
- AI
- A
How Mesh R-CNN works
Well, first of all, hello everyone, in this article I will try to tell you about the structure of Mesh R-CNN, how it works, what it actually represents, and there will also be notes with a description of the concept of generating 3D objects. I will rely both on existing articles and write from myself. There may be some mistakes somewhere, so if you notice, I will try to correct them.
In general, what is Mesh R-CNN for, it is needed to generate 3D objects based on an image. This method is built on the foundation of Mask R-CNN [2], but with the addition of a branch for predicting meshes. This creates an initial representation that is converted into a mesh and refined using a graph convolutional network.
Introduction
Modern systems successfully recognize objects, localize them using 2D boundaries or masks, and predict the position of key points in the image. The Mesh R-CNN method uses 2D recognition and 3D shape prediction to create a system that takes an RGB image, detects an object (using detection), outputting its category, segmentation mask, and 3D triangular mesh representing the complete 3D shape of the object.
Mesh R-CNN takes an image as input, predicts object instances, and determines their 3D shape. To account for the diversity of geometry and topology of objects, rough voxel shapes are first predicted, which are refined to predict accurate meshes.

This system dynamically changes complexity, topology, and geometry depending on visual stimuli (object features: color, shape, texture). Initially creating a voxel representation of objects and then converting it into a mesh grid allows creating meshes with arbitrary topology and accurately conveying object details.
Reference material
(In this section, we will quickly go through each stage of this system for a general understanding to get into the course or for further reference material)
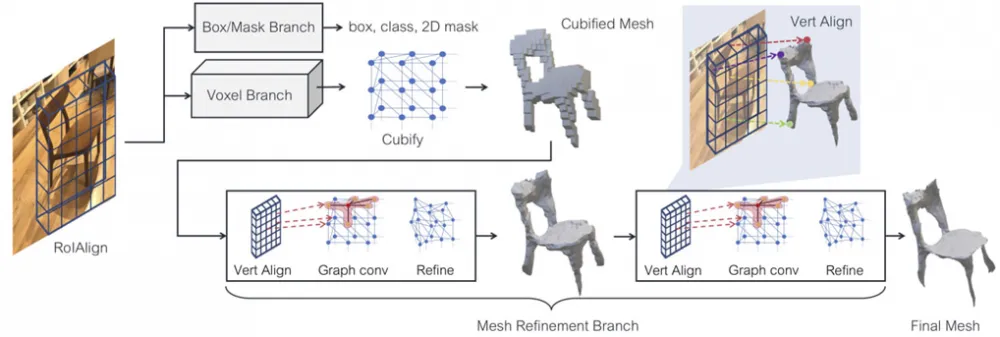
This image presents an overview of the Mesh R-CNN system, an extended version of Mask R-CNN with added 3D shape inference (the process of extracting and reconstructing the three-dimensional structure and geometry of an object based on its two-dimensional images)
Input layer: an image is fed, from which information is extracted.
Box/Mask Branch: This branch processes the image and obtains a box, class, and 2D mask
Voxel Branch: This system represents our image in a rough voxel form, converting the image into voxels that represent 3D data in the form of cubes
Cubified Mesh: At this stage, the data obtained from the voxel branch is converted into a mesh consisting of cubes, which simplifies subsequent data processing.
* Mesh Refinement Branch: * (This stage is repeated a specified number of times)
Vert Align: Aligns the vertices based on the image for more accurate work with the 3D shape
Graph conv: Applying graph convolution to refine the mesh structure, which allows capturing local features and improves the model
Refine: Minor network refinement
Final mesh: This is the final stage where we get the finished 3D shape of our object
Method
(In this section, we will delve a little deeper)
Mesh Predictor
At the core of our system is the mesh predictor, which receives convolutions related to the object's bounding box and represents a triangular mesh reflecting the full shape of the 3D object. Our goal is to capture strong features of the object in the image. Each predicted shape has a unique topology and geometry.
We predict different shape topologies using a sequence of shape-changing operations. The voxel branch generates voxelized representations of the object, which are refined using the refining mesh.
The result of the mesh predictor is a triangular mesh T=(V,F) for each object, where V is the set of vertex positions, and F is the set of triangular faces.
Voxel branch
Hidden text
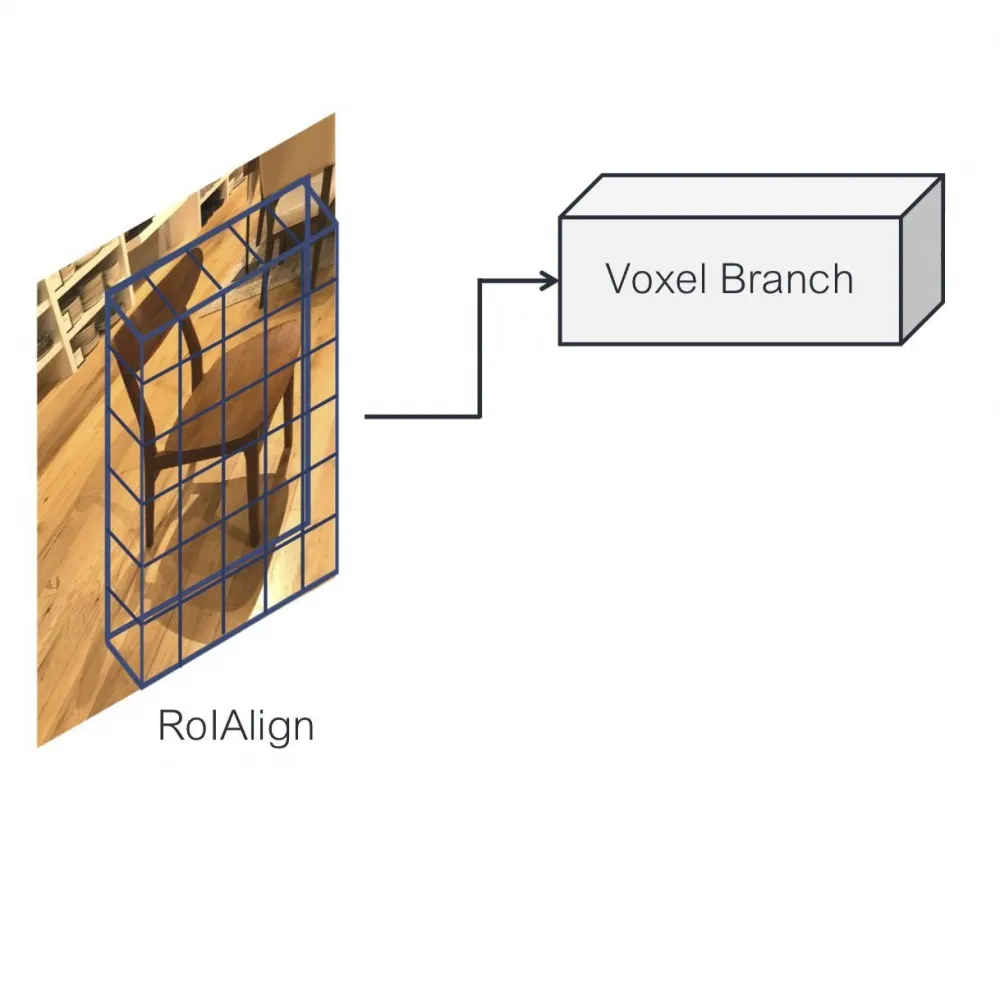
Voxel branch predicts the probability grid of voxel occupancy for each detected object, allowing to determine its 3D shape. Instead of predicting an MxM grid, we predict a GxGxG grid, which represents the full 3D shape of the object.
As in Mask R-CNN, we maintain the correspondence between the input features and the predicted voxels. By applying a small fully convolutional network to the result of RoIAlign (defines the region of interest). This network creates a feature map with G channels, showing the probability of voxel occupancy for each position.
Let's consider an example

Vertex alignment generates a feature vector aligned to the image for each vertex of the grid. We use the internal camera matrix to project the vertices onto the image plane. Given the feature map, we compute the bilinear interpolated image feature at each vertex projection. (That is, we already have a voxel 3D shape and we extract vertices from this 3D shape and match them with the image, then a convolutional network is used to extract features, and since our formation from the 3D shape is likely not to match, we use bilinear interpolation. Finally, we get a set of features that are combined into a feature vector for each vertex.)
At the first stage, the refinement branch outputs the initial feature vector for each vertex. At the last stages, it concatenates with the feature vector of the vertex from the previous stage.
Graph convolution or graph network
Hidden text
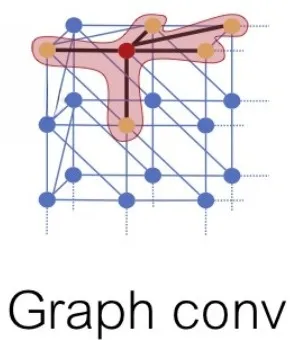
The graph network propagates information along the edges of the grid. Given the input features of the vertices $$f_i$$, it computes the updated features
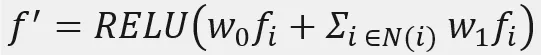
, where $$N_{(i)}$$ are the neighbors of the i-th vertex in the grid, and $$w_0$$ and $$w_1$$ are the weight matrices that are learned. At each stage of the grid refinement branch, several layers of graph convolution are used for aggregation (combining data from different places to get one more generalized value) over local regions of the grid.
Vertex Refinement
Refinement of vertices calculates updated positions of vertices
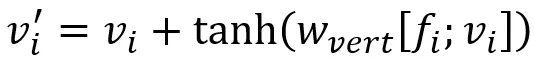
, where Wvert is the trained weight matrix. This updates the mesh geometry while maintaining a fixed topology. At each stage of the mesh refinement branch, vertex refinement is completed, resulting in an intermediate mesh result that is further refined at the next stage.
Mesh Loss or loss function
When training the system (e.g., to improve 3D models), it is necessary to determine how well the model performs the task. Instead of calculating losses directly on the triangle mesh (which is difficult), we convert the mesh into a point cloud.
And now there are two ways we can go by which metric
The first metric is Chamfer Distance (distance between points)
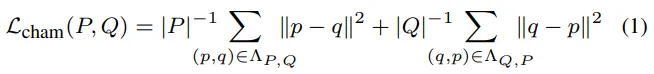
where P and Q are two sets of points, and p and q are specific points in the cloud space. The first term calculates the average distance between points from set ( P ) and the nearest points from set ( Q ), the second term similarly to the first calculates the average distance between points from set ( Q ) and the nearest points from set ( P ).
(This metric measures the distance between two point clouds. It determines how close the points of one model are to the points of another model by minimizing the average distances between them)
The second metric is Normal Distance (measured by the angle between normal vectors)
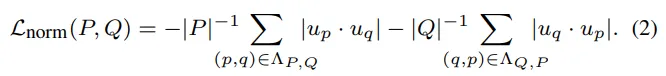
where P and Q are also two sets of points, but now up and uq are associated elements of the sets (that is, each object in one set has its own vector description in the other, in general, an analogy can be drawn with clustering, where vectors serve as numerical representations of objects, allowing algorithms to calculate similarity and assess which objects should be grouped together into clusters (I hope I didn't confuse you))
In short, Normal Distance measures the angle between the normal vectors (the direction perpendicular to the surface), which helps to assess how well the surfaces of the models match each other.
Shape regularizer or regularization
Edge Loss
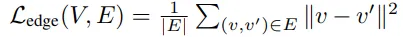
where V is a set of vertices, and E is a set of edges.
In short, this loss penalizes for too long or too short edges on the model, which maintains the quality of the shape.
Conclusion
In conclusion of the entire article, I will explain in the simplest form. There is an image, from it we make a voxel 3D shape, vectorizing it (working with vertices), we first project each vertex onto a 2D image, then update its information by analyzing neighboring vertices, and finally, adjust their position to better match this information. The result is a more detailed 3D model with clearly defined small details.
Source:
[1] - Mesh R-CNN, authors Georgia Gkioxari, Jitendra Malik, Justin Johnson, Facebook AI Research (FAIR)
[2] - Mask R-CNN, authors Kaiming He, Georgia Gkioxari, Piotr Dollar, Ross Girshick, Facebook AI Research (FAIR)









Write comment