
- AI
- A
Advisor: Employment Assistant
Hello, tekkix! My name is Gurtziev Richard, I am a first-year master's student at AI Talent Hub. During the first semester, I immersed myself in a cool project, the goal of which is to make the employment stage easier and more convenient for both employers and candidates. In this article, I want to share my experience working on the Advisor project🚀
Both job postings and resumes often contain secondary information that is not relevant for assessing professional suitability. For example, job descriptions often include details about the company, its culture, or a list of offered bonuses, which do not help determine the candidate's fit for the job requirements. In resumes, on the other hand, personal information unrelated to professional skills is often found: date of birth, marital status, or even hobbies that are not related to the specifics of the job.
Such information increases the volume of text, complicating the analysis process and distracting from key factors such as work experience, skills, and achievements. Therefore, the key point was the choice of fields. Parameters such as job title/resume title, work experience, key skills, education, languages, employment type, and work schedule became the basis for building the knowledge base.
Having decided on the main content, it was necessary to bring the data to a unified structure. Obviously, manually processing such data is not very desirable. The solution was to implement an automated system capable of quickly and accurately analyzing the data. It is based on the vLLM framework and the Qwen/Qwen2.5-7B-Instruct model, which, when given instructions, handles natural language processing quite well.
*An instruction is a text query that is passed to the model to get an answer or perform a task.
Thus, the collected resumes/job postings take a summarized form based on the main fields previously indicated.
After the data was collected and processed, the next key step is its storage. And this is where Qdrant comes into play — a powerful vector database that is perfect for storing data. Qdrant was chosen for several reasons: it is intuitive to use, and it can be easily deployed in containers. This will provide the flexibility and stability needed to work with data. We will discuss the processes related to Qdrant in detail in the RAG section.
RAG
What is RAG? In short, RAG (Retrieval-Augmented Generation) is a form of interaction with the model, in which the response to a query is generated by the language model using data from an external storage, such as Qdrant, Milvus, etc. It is important that this data is retrieved based on vector similarity, which allows for increased accuracy and relevance of the generated response. More details can be found here.
Choosing and setting up a retriever
Creating RAG starts with choosing and setting up a retriever — a component responsible for retrieving information from the database.
To retrieve relevant information, it was necessary to select an appropriate algorithm that would ensure efficient information retrieval from the database, so it was decided to take several models and consider them both separately and together to find the right algorithm. The following were chosen as dense vectors: deepvk/USER-bge-m3, ruRoPEBert-e5-base-2k, rubert-tiny2, multilingual-e5-large, and all-MiniLM-L6-v2. bm25 was taken to form sparse vectors.
Experiments conducted to evaluate top@10 points showed that among the search algorithms using only one type of embeddings, the best was deepvk/USER-bge-m3. The results are presented below.
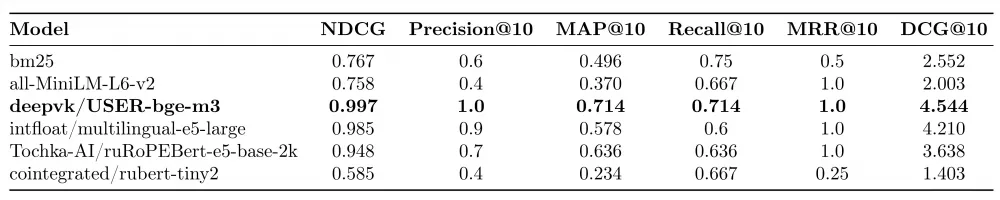
However, we wanted to consider other approaches that could improve the obtained metrics.
Fusion Vs Matryoshka
There are two main approaches to creating a hybrid search system: "fusion" and the "matryoshka" method. The first approach involves combining results obtained by different search methods solely based on their scores. This usually requires normalization, as the score values of different methods can vary significantly in range. After normalization, relevance indicators are used to calculate the final score, which determines the order of documents. Qdrant has built-in support for the mutual ranking method, which is the de facto standard in this area.
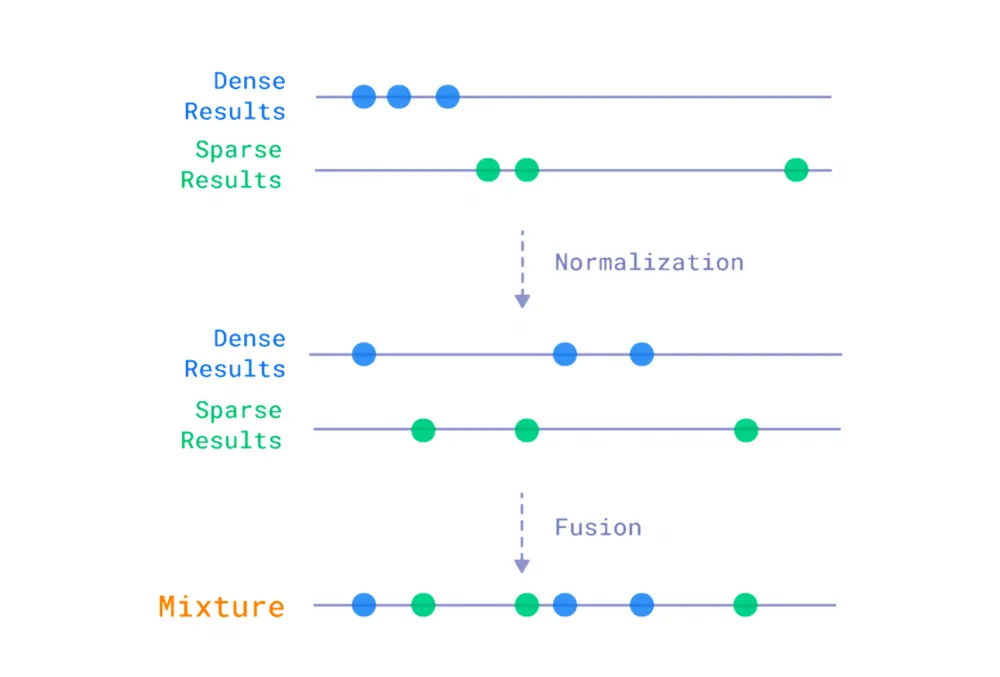
The metrics calculated using the Fusion method only worsened the result.

Well, let's try a different approach)
The search mechanism can act as a re-ranking mechanism. For example, you can pre-select results using sparse vectors and then re-rank them using dense vectors. If you have multiple embeddings, then, according to the matryoshka principle, you can start by selecting candidates with the smallest dense vectors and gradually reduce their number, re-ranking them with more complex multidimensional vectors. An ensemble of such approaches will allow combining fusion and re-ranking to achieve the best results.
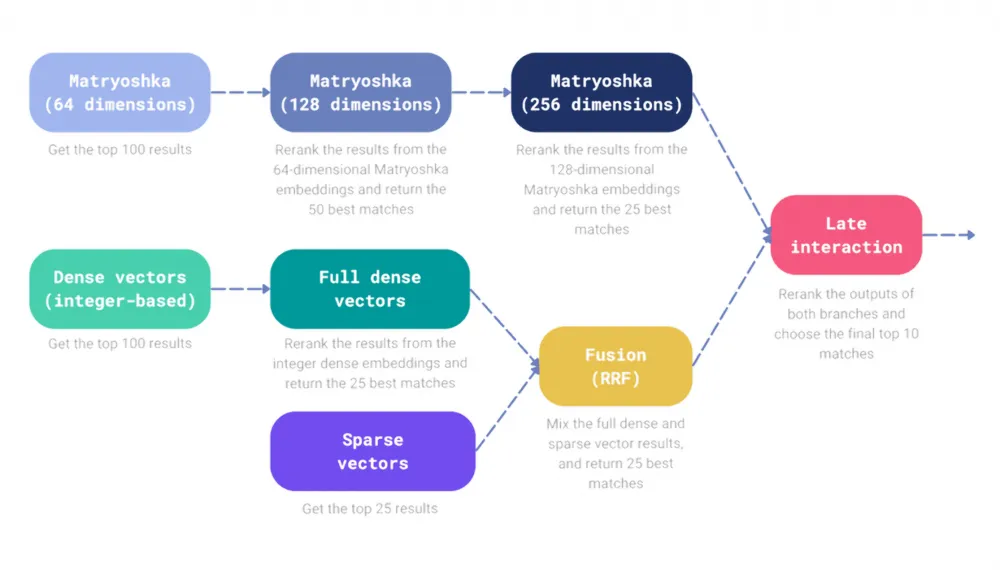
Let's focus on an ensemble that combines the results of matryoshka embeddings, dense and sparse vectors. For this algorithm, models were selected based on the results of the 1st study: deepvk/USER-bge-m3, Tochka-AI/ruRoPEBert-e5-base-2k, and bm25.

Managed to achieve the following results:
ndcg | precision@10 | map@10 | recall@10 | mrr@10 | dcg@10 |
0.991 | 1.0 | 0.77 | 0.77 | 1.0 | 4.54 |
Comparing the results of the 1st and 3rd experiments, it became clear that the use of the matryoshka method improved the search performance for MAP@10 and Recall@10, but led to a slight decrease in NDCG.
Thus, the best algorithm for finding relevant information was found, and now we move on to the development of other components of the RAG system.
Multi-agent system
After choosing the search algorithm, we proceed to the next stage of the RAG system — multi-agent systems.
A multi-agent system is a system consisting of several agents that interact with each other to achieve a common goal or solve complex problems. Each agent in the system is engaged in its task and acts based on the received instruction.
This system uses LangGraph, which allows you to create a graph grid where each node represents an agent performing a specific instruction. More details can be found here. What was the result?
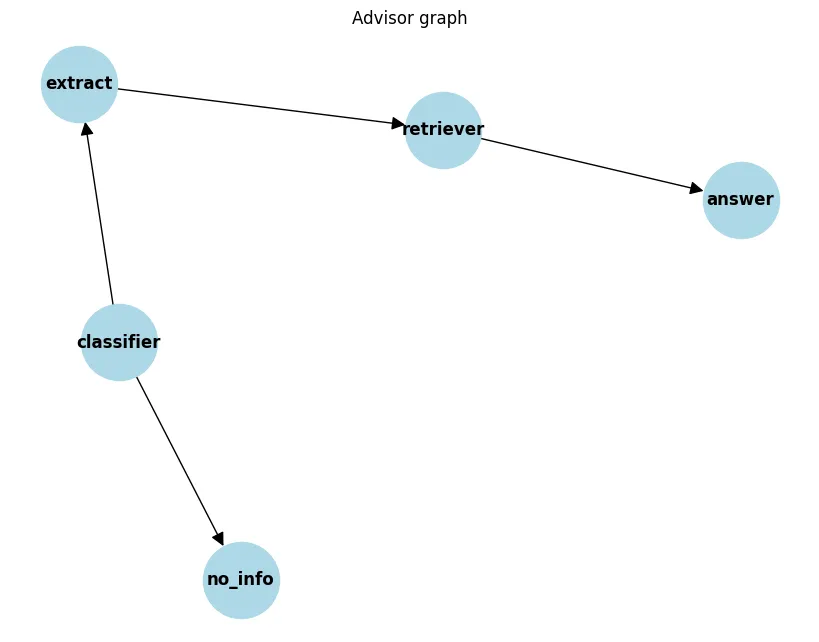
The graph network starts with the classifier node, which classifies the input text. If the text does not contain information about the candidate or vacancy, it is classified with the other label and the no_info node is triggered, returning the response to the user: "Sorry, there is no information for your request". If the text is not classified as other, the extract node is triggered, which extracts entities from the text to create a summarized resume or vacancy. Then the retriever node ranks relevant resumes or vacancies from the vector database based on the received text, and the answer node formats this data in the required format and returns it to the user. How exactly the user receives them will become clear in the Deploy section.
Deploy
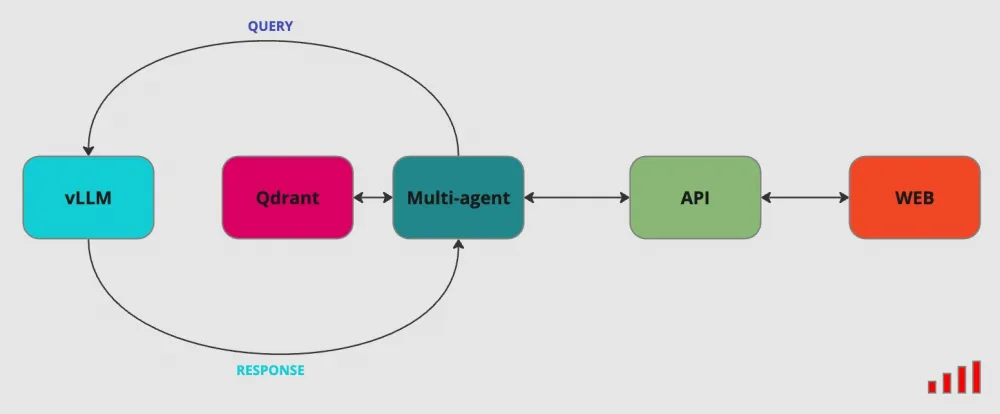
Let's briefly discuss the client part, which consists of backend and frontend sections. Let's analyze them in turn.
Backend
The backend was implemented using FastAPI. With the help of this framework, two endpoints were created: a POST request to send a file with a resume or vacancy, and a GET request to receive all selected candidates from the RAG side.
Frontend
The UI was developed using the Angular framework. The application provides for the selection of a category (resume/vacancy), activity (e.g., frontend, backend, and devops), and uploading files in (.txt, .pdf, .docs) format. After sending the request, the user receives a ranked list of relevant vacancies that require special attention from the candidate after some time.
Conclusion
In conclusion, I would like to note that despite the achieved ranking metrics, the system does not fully cope with the task. For testing, vacancies were synthesized, and after receiving the results, it became clear that the system does not always take into account fields with low content. I think this is due to the content of the "description" field, as it contains more information about the candidate compared to other fields.
The Advisor project will be further modified. It is planned to try using bert-like models and train them on the NER task, as this will significantly increase the response speed of the RAG system. It is also worth paying attention to vLLM, which, according to this article, is capable of increasing data processing speed.
Regarding the result... I think it is worth paying attention to data processing and trying to re-rank the RAG system result, taking into account the additional weight of the field with low content.
I look forward to your questions and comments!
To be discussed
What should be improved or replaced? What is the reason?









Write comment