&tcp_orphan_count);
sockets = proto_sockets_allocated_sum_positive(&tcp_prot);
// Show statistics!
// As we have already seen at the very beginning of the article,
// it shows all those sockets that have already been allocated,
// but at the moment may not yet be in the "in use" state.
socket_seq_show(seq);
seq_printf(seq, "TCP: inuse %d orphan %d tw %d alloc %d mem %ld\n",
sock_prot_inuse_get(net, &tcp_prot), orphans,
atomic_read(&net->ipv4.tcp_death_row.tw_count), sockets,
proto_memory_allocated(&tcp_prot));
// ...
seq_printf(seq, "FRAG: inuse %u memory %u\n", !!frag_mem, frag_mem);
return 0;
}❯ What about namespaces?
As you may have noticed, the code related to namespaces lacks any logic that would allow counting how many sockets are currently allocated.
This initially surprised me a lot — after all, I assumed that it was in the network stack that namespaces were most actively used. But it turned out that there are exceptions.
interesting - with namespaces, but — no (still not accepted, patch not accepted) pic.twitter.com/BcaVCAOczY
— Ciro S. Costa (@cirowrc) October 16, 2018
If you want to figure this out yourself, I recommend you first study the article Using network namespaces and a virtual switch to isolate servers.
The essence in this case is as follows: you can create a set of sockets, check sockstat, then create a network namespace, enter it, and then it turns out: although we do not see TCP sockets immediately from the entire system (this is exactly how namespace separation works!), we still see the total number of sockets allocated in the system (as if there were no namespaces).
# Create a set of sockets using our
# example in C
./sockets.out
# Make sure we have a set of sockets
cat /proc/net/sockstat
sockets: used 296
TCP: inuse 5 orphan 0 tw 2 alloc 108 mem 3
UDP: inuse 1 mem 0
UDPLITE: inuse 0
RAW: inuse 0
FRAG: inuse 0 memory 0
# Create a network namespace
ip netns add namespace1
# Enter it
ip netns exec namespace1 /bin/bash
# Make sure it shows the same
# allocated sockets.
TCP: inuse 0 orphan 0 tw 0 alloc 108 mem 3
UDP: inuse 0 mem 0
UDPLITE: inuse 0
RAW: inuse 0
FRAG: inuse 0 memory 0❯ In conclusion
It is interesting to look back at what I have achieved. I delved into the study of the internal structure of the kernel because I was simply curious about how /proc works. As a result, I found answers that help me understand the behavior of specific functions that I have to deal with in my daily work.
❯ Sources
Computer Networking: A top-down approach;
The Linux Programming Interface;
Understanding the Linux Kernel, 3rd Ed.



Write comment