
- AI
- A
Deep dive into the basic architecture of LPU Groq
In this article, we are going to analyze the architecture of the Tensor Streaming Processor TSP and its compiler, and then see how Groq built a reliable and high-performance distributed AI inference engine using these TSPs.
Recently, we have been talking a lot about system performance. A few days ago, Groq announced that they have outperformed everyone in LLM inference tests using their hardware language processing unit (LPU). The success of the LPU is due to the innovative design of its hardware architecture combined with a powerful compiler. Since we have been focusing on performance lately, I think understanding what lies behind the LPU hardware and compiler will be very relevant to our discussion.
Groq has not published any papers on the LPU itself, but in previous years they have published two papers (see this 2020 paper and this 2022 paper) explaining the design and implementation of their tensor streaming processor (TSP), as well as how they created a distributed inference mechanism using TSP. Although not officially stated, the LPU is likely based on this distributed system or an extension of it.
In this article, we are going to break down the architecture of the TSP and its compiler, and then see how Groq built a robust and high-performance distributed AI inference mechanism using these TSPs.
The TSP architecture is very different from the architecture of a conventional processor or graphics processor, mainly to make the TSP hardware more deterministic. Let's first talk about what causes non-determinism in a processor or graphics processor.
Understanding Non-Determinism in Processor and Graphics Processor Microarchitectures
The microarchitecture of processors and graphics processors has many features that make instruction execution on these devices non-deterministic, i.e., you cannot guarantee when a particular instruction will be executed, how long it will take to complete, and when the results will be available.
For example, a modern processor has:
Superscalar architecture: capable of executing multiple instructions per cycle.
Out-of-order execution: instructions can be executed in any order.
Speculative execution: in the case of branching, it makes an assumption about whether the branch condition is true or false and speculatively executes that branch in advance to improve throughput. In case of a misprediction, it must cancel the results of speculative execution to execute the other branch.
Instruction pipelining: it divides the execution of instructions into several stages and executes them in a pipeline manner. Thus, when one instruction moves to the second stage of the pipeline, the CPU can place a new instruction in the first stage of the pipeline. This again improves instruction throughput.
Multiple levels of caches: processors have 2-3 levels of caches to reduce instruction latency if they need to load data from memory.
All this makes the order and timing of instruction execution in the CPU non-deterministic and difficult to reason about. GPUs also have several sources of non-determinism, such as caches, shared and global memory, dynamic resource allocation.
The problem with this inherent non-determinism of these devices is that it makes it difficult to reason about program performance and to guarantee the worst-case performance limit.
As a result, Groq has developed a radically new design for its tensor streaming processor (TSP), which has massive parallelism but zero non-deterministic behavior. They simplified the hardware by giving the compiler more capabilities and control over the precise scheduling and execution of instructions to guarantee program performance. Let's take a look at what the TSP architecture looks like inside.
Tensor Streaming Processor (TSP) Architecture
The hardware design of TSP sharply contrasts with the design of a CPU or GPU. A typical multi-core chip has a tiled architecture, where each tile represents a single processor core. Inside, each tile consists of a set of functional blocks responsible for performing various types of computations. For example, arithmetic operations, memory operations, logical operations, instruction control, and so on.
TSP designers turned this traditional design inside out. They moved the functional blocks outside the cores and arranged them in a two-dimensional grid. Each column of this grid contains functional units of a specific type and is called a slice. The following diagram shows the tiled design of a conventional multi-core chip and TSP side by side.
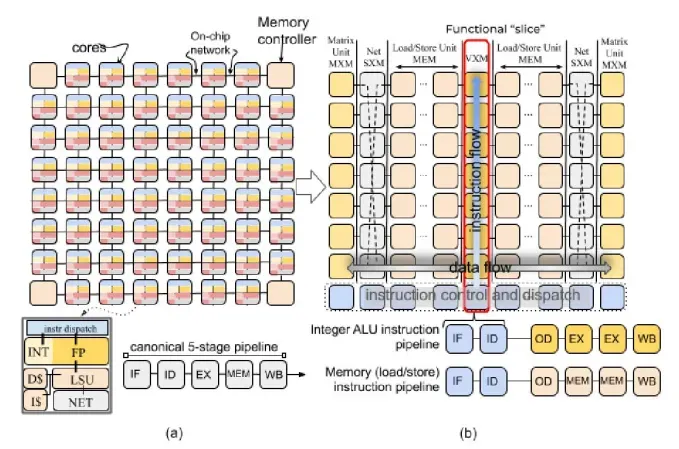
TSP has the following functional parts:
MXM : for performing matrix operations.
SXM : for vector shift and rotate operations.
MEM : memory read/write operations.
VXM : vector arithmetic operations.
ICU : instruction control unit — unlike other slices, it is organized horizontally and is responsible for fetching and dispatching instructions for execution in other slices.
Understanding the TSP architecture, let's shift our focus to its primary mode of operation — instruction execution. This is where Groq's engineering prowess truly shines, demonstrating how hardware design directly determines execution capabilities.
Instruction Execution in TSP
TSP executes instructions in SIMD (single instruction - multiple data) mode. Each functional slice consists of 20 tiles, and each tile is capable of creating 16 vector elements. Thus, a full slice can operate and create vectors with a maximum size of 320 elements.
These slices interact with each other based on the producer-consumer principle: one slice produces results in the form of a stream, and the other receives this stream as input and works with it.
When a vector is read from memory, it is assigned a stream identifier (from 0 to 31) and a stream direction (east or west). The stream flows from one fragment to another. Each slice can process the stream and create a new resulting stream, or it can allow the stream to flow as is to the next neighboring slice.
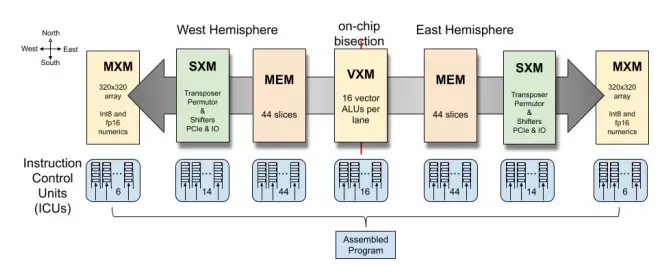
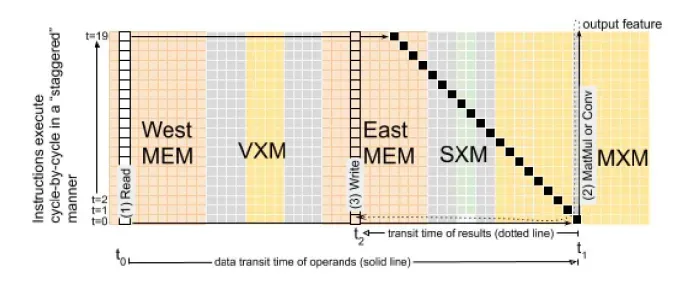
Since each tile in TSP is capable of processing 16 elements of a vector stream, for efficient processing of the entire vector, instruction execution is pipelined. At the timestamp t1, the ICU issues an instruction to the bottom-most fragment of one of the functional fragments. At the next timestamp, the output of this tile moves north to the next slice, while the ICU issues another instruction for the next part of the vector to the bottom-most tile. This leads to the step-by-step execution of instructions, as shown in the diagram below:
The accuracy with which TSP executes instructions depends not only on its hardware but also on its synergistic interaction with the compiler. Studying the compiler and the instruction set architecture shows how software and hardware combine to optimize performance.
TSP Compiler and ISA
The developers of TSP simplified the hardware and moved many of the complexities associated with executing instructions to the compiler. The compiler needs to precisely schedule instructions and data flow to correctly execute the given program and do so in the most efficient way.
The compiler has access to the following architecturally visible state of the TSP hardware:
320-lane programming abstraction: each cell in the TSP chip is capable of working with 16 vector elements (16 lanes) in SIMD mode. A vertical slice consists of 20 such tiles, thus a total of 320 SIMD lanes are available for execution.
144 independent instruction queues: the chip has 144 instruction queues, each capable of issuing one or more instructions per cycle. The compiler has full control over the order of program execution in each of these queues.
64 logical threads per lane: each lane has access to 64 logical threads that can be used to move operands or results. They are divided between East and West directions, i.e., 32 of them can be used to move data to the East, and the remaining 32 to move data to the West.
220 MB of global shared SRAM
Since there is no non-deterministic behavior in the TSP hardware, the compiler has precise information about the latency of each instruction. Additionally, the compiler has complete information about the data flow in the compiled program (e.g., the computation graph of a deep neural network).
The compiler identifies dependencies between computational tasks and assigns them for parallel execution on the available functional blocks of the TSP based on this.
It schedules instructions in such a way that the flow reaches the slice just when the slice is ready to process it. The compiler can do this because it knows the exact instruction latencies and data flow directions.
Conceptually, the compiler solves two-dimensional scheduling of instructions and data both in time and space. The TSP programming model relies on two key elements:
Deterministic data path in hardware
Providing timing information about instruction latency through ISA
Thanks to this, the compiler backend can track the position and time of use of any thread on the chip. In the document, this is called "software-defined hardware".
Scaling from TSP to LPU
So far, we have considered the TSP architecture and learned that it is fully parallel at the hardware level, but lacks any non-deterministic features. The compiler does all the heavy lifting of scheduling instructions and data flow in such a way that various functional fragments process vector data in the form of streams in SIMD mode.
This turns the TSP into the main unit of the language processing unit (LPU). Several TSPs are combined in the form of a rack, and many such racks are connected together to form a distributed system capable of providing enormous bandwidth. Let's figure out how Groq built a distributed system from TSP and how it works.
Designing a multi-TSP system: physical and distributed aspects
As with TSP, the design goals of a multi-TSP distributed system are also related to deterministic data flow and instruction execution, as well as low latency communication between nodes.
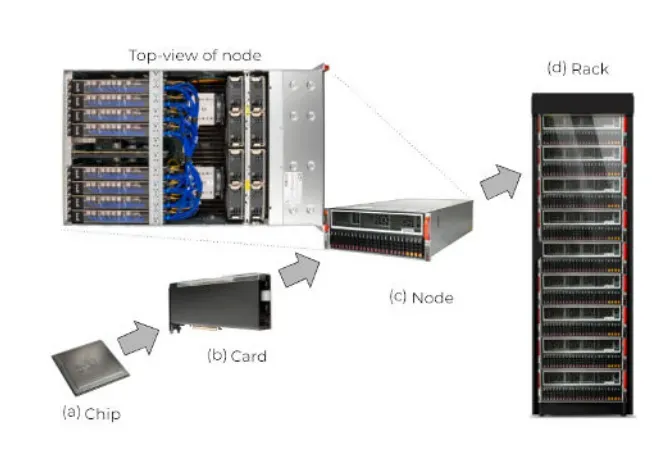
The design of the TSP distributed system starts with a node. A node is formed from 8 TSP devices enclosed in a chassis. Each of these devices consists of 11 contacts, of which 7 contacts are used to connect each TSP device to the other 7 TSP devices in the node; and the remaining 4 contacts are used to form global communication.
Since each device in the node has 4 global channels, there are a total of 32 global channels, which together form a router with 32 virtual ports.
The router supports a large number of connections, high bandwidth, and high performance — exactly what a high-performance distributed system needs.
Nine such TSP nodes, each with eight TSPs, are combined into a rack. Since each node in the rack has 32 ports, the total rack has 32 x 9 = 288 global ports. 144 of these ports are used locally to provide full connectivity between nodes for fast data transfer within the rack, and the remaining 144 ports are used to connect to other racks.
A system with a maximum configuration can support 145 such racks interconnected, consisting of 10,440 TSPs, with no more than 5 hops between any two TSPs in the system.
Implementation of Determinism in TSP-Based Distributed Systems
In this mode of a scalable distributed system, the functional blocks of a single TSP act as a single computational core of a massive parallel processor. The TSP computational model is based on deterministic hardware, and the same behavior should be extended to the distributed system mode.
There are a number of mechanisms to achieve such determinism and synchronization of individual TSP blocks in a large-scale distributed system. Let's see what they are.
Synchronization of TSP Clocks Using Hardware Aligned Counters
Each TSP device contains a hardware counter called a hardware aligned counter (HAC), with an overflow period of 256 cycles. TSPs use this to synchronize with each other by performing the following steps:
When two TSPs are connected to each other, one of them transmits its HAC value to its partner. Upon receiving the value, the partner sends this value back to the sender. The sender observes the difference between its current HAC value and the value it received back. This difference represents the connection delay between the two devices. This process is repeated several times to establish the average connection delay between the two TSPs.
After this, the two devices are placed in a parent-child relationship. The parent
T0periodically sends its current HAC value (HAC0) to the childT1. The child adds the average connection delay toHAC0and compares it with its own HAC value. The difference between the two values represents the initial misalignment due to the constant clock signal deviation.T1adjusts the HAC value to reduce this difference. After repeating this process several times, the HAC values of the two TSPs converge within a small neighborhood, which represents the channel delay jitter.This protocol allows the two TSPs to synchronize with each other, and it can be extended to a multi-interval TSP network by establishing parent/child TSPs of the linking tree in the network.
Initial Program Alignment
Before running the program for execution in a system with multiple TSPs, all TSPs need to be aligned to properly schedule the data flow and instruction execution in the system. The following mechanisms are used for this purpose.
At the level of an individual TSP, there are several independent functional blocks and 144 independent instruction queues. First of all, they need to be synchronized. For this, the TSP supports
SYNCandNOTIFYbarrier synchronization instructions. In this scheme, theSYNCinstruction puts all instruction queues into a parked state, and one of the queues acts as a notifier. When the notifier issues aNOTIFYinstruction, it is broadcast to all queues on the chip, after which they synchronize and resume operation.While the
SYNC/NOTIFYmechanism works for a single TSP, a system with multiple TSPs requires additional work. Two TSPs use HAC to synchronize with each other, and each TSP also supports theDESKEWinstruction. When a functional block executes theDESKEWinstruction, it stops processing any subsequent instructions until the HAC TSP overflows (epoch boundary). This ensures that the next instruction will be executed by the TSP at the epoch boundary. Two TSPs can coordinate the start of program execution using the following mechanism:The child TSP puts itself into a polling loop, where in each epoch it checks for the arrival of a vector from the parent TSP.
The parent TSP starts program execution by first executing the
DESKEWinstruction, which ensures that the first instruction of the program will be executed at the epoch boundary.After
DESKEW, the parent TSP passes the vector to the child TSP at the epoch boundary. The child TSP, upon receiving the vector, stores it in a buffer.At the next epoch boundary, the child TSP exits the polling loop and executes the
RECEIVEinstruction to process the vector.This scheme ensures that the two TSPs are properly aligned at the start of program execution.
To scale a multi-step system, this scheme can be repeatedly executed at each step of the binding tree.
Runtime Resynchronization
Although TSPs perform a one-time synchronization at the beginning of the program, they also need to be resynchronized during the program execution, as each TSP has its own independent synchronization source.
For this, TSPs use a lightweight scheme. In addition to HAC, each TSP has a software-synchronized counter (SAC), which has the same overflow cycle as HAC.
However, SACs are not synchronized between TSPs; SACs simply count TSP clock cycles. The HAC value represents the global time of the distributed system, while the SAC value represents the local time. Therefore, the difference between the HAC and SAC values determines the accumulated drift.
To resynchronize local and global time, TSPs execute the RUNTIME_DESKEW instruction. This instruction takes a single parameter: the number of cycles to stop. Each TSP in the system executes the RUNTIME_DESKEW command simultaneously and stops its execution to adjust the global time with the local time based on the accumulated deviation.
The role of the compiler in a software-scheduled network
As we have seen, the guarantees of deterministic execution also extend to a distributed system with multiple TSPs. This allows the compiler to have cycle-accurate information about data movement within TSPs, as well as across the network. The compiler knows the exact time of vector introduction into the source TSP and the exact time when it will reach the target TSP. This is called a software-scheduled network, because instead of hardware dynamic data flow control, the compiler resolves everything statically at compile time.
Let's discuss the characteristics of the TSP distributed system that allow the compiler to perform work in a software-scheduled network.
Known traffic patterns
For deep learning models, the compiler can determine the data flow based on the static computation graph of the model. The compiler also automates the distribution of computational tasks across the available TSP devices in the network. As a result, the compiler calculates the exact execution time of each subtask and the exchange of activations between layers. This makes the step of parallel decomposition explicit and fully controlled by the compiler.
Scheduled Data Flow
In a conventional network system, the flow of packets through the network is managed by hardware that optimizes routes when it detects problems in the network. This reactive adjustment of data flow increases latency and introduces non-determinism into the data flow.
To avoid this, a distributed system with multiple TSPs explicitly schedules the data flow through the network using its compiler. The compiler intelligently routes data in such a way that at any given time there is no congestion in the network.
In addition, the data flow scheduled by the compiler also reduces network latency, as instead of a device requesting a piece of data from another device, the compiler can schedule the second device to actively send data to the first device exactly when it needs to work with that data.
Deterministic Load Balancing
Another advantage of scheduling data flow at compile time is that it allows the compiler to efficiently balance the load of the flow across the available channels. In a conventional network, hardware makes routing decisions for each packet based on congestion metrics available in the router.
However, in the case of a system with multiple TSPs, the compiler optimally performs this scheduling based on the volume of data (i.e., the product of tensor dimensions H x W x C) and selects the number of links over which the traffic is distributed. This effectively utilizes the available system bandwidth and reduces overall latency.
So far, we have discussed what makes LPU hardware fast, let's conclude by discussing how the hardware handles errors.
Error Correction Strategy and System Reliability
In a traditional network system, transmission errors are handled at the channel level by simply retrying packet transmissions. This strategy is unviable for a system with multiple TSPs as it leads to non-deterministic delays. Instead, a system with multiple TSPs handles errors using a forward error correction strategy.
In this strategy, packets are transmitted step by step, and any errors are corrected on the spot. Any critical errors are flagged so that the runtime environment can replay the inference. The replay strategy handles any random errors, but persistent errors require manual intervention.
To ensure reliability, each rack consists of a spare TSP node. The runtime environment monitors the health of all nodes in the rack and switches to the spare node when it detects uncorrectable errors on one of the nodes.
The use of software output replay and a spare node allows the system to recover correctly from any critical errors.
Key Takeaways
This concludes our discussion of the hardware architecture underlying the LPU Groq. We have covered quite a bit of detail about the TSP and how Groq has extended it into a massively parallel distributed system. Let's quickly summarize.
Innovative Design: LPU Groq, built on the Tensor Streaming Processor (TSP), demonstrates a departure from traditional CPU/GPU architectures, focusing on deterministic and predictable execution to enhance the performance of language model inference tasks.
Deterministic Execution: The TSP architecture ensures determinism by simplifying the hardware design, allowing compilers to precisely schedule instructions and data flow, which is crucial for predictable performance.
Software-Scheduled Network: Groq's approach to building a distributed system with multiple TSPs eliminates the non-determinism typically encountered in routing and scheduling in traditional networked systems. The compiler plays a crucial role in data movement, ensuring efficiency and predictability.
Massive Parallelism: By combining hardware design and compiler intelligence, the TSP enables LPU to support highly parallel operations, making it particularly suitable for large language models (LLM).
System Scalability and Reliability: The physical and logical design of the TSP network ensures scalability, supporting a system of over 10,000 TSPs with minimal latency and high reliability, including error correction strategies and failover mechanisms.
Potential Impact: The deterministic nature and scalable design of LPU technology promise to redefine performance expectations for computational tasks, especially in the field of artificial intelligence and machine learning, setting a new standard for future processor developments.

We recently conducted a live stream discussing the TSP and LPU design and analyzing how they work. Watch the recording here







Write comment