
- Hardware
- A
What are T1 Cloud GPUs made of? Photo review and use cases
Hello, tekkix. This is the T1 Cloud team. If you keep up with the news in the server GPU world for ML, you surely know about the Nvidia H100—the computation powerhouse of a GPU, which doesn’t even have a video output. It plays an important role in machine learning, big data analytics, 3D modeling, and much more. This is enterprise-level hardware, so unless you’re one of a few hardcore enthusiasts, you probably won’t have one at home.
Today we’ll share a brief hardware review of servers with these graphics accelerators and talk about the tasks our colleagues, clients, and other companies use them for.
Comparison with the previous generation
You can read detailed specs on the Nvidia website. If you don’t feel like it, here’s a quick rundown:
The Nvidia H100 is based on the Hopper architecture.
Fourth-generation NVLink tensor cores and Transformer Engine module with FP8 precision provide acceleration compared to the Nvidia A100 GPU in the following tasks:
Fourier transforms — up to 6x faster;
whole genome sequencing — up to 7x faster;
AI model training — up to 9x faster (without NVLink — up to 5x);
AI inference — up to 30x faster.
Let’s get hands-on
We deployed a cloud cluster with graphics accelerators, each server equipped with eight GPUs. One such server weighs about 40 kg, comparable to a cheetah or leopard. Maximum power consumption at full load is up to 3.8 kW.
Server specifications:
Two AMD EPYC 9374F 32C 3.85 GHz processors;
1.5 TB DDR5 4800 MHz RAM;
Eight Nvidia H100 GPUs. Each card has 80 GB of memory;
GPU interface — PCIe Gen5: 128 GB/s (64 GB/s per direction);
Two Mellanox ConnectX-6 Lx 10/25GbE SFP28 2-Port network cards;
One Emulex LPe35 002 32Gb 2-port PCIe Fibre Channel (FC) adapter.
Now let’s see what the server looks like in real life. After removing the cover, here’s what you’ll see:

A few explanations.
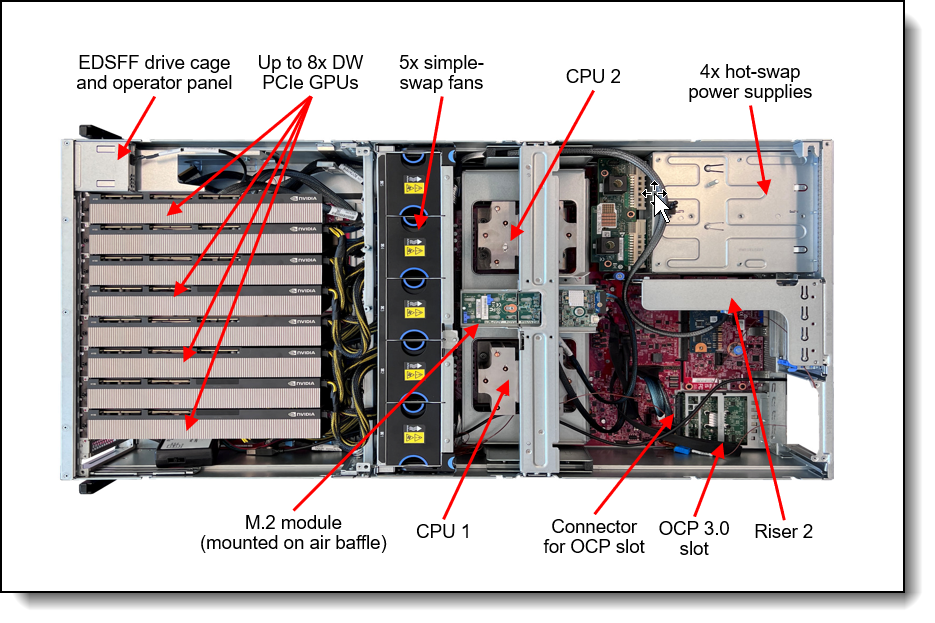
In a standard 42U rack, instead of 14 regular servers, you can fit just three with Nvidia H100s. That’s due to their high power consumption—up to 380W each.
The black squares on the graphics accelerator are NVLink buses with 600 GB/s bandwidth. They connect two adjacent cards. In total, there are four such pairs in the server.
Why the CPU also matters
Computing performance depends not just on the GPU specs. CPU characteristics affect the performance of the whole scenario or script running on the VM. For example, data needs to be moved from disk to memory and then to the GPU, plus additional operations like downloading something from the network. To prevent the CPU from becoming a bottleneck, the architecture of each GPU server is based on two AMD EPYC 9374F 32C processors at 3.85 GHz and 1.5 TB RAM.
About the cluster
We have assembled Nvidia H100 servers into a virtualization cluster. Accordingly, the cards are supplied to the virtual machine.
If you want to rent this beauty from us, note that you can order up to 8 cards per virtual machine. We have ready-made templates for deploying different numbers of H100 (as well as A100) graphics cards. If you need more performance, you can order a second VM that operates on a second server.
Use cases
SayBox
As one of the examples, let's talk about our service, which consumes GPU H100 computational resources from the cloud. This is the SayBox platform for AI application developers, development teams, business users, as well as specialists and enthusiasts in Data Science. The platform provides access not only to computational resources for working with ML models but also to tools for creating, applying, and integrating AI-based services. For example, developers and data scientists can train and run open ML models available on the platform without unnecessary infrastructure deployment costs.
Through SayBox, you can get the necessary GPU resources and quickly deploy open-source models from the global Hugging Face repository. SayBox allows users to launch such models by creating local copies in the cloud. For example, our team tested two generative AI models with 72 billion parameters and different architectures: Qwen/Qwen2.5–72B‑Instruct (simpler) and Qwen/QVQ-72B‑Preview (new). The first was launched on one node with two H100 GPUs, and the second on a cluster solution of two nodes with four H100 GPUs. Meanwhile, the local copies of these models were hosted on cloud servers.
With SayBox, you can solve various applied tasks: train and run large language models (LLM) for text, code, image, and video generation, create intelligent assistants for recruiters that can analyze resumes and recorded dialogues with candidates, then create summaries. If necessary, you can teach the model to record candidate data into the HR system. In industry, pretrained computer vision models help in real-time monitoring of the presence of workwear, helmets, and other protective gear on employees, visually inspecting the quality of finished products, such as labels and markings.
The platform is in open beta. If you want to try it, leave a request for a trial account, which SayBox provides together with T1 Cloud. The first month of GPU power is free: quickly train models with minimal costs, share feedback, and contact us if you need consultation.
And a few more examples
Now, about the tasks that companies, including our clients, solve using H100 computational power.
Credit and financial sector:
Development and training of LLMs (large language models), creation of digital assistants based on them. Such assistants can handle customer inquiries, create strategies for accumulating funds in bank deposits, and much more.
Processing large volumes of financial data in real time. Using AI, organizations predict stock and currency prices, analyze the profitability of various instruments, and assist investment funds and private investors in making asset purchase decisions based on this data.
Training complex ML models that help analyze the financial history and other data of clients in order to assess their creditworthiness.
Collection and analysis of real-time transaction data. This allows companies to quickly detect suspicious activity and prevent fraud.
Retail and e-commerce:
AI rendering of graphics. Using artificial intelligence, designers create attractive, photorealistic product images for website and marketplace listings.
Intelligent document analysis. Neural networks help automatically find relationships, influences, discrepancies, and regulatory compliance in unstructured text documents, technical specifications, and more.
Creation and training of generative AI which can quickly process and analyze all possible causes of sales drops, competitor tactics, various events and disruptions, and then use this information to make decisions about next steps.
Industry:
Development of specialized language models (FLM). They participate in designing production processes and industrial facilities, for example, oil and gas wells, quarries, and mines.
Processing, visualization, analysis, and interpretation of data accumulated over decades in corporate business systems.
Development of video analytics solutions based on neural networks. Some of the most in-demand cases include personnel discipline control, visual quality control of finished products, including label and marking verification.
Medicine:
Processing data from diagnostic equipment. For example, computer vision technologies recognize X-rays and ultrasound video data in seconds.
Creation of a 3D patient model using neural networks: it takes into account anatomical features, lifestyle, and other parameters. Doctors test therapy methods on this model and develop personalized treatment plans.
Development and training of AI assistants for doctors. Such assistants understand the context of patient conversations, recognize audio recordings of visits, automatically fill in electronic medical records, systematize data, generate discharge summaries, and more.
If you want to test H100 or have any questions about the cloud service, contact us.






Write comment