
- Security
- A
Encrypt this, encrypt that, or LLM under lock and key
Hello, dear readers of tekkix. The more I delve into LLM, the more I am convinced that they have now taken, if not the most important, then certainly one of the very significant places in the entire pantheon of machine learning models. At the same time, the question of encrypting models in the broadest sense is increasingly arising. It is not so much about the mechanisms, algorithms, approaches, and methods of encrypting what the user requests, but about working with data in general, including for training models. That is, encryption both at the input and output — data from the user, from the model, and training data.
We will talk about the safe handling of commercial content, data encryption, models, and approaches to safe handling and embedding of commercial data into the model. It will be interesting;)
Why is this important? Today, the fourth generation of GPT systems is working, we are waiting for the fifth. There are many analogs of the "four" (Megatron-LLM, LLaMA, Claude, PaLM, Mistral, BLOOM, Grok, Megatron-Turing NLG, Chinchilla, OPT, GODEL, Jurrassic-2), which in a number of parameters far exceed GPT-4. However, for the qualitative "evolution" of systems, it is necessary to "feed" them the "correct" operational code, tested and fully covered by tests, which is created by large corporations, medium and small businesses. But there is a nuance: no one will just give away such code. Moreover, it is protected by copyright and has a number of imposed legal conditions for use.
Since none of the aforementioned chatbots (generative models) are currently capable of producing anything at the level of an architect or serious production development, full integration among models may not be as fast. Yes, they are trying to circumvent this, as shown in this article. Moreover, it is currently impossible to embed a large time span of the entire project development into the model, for example, over a year, unless it is an internal model of a large corporation. This was one of the hidden factors when OpenAI announced the extension of the sequence to 8192 tokens in 2023, and an extension of this sequence is expected in 2025. Because of this, the encryption problem is very acute now, as there are more and more attacks, methods of bypassing blocks, and various ways of changing rules. For example, you can find such "wonderful" things on Git: one, two.
Another unpleasant factor is content borrowing. The number of lawsuits against companies like OpenAI (ChatGPT), NVIDIA (Megatron), Microsoft (Bard), CompVIS (Stable Diffusion) is rapidly growing because they, according to many reports (one, two, three, four), simply "borrow" external content (audio, video, code, text, other technological and technical data) without complying with any copyright and commercial agreements. The latest scandal with NVIDIA only confirmed these points. According to available information, downloading was carried out not only from open sources (YouTube, NetFlix), but also from pirate resources.
There is a real race, if not a war for content, and neither norms, nor laws, nor any other factors play a role for such large conglomerates. However, just recently, during court negotiations, Google paid the media a large compensation for using content. But the situation will not change globally, so it is worth considering.
At the same time, the separation in the use of content and approaches occurs not only in the software but also in the hardware field. For example, OpenAI intends to release its own chips for GPUs, thereby openly boycotting and "draining" NVIDIA's hegemony with the support of no less significant players. Meanwhile, under the guise of such "whales" as Blackrock, Neuberger Berman, Type One Ventures, Cisco, KDDI, and Samsung Catalyst Fund are actively building their own factory and have already received investments for this purpose. Of course, there is no talk of company takeovers, but the situation is very close to this. In addition, AGI and quantum encryption, which we will definitely touch upon, are already actively "looming" on the horizon.
Encryption
Let's start with the secure transmission of private data. In this study, it is proposed to use a simple but effective mechanism EmojiCrypt to protect user privacy. It uses Emoji to encrypt user data before sending it to the LLM. This makes them indecipherable to humans or LLM expertise, but retains the original meaning of the prompt, ensuring no impact on model performance.
Testing was conducted on three tasks: personalized recommendations, sentiment analysis, and tabular data analysis. The results of the experiments showed that EmojiCrypt can encrypt personal information in prompts in such a way that not only prevents the detection of confidential data by a human or the LLM itself, but also maintains or even improves accuracy without additional tuning, achieving comparable or even better accuracy compared to direct access to the LLM without prompt encryption (Fig. 1).
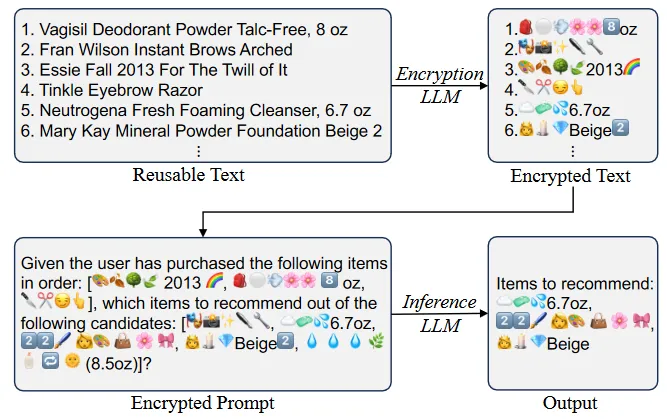
It is also mentioned here that there is a problem of data "leakage" (one, two, three), and it cannot be solved by simple solutions such as RSA encryption. Transferring data to cloud storage is not entirely secure, as the content of the user's conversations with the LLM can be studied in the model parameters, which can then be exposed as a result of adversarial attacks (Jailbrake LLM).
In addition, several works note that homomorphic encryption according to the BVF scheme (Brakerski-Vaikuntanathan-Fan-Vercauteren) is now actively used — one of the most well-known fully homomorphic encryption schemes (Fully Homomorphic Encryption, FHE, an optimization of this approach is FastQuery, and you can read more here). It is based on the complexity of solving multidimensional linear equations and is an extension of the Brakerski and Vaikuntanathan scheme, known as the BGV scheme. The main features of the BVF scheme:
Efficiency.This scheme focuses on computational efficiency and reducing noise (errors) that typically occur during homomorphic operations.
Modular reductions. Special reduction techniques are applied to control the noise level during computation.
Support for a wide range of operations. The BVF scheme supports both addition and multiplication of encrypted data, making it suitable for complex computational tasks.
These schemes are not perfect; theoretically, they can be cracked. But there are several important factors, one of which is the complexity of the problem. The security of BVF is based on the complexity of solving the Learning With Errors (LWE) problem and related lattice-based cryptography problems. They are considered extremely difficult to crack using modern algorithms and computational power, but one of the contenders for this role could be quantum algorithms (Shor's algorithm) or its modified version — Regev's algorithm. The approximate path to cracking would be as follows:
Analysis of the Learning with Errors (LWE) Problem Structure. The BVF scheme is based on the Learning with Errors (LWE) problem, which involves recovering the original data from linear equations with noisy coefficients. Without noise, the problem is simple, but adding error makes it computationally difficult.
Transforming LWE into a Periodicity Problem. Shor's quantum algorithm works well with problems that can be reduced to finding the periodicity of functions (e.g., in the problem of factoring numbers by finding the order of an element in a group). To do this, it will be necessary to develop a quantum algorithm that reduces the Learning with Errors problem to the problem of finding periodicity.
Building a Quantum Oracle. Shor's algorithm uses a quantum oracle to compute the superposition state, which then passes through the quantum Fourier transform to find periodicity. For the LWE problem, a similar oracle needs to be created that generates a superposition of all possible solutions to the system of linear equations with noise.
To solve the problem of noise elimination (compensation), it needs to be analyzed. Thus, we obtain the structure of the noise and the ability to suppress it. Since it has a probabilistic nature and, moreover, its composition is very heterogeneous, and the content is quite small (at the level of 1%), libraries for generating synthetic data (Pandas‑Faker, Mimesis, Synth) can be used to study the structure of the noise, which take into account statistical distributions. Thus, the size of the training set of noise can be increased for the development of subsequent models and obtaining the noise distribution. The following models can be used: HMM, CRF, VAE.
In another work (if an attacker for some reason found out that Emoji Encrypted encryption is used and wants to fake a request), an equally interesting approach from the Jailbreak perspective is considered. The method is based on personalized encryption performed on CodeChamelion. It allows you to hide unsafe intentions when issuing prompts for LLM. Thus, the inverse problem should be solved: decrypt encrypted messages to identify "malicious payloads" not in the model itself, but in a separately created "sandbox". This will allow the filter to be increased at the model input in addition to those already existing based on LLM‑Stega and PermLLM, MPCFormer, Puma.
Thus, there is an approximate concept of encryption and decryption. By combining these methods, it is possible to take into account the methodology of existing decryption and supplement encryption algorithms that have not yet been cracked but have the potential for this.
Toolset
Here are some applied tools that are currently used for model protection and encryption.
Let's start with encryption and the general security system of models: LLM‑Guard, cyber‑security‑llm‑agents, awesome‑llm‑security, PurpleLlama, agentic_security, llm‑security, rebuff, LLM Security 101, AutoAudit, llm‑security‑prompt‑injection.
Let's say a separate word about benchmarks. There are a lot of these tools now, but they are all quite similar, and they can be divided into several categories:
Technical (write code, check, convert, optimize): Yet Another Applied LLM Benchmark, Bench, evalplus, bigcode‑evaluation‑harness, evaluation, CodeXGLUE.
Load (model quality assessment, token generation speed, resource costs, performance): GPU‑Benchmarks‑on‑LLM‑Inference, Big‑BENCH, llmperf, llm‑benchmarker‑suite.
Multimodal (text, video, code, images): 大模型评测数据集和工具大全 (Full Collection Test Pack for LLM).
Agent (testing assistants, agents, general dialogue): FastChat, FLASK, llm‑benchmarks.
Attacking (hacking, rule bypassing, security testing, resilience): fiddler‑auditor, llm‑atacks.
Encryption systems for LLMs are multiplying and expanding, and this trend will only intensify due to the fact that the hallucination problem has not yet been fully resolved and there are more and more mechanisms for bypassing blocks on the same prompts.







Write comment