
- Network
- A
History and Development of CAPTCHA
We started with text CAPTCHA and came to a simple checkbox, improving the system after each failure.
You go to the website to buy plane tickets. Before clicking the "Submit" button, you need to check the box with the question: "Are you not a robot?"
At first glance, this looks like irony. Why do I need to confirm that I am a human, especially in front of a computer?
And even if I check this box, how does it prove that I am a human? After all, a robot can also check the box, right?

This is similar to a situation where a jury asks a murderer if he committed the crime. "Of course, I didn't kill anyone," the defendant would reply.
So what is the point of such a question? Why do CAPTCHAs exist at all? And how do they check if the user is a real person based on simple requests?
In this article, we will take a closer look at why CAPTCHAs are needed, how they have evolved over time, their various versions, and much more.
What is CAPTCHA?
CAPTCHA stands for "Completely Automated Public Turing test to tell Computers and Humans Apart".
Quite a complex abbreviation, isn't it? Let's simplify it now.
What is the Turing test?
Legendary British mathematician and computer scientist Alan Turing argued with his colleagues and critics about whether a machine (digital computer) could ever achieve a level of intelligence comparable to that of a human.
To prove his point, Turing proposed a game. In this game, an "interrogator" asked questions to a human and a computer through a text chat. If the interrogator could not find a difference between their answers, and the computer successfully pretended to be a human, it passed the test. Turing called this the "imitation game".
Who would have thought that decades later, this same test principle would be used to create CAPTCHA, but now to distinguish humans from machines.
In 2000, a 22-year-old named Luis von Ahn, along with his professor Manuel Blum, developed CAPTCHA to prevent automated programs from attacking networks and websites.
Why do we need CAPTCHA?
You have probably heard of bots. Bots are programs that can perform certain tasks based on a given script. They often mimic human behavior and can perform tasks much faster.
There are useful bots, such as search engines that scan web pages to index content, or chatbots that simulate human dialogue.
However, there are also malicious bots that can interfere with users by spreading spam, taking over accounts, or even disabling large websites by conducting DDoS attacks.
Here are some of the malicious actions that such bots can perform:
Credential Stuffing
Content Scraping
DoS or DDoS attacks
Email harvesting
Spam content
Password cracking by brute force
If left unchecked, these bots can create a multitude of problems, such as:
Undermining the credibility of online surveys.
Hacking online accounts through brute force attacks.
Ticket scalping: mass purchasing of tickets for resale.
In one such case, the large supermarket Target faced a data breach in 2013 that affected 70 million people. At that time, Target's supplier portal did not have CAPTCHA. The disaster occurred as a result of a phishing email aimed at their customer base.
That's why we need CAPTCHA — to prevent system manipulation, actions that can affect millions of users on the internet and lead to major fraud.
How does CAPTCHA work?
In most cases, CAPTCHA is based on visual tests, using the fact that automated bots do not have the same level of understanding of visual data as humans.
It all started with the need to enter strange distorted text to log into a site or leave a comment.
Thus, it was not entirely fully automated, as it required manually entering text, but let's still call it "fully automated." Why not?
Types of CAPTCHA
CAPTCHA is divided into three main categories:
Text CAPTCHA
Image CAPTCHA
Audio CAPTCHA
Let's look at each of them.
Text CAPTCHA
This is the oldest form of CAPTCHA, which uses known words or phrases, random distorted texts, combinations of numbers and letters, etc.
These characters are presented in an unusual way, making them difficult for automated programs to understand.
Text CAPTCHAs may include distorted characters, rotation, uneven scaling, and other effects. Some CAPTCHAs may also use overlaying characters with graphic elements such as color, background noise, lines, etc.
Image-based CAPTCHA
Many of us have encountered CAPTCHAs that require marking images with specific objects, such as traffic lights, cars, or other items.

These CAPTCHAs are easier for humans but much more difficult for bots, as they require not only image recognition but also its semantic interpretation.
Audio CAPTCHA
Text and visual CAPTCHAs are not suitable for users with visual impairments, so audio CAPTCHAs were developed.
Audio CAPTCHAs are used in combination with text or graphic CAPTCHAs and provide an audio recording with a series of letters or numbers. These recordings usually contain background noise, making them difficult for bots to recognize.
The emergence of reCAPTCHA
When millions of people passed these tests daily, everything worked as it should. But, as we know, innovation has no boundaries, and Luis von Ahn noticed another opportunity.
What if, instead of wasting time recognizing random distorted texts, we use old, unreadable fragments of books?
In an interview with The Walrus, Luis said that he created a system that "wasted millions of hours of invaluable human brainpower, ten seconds at a time."
And it's true! Recognizing 200 million words a day turned into 500,000 hours of effort.
That's how he came up with the idea to use real texts from old books that couldn't be recognized using optical character recognition (OCR) technology. At that time, OCR couldn't correctly read about 20% of the scanned words.
Luis's new idea was to direct human efforts for good: users, without even realizing it, helped the OCR system decipher these difficult words and added them to the database.

This new version of CAPTCHA was called reCAPTCHA. The first book digitized using this method was the archive of the New York Times, which began publication in 1851 and includes 13 million articles to date.
How does reCAPTCHA work?
It is based on the principle of crowdsourcing. First, the book is digitally scanned by the reCAPTCHA program administrator. The program selects two words: one that has already been read and recognized by the OCR system, and another that the OCR could not recognize.
The user must guess both words in the reCAPTCHA field. If the user correctly enters the first (recognizable) word, the program assumes that the second entered word is also correct and uses it for digitization.

Then the second word (which OCR could not read) is shown to other users. The program compares all the answers, and, having received enough confirmations, can recognize this word with a high degree of confidence.
Thus, the program solves two problems at once: it checks whether the user is human, and digitizes the words that the OCR system could not recognize, adding them to the common knowledge base.
Google and reCAPTCHA
In 2009, Google saw the potential and acquired reCAPTCHA for use in the Google Books project. Google used reCAPTCHA to engage people in recognizing words or characters that their image processing algorithms could not identify, thus significantly simplifying this process.
The Google Books project was an ambitious initiative to digitize all the books in the world and create a huge digital library accessible to everyone. According to Wikipedia, by October 2019, Google had scanned more than 40 million books. However, the project faced a number of legal issues related to copyright, which made its implementation difficult.
Problems with reCAPTCHA
As the system became more secure, attackers became more inventive, fueling the constant evolution of CAPTCHA.
A 2014 Google study showed that modern artificial intelligence technologies can solve even the most distorted texts with 99.8% accuracy, and numbers in images with 90% accuracy. This made visual data processing an unreliable verification method. A new approach was needed.
NoCAPTCHA reCAPTCHA
Then came the revolutionary API that we use today — NoCAPTCHA reCAPTCHA. This is the very simple checkbox we talked about at the beginning. All that is required is just to check the box, and you can continue working.
How does NoCAPTCHA reCAPTCHA work?
In fact, it is much more complicated than it seems. NoCAPTCHA works based on an advanced risk analysis API that constantly monitors user behavior. The system analyzes all interactions with the CAPTCHA: the movement of the cursor before clicking on the checkbox, during the check, and after you have checked the box. Based on these actions, it determines whether the user is human.
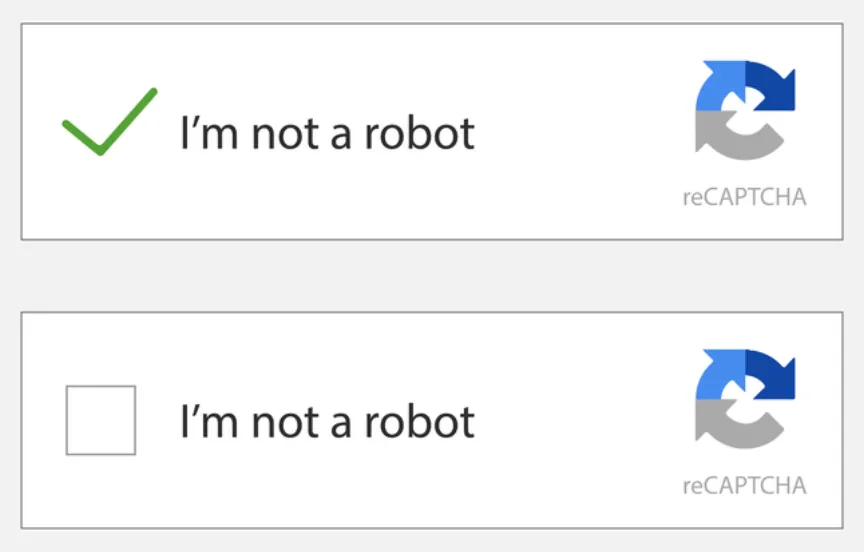
Why does NoCAPTCHA reCAPTCHA work?
The main idea is that automated malicious bots use pre-written scripts to perform functions. If a bot tries to "slip through" and check the box, it will simply perform the programmed action without the natural cursor movement like a human.
Thus, the NoCAPTCHA reCAPTCHA program can determine whether the function was performed manually or through a script.
However, even this method is not completely secure. There may be programs that can simulate mouse clicks and automatically check the checkbox. Therefore, Google may also consider other data that users inadvertently provide, such as IP addresses and cookies, which helps prove that you are human.
Although Google does not reveal all the exact methods for determining bots (let's leave that to them).
What if this is not enough?
Even with such a complex security system, there may remain uncertainty. Considering this, Google has added an additional step for verification when the system is unsure of the result — image identification.
When the program is in doubt, it may ask the user to confirm their humanity using the old style CAPTCHA (texts and numbers) on desktop computers or image CAPTCHA on mobile devices.
Also, a form expiration timer works in the background, preventing bots from solving the CAPTCHA after a long time.
Next CAPTCHA Innovations
Innovations in this area do not stop. We started with text CAPTCHA and came to a simple checkbox, adapting after each failure.
Each CAPTCHA failure leads to the development of artificial intelligence. Why? Because for the test to fail, someone had to come up with new ways for the computer to solve the test.
This stimulates further development and the emergence of new types of CAPTCHA.
One of these innovations is the Honeypot Method.
How does the Honeypot Method work?
It uses deception to make bots reveal themselves. When we create a form, automated programs are most likely to fill in all the fields. A human will only fill in the fields visible to them.
What if we add fields that are invisible to users but are present in the form?
Bots will fill in these hidden fields, thereby revealing themselves.
Honeypot Method — Double Advantage
The Honeypot method works like a double-edged sword: it simplifies the verification process for users and effectively catches malicious bots. Simplicity for humans and a trap for bots — that's what makes this method effective in combating spam.
What is the future of cybersecurity?
However, as we discussed earlier, everything that is created can be hacked — if the adversary is motivated to do so.
Initially, CAPTCHAs were developed to protect against bots spreading spam. But today, bots are not limited to this — they attack servers, steal data, and commit fraud. The emergence of threats such as CAPTCHA farms (organized groups of people solving CAPTCHAs for payment) and smarter AI bots calls into question the effectiveness of CAPTCHAs.
Are CAPTCHAs still effective?
CAPTCHAs often act as "speed bumps" on the path of hackers — obstacles that slow down attacks but do not stop them completely. Bots are getting smarter, and technologies like machine learning can easily bypass even the most complex CAPTCHAs. On the other hand, complicating CAPTCHAs can lead to customer frustration. No one wants to spend time solving pictures or entering random texts during simple registration or login.
This is clearly not a long-term solution, and increasing the complexity of CAPTCHAs only slightly delays attackers.
A new direction in cybersecurity
Thinking about the future, it is important to look for new solutions. Online businesses should invest in technologies that can effectively recognize bots while providing a convenient experience for users.
There is a possibility that new solutions are already being developed. Perhaps in a few years we will see a completely different approach to internet security that goes beyond CAPTCHA.



Write comment