
- AI
- A
ICDAR-2024 Results: How and Why to Make Recognition Explainable
In sunny Athens, the ICDAR-2024 conference has concluded. Whether it was the Mediterranean sun or the lively enthusiasm of the speakers, it was really hot here. This is not surprising - after all, this is the main international event dedicated to recognition issues. One of the key topics of the meeting is the modern challenges and prospects of OCR. Leading scientists from around the world agreed that recognition technologies must be made more understandable and interpretable. And for this, creating a simple OCR is clearly not enough. We at Smart Engines have something to add on this matter. We explain why it is necessary to "explain" OCR and how to do it correctly.
Why ICDAR?
Sea, sun, beach technology. The International Conference on Document Analysis and Recognition, also known as ICDAR, recently concluded in the Greek capital. It seems that there was no better place to exchange experiences in one of the key scientific fields in the era of digital transformations. The cradle of science, after all!
ICDAR has been held since 1991 and has long established itself as the central event in the field of document processing, text recognition, and image analysis. Every year, all the cream of the scientific and professional community gather here: leading researchers, developers, business representatives, and authorities come to the conference to discuss the state of affairs in the field of computer vision, formulate directions for future research, and propose solutions to current problems. The Smart Engines team regularly speaks at ICDAR, presenting their new developments. This year, our scientists gave two presentations at the conference.
This meeting is the 18th in a row and was traditionally dedicated to the latest achievements in the field of automatic text recognition, document analysis, archive digitization, and other related technologies. ICDAR conferences consistently monitor the current state of OCR and note all the innovations.

So, the good news: scientists agree that OCR is not outdated at all, it is developing successfully and remains the focus of researchers and clients. The bad news: for many users, the technology is a dark forest. Therefore, it is necessary to make as many people as possible understand the principles of OCR (and be able to observe this work). But for this, the systems themselves still need to be improved. Let's go in order.
Why OCR is important and necessary
OCR has been known to humanity for about a hundred years and still remains a central technology in the field of processing, analyzing, and extracting textual information. Moreover, of any kind: from passport data, identity cards, accounting documentation, banking forms to historical documents, archival records, letters, receipts, and the like. Today, neural networks and machine learning technologies are actively used in OCR: thanks to modern OCR, any tables, handwritten characters, text in video streams can be digitized and even verify the authenticity of recognized documents.
With the help of OCR, automatic digitization of text data occurs in any volume. Paper documents or books are converted into digital files, making the information in them available for search, editing, or simple storage. Automation significantly affects the speed of business processes and minimizes the risk of errors. Therefore, it is not surprising that today OCR is used almost everywhere: in government agencies, industry, banking, retail, telecom, notary firms, security and control systems, medicine, archives, aviation and railway ticket offices, databases, and so on.
In general, it is indeed impossible to overestimate the scientific and practical significance of OCR. Read more about the application of the technology here or at the link below.
IDP and OCR in questions and answers: The main thing you need to knowHello, tekkix! Today we will run a couple of messages about what IDP and OCR are, what their princ...habr.comHow and why to make recognition explainable
Significant attention at ICDAR 2024 was paid to the need to make OCR systems more understandable for the user. More precisely - explainable (at the conference, this was described by the term explainable recognition). And if the main task and basic functionality of OCR are more or less clear, then the recognition process itself, especially with the advent of neural networks, in most cases remains beyond the scope. The verdict of the scientific community: it is not enough to just create OCR – it is also necessary to make its work explainable and interpretable. At all stages.
In practical terms, this means the following:
Recognition should be multi-stage, results should be transparent. A user of a high-quality OCR system should be able to personally monitor recognition at any stage. The principles by which the entire process takes place should be explainable, and the result should be understandable to a person. For example, the user should be able to see the placement of digitized characters in the processed document.
Confidence indication is necessary. The recognition system should demonstrate not only what and where it took and recognized, but also how confident it is in the results. For example, highlight individual characters or shapes that the OCR system is not confident in correctly recognizing. Even better, it should evaluate its own confidence in the results character by character.
No unjustified rejections. If an error occurs during recognition, the system should not only report the failure to the user but also explain why it happened.
Of course, the above and further refers exclusively to algorithms – no HITL, where the recognition of important documents is done by a random person under the guise of AI. This is not a free-for-all.
The lack of attention from OCR system developers to all these rules is fraught with distrust and, consequently, a lack of demand from users. Which, of course, is sad, – they summarized at the conference. Conclusion: there is something to strive for, the path to achieving the necessary level of technology openness is not close. First of all – because the direct scientific solution to the problem (i.e., providing the user with complete freedom to observe how and on what OCR is trained and functions) is hindered by the issue of pure ethics. How correct will it be now, when everyone is striving for complete privacy and scientists are thinking about how to roll back algorithm training to delete or "forget" the use of someone's data?
How we ended up ahead of the rest of the world
Few modern OCR development companies can boast of a technology that meets the "explainability" rules formulated at ICDAR 2024. Conference participants concluded that improving OCR systems will still take a lot of time. And we at Smart Engines have already successfully implemented almost everything that many can only dream of for now.
Since their inception, our products have been and remain interpretable at all stages of recognition: the numerical value of performance quality is returned within each recognition subsystem, starting with document type determination and ending with post-processors. Moreover, we train all our models only on synthetic data, which allows us to eliminate the human factor from data annotation, as well as accurately describe the model of training data.
Here's what it means:
The operation of the recognition system is divided into stages, within which individual subsystems sequentially function. For example, first, the localization (or search) and document type determination subsystem works, which finds the document in the image and fixes its boundaries. Of course, if we are not talking about full-text recognition - in this case, this stage is ignored. Knowing the type of document allows us to avoid unnecessary actions and simplify and speed up the recognition process. Then the image is processed: the system removes any distortions, including perspective - as if the document had been scanned. After that, the stage of searching for informational and content fields (text, tables, stamps, seals, photos, and so on) begins. And only then does the actual recognition of information from the fields by neural networks occur. Finally, the results are processed by post-processors. At this stage, the extracted data is checked and corrected taking into account their expected format, because we already know the type of document.
For the user, all these stages take place in tenths of a second (and sometimes hundredths of a second) and therefore, as a rule, are imperceptible. However, this does not exclude the possibility of monitoring the process and visually displaying the results of our OCR at each level.
Each stage is observable and can provide a numerical metric of its confidence – in practical terms, this allows not only to track the success of each stage, but also, if necessary, to draw, observe and understand at what stage the recognition error occurred;
The user has the opportunity to see the exact location of the problem area. If our system could not recognize any of the fields of the document (for example, the surname field) or a single character in a word, it will not throw an error of the entire process at the user, but will gently guide them to the specific stage, field or character and show what, where and how it failed.
In a word, everything is as explainable and interpretable as possible.
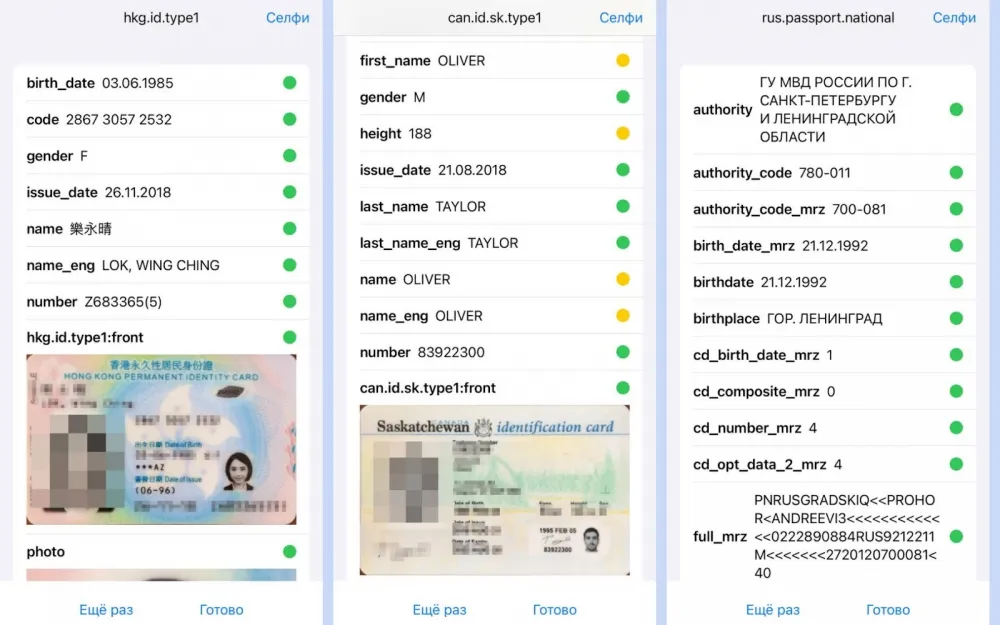
Another important point is the protection of our neural network models, which is ensured by the fact that we independently synthesize training data. Such data does not contain sensitive personal information and at the same time is in no way inferior to real data in terms of naturalness and diversity. How do we do this? Read here:
How to properly generate training data for OCR? We at Smart Engines write a lot about document recognition. And, of course, for document recognition...habr.comAs follows from the reports of the same ICDAR, the general trend towards privacy has not been canceled. And our OCR fully complies with it - both scientifically and in practice. In general, we keep the brand.
In addition to explainability
Smart ID Engine, Smart Document Engine, and Smart Code Engine solutions are based on our own OCR engine, capable of processing large volumes of documentation at high speed, correctly reading data from tables, prints, handwritten fillings, and other features of various types of papers. And all this - at a speed of 15 documents per second on the server.
Our OCR extracts information from any sources: from scans, photos, or videos, in an application or browser window, etc. Moreover, it manages to read and recognize with character-by-character accuracy any, even frankly unsuccessful "inputs": with distortions of proportions, creases, spines, coat of arms lines, protective elements like holographic details or guilloche background, and the like (primarily talking about passport recognition). And all this - quickly and reliably, without entrusting the content of documents to third parties.
Smart ID Engine provides instant recognition and data entry of identity documents from more than 235 jurisdictions worldwide. The solution works in real conditions with photos, videos, and scans and is supplemented by non-biometric face verification technology to ensure authentication. All recognition operations are fully automated and exclude the human factor. The software is supplied as an SDK with an API for smartphones, desktops, and servers.
Smart Document Engine allows high-speed recognition of printed and handwritten documents in 102 languages worldwide. By using unique models of training data synthesis and geometrically aware AI, the solution is capable of fully autonomously processing large volumes of documents and extracting information from them. Data processing occurs within the company's perimeter (on-premise) without administrative and criminal risks.
Smart Code Engine makes it possible to automate the process of recognizing two-dimensional and linear barcodes, payment details, bank cards, handwritten and printed phone numbers. With the software product, it is possible to scan documents containing machine-readable zones (MRZ). The solution can be integrated into web applications (PWA) and web pages.
We at Smart Engines know exactly what high requirements a quality recognition system must meet.










Write comment