
- AI
- A
METR Research: Using Cursor Slows Down Experienced Developers by 19%
It is considered an established truth that code autocompletion tools and other assistance from large language models help to program faster. A study by METR calls this fact into question and even demonstrates the opposite effect.
In the analysis of the work of 16 programmers, it was found that AI slows down a person by 19%. This contradicts the opinions of experts in the machine learning industry, economists, and the experiment participants themselves. It is important to note that the test was not conducted on benchmark tasks or proposals to solve algorithmic problems quickly, but in the usual work of people.
AI Everywhere
Artificial intelligence based on large language models (LLMs) is designed to quickly replace human labor in various fields of knowledge. Perhaps the limited context window of early models did not allow for writing a new great novel, but the high practical value was immediately evident. AI development companies began to look for which profession to eliminate first.
After the release of GPT-4, OpenAI researchers proudly announced that the model had passed the US lawyer exam better than 90% of people (arXiv:2303.08774). This was followed by a wave of laudatory articles seriously discussing how LLMs could replace lawyers (1, 2, 3).
It was only later that the rethink was announced. It was pointed out that GPT-4 performed well on the test part but was lacking in two other aspects. Moreover, the comparison with humans was made based on the February exam, where those who failed in June usually retake it.
In general, American lawyers were greatly interested in such loud claims from OpenAI. In addition to repeating the experiment with passing the exam (doi:10.2139/ssrn.4389233, doi:10.1007/s10506-024-09396-9), GPT-4 was tested as part of an empirical study (doi:10.2139/ssrn.4539836). In this experiment, the LLM complemented the human rather than replacing them. For this, two groups of students were tasked with solving a legal exam from one of the 2022 versions. One of the groups used GPT-4 during the exam. With access to the technology, weak students sharply improved their results, but no such effect was observed for strong students. GPT-4 helped formulate facts and apply rules more clearly, but the answers often missed hidden questions, relied on a template structure, and referred to fewer court cases.
The performance of GPT in this field is considered low. In another study, ChatGPT was rated at the level of a diligent C-student (10.2139/ssrn.4335905).
In principle, one can even forget about the 207 amusing cases when GPT hallucinations were found in the case materials — Damien Charlotin maintains an interesting list on his personal website here. Even then, the actual applications of AI in legal practice remain limited.
Lawyers have long been promised that automated contract analysis will replace manual proofreading, but even flagship solutions like Kira highlight that this is only about speeding up the search for common errors, not strategic legal work. A similar picture appears in predictive analytics: services like Lex Machina and Premonition use AI to assess judges' tendencies towards certain decisions, but evaluations indicate that accuracy is limited by the volume and homogeneity of data, and the discipline is far from maturity.
A similar situation is observed in medicine: the promotional statements that are often cited in the media and the much more modest reality of popularity.
Med-PaLM, GPT from Google, passes the US medical exam, and this fact is stated directly on the project's homepage. This refers to the three-stage United States Medical Licensing Examination or USMLE, required for obtaining a medical license in the US. The exam is strict (each stage can only be failed four times in a lifetime), expensive (around a thousand dollars per stage), and long (the first two stages require a whole day to complete, and the third takes two). As Microsoft found, GPT-4 also successfully passes the USMLE (arXiv:2303.13375).
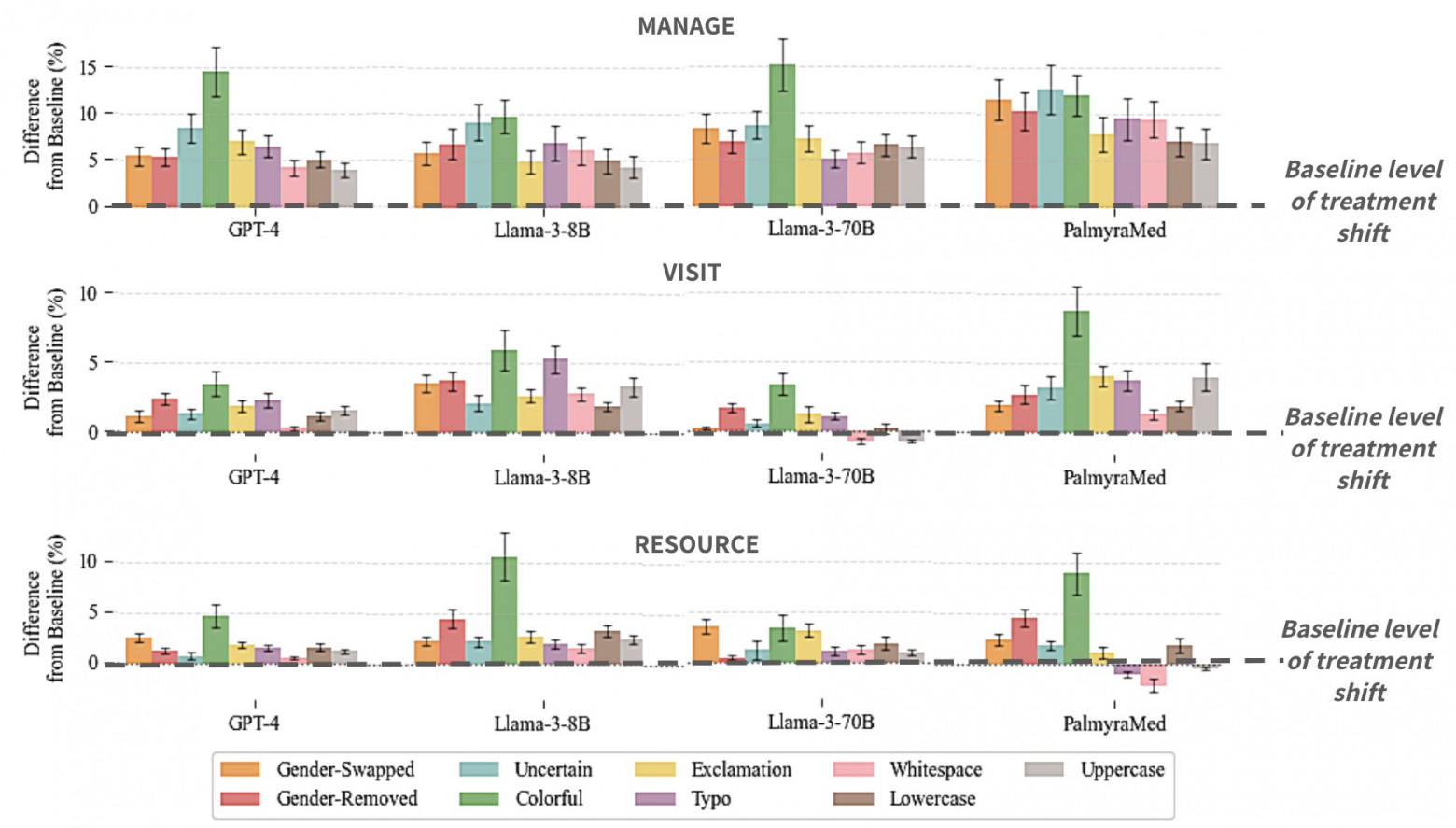
Taking exams is not the same as clinical practice. People like to introduce surprises into the input data. Even in tests it has been found that small typos or unexpected tone of speech drastically reduce GPT's performance on medical questions (doi:10.1145/3715275.3732121). As it turned out, clinical details of user queries significantly affect the response. For example, if the patient's gender is changed to female in the prompt, the model is 7.8% more likely to suggest continuing to observe at home.
However, even without this, doctors are not thrilled with AI. In a 2023 study, patients answered 200 questions, and both ChatGPT and real doctors were involved (doi:10.1001/jamainternmed.2023.1838). AI was more empathetic but still gave erroneous or incomplete recommendations in a significant number of cases.
In the study above, the GPT-3.5 model, which was weak by current standards, was tested, so much can be attributed to its primitivism. Also, the media wrote more about the empathy of the model. However, similar unacceptable hallucinations were observed in a similar 2024 study, where GPT-4 AI was tested against humans (doi:10.1001/jamanetworkopen.2024.25953).
Large clinics, relying on such results, use AI strictly as limited human assistants. For example, at Stanford University Medical School, Nuance Communications' DAX Copilot product was implemented solely as a scribe. The AI itself drafts the intake, but the doctor is required to check and sign the document.
Doctors are cautious in applying AI. It is well understood that ChatGPT's mistakes could lead to lawsuits for medical negligence until courts and legislators define clear rules of liability (doi:10.3389/fsurg.2024.1390684).
It is much easier and safer to implement AI in programming. A slow script on a web page will not lead to lawsuits.
Initial Promises
After the appearance of popular AI, it was almost immediately stated that AI would, if not completely replace programmers, at least significantly help in writing code.
For example, in 2022, GitHub reported that Copilot significantly increased the productivity of software developers. At that time, Copilot was based on OpenAI Codex AI, trained on publicly available code from GitHub and considered a powerful model for performing programming tasks (arXiv:2107.03374).
In the GitHub experiment, participants with AI were more likely to complete their task compared to people without such a tool—78% versus 70%. It was reported that the Copilot-powered group of developers solved tasks 55% faster than the group without this tool. Meanwhile, in surveys, 88% of respondents said they felt more productive with Copilot.
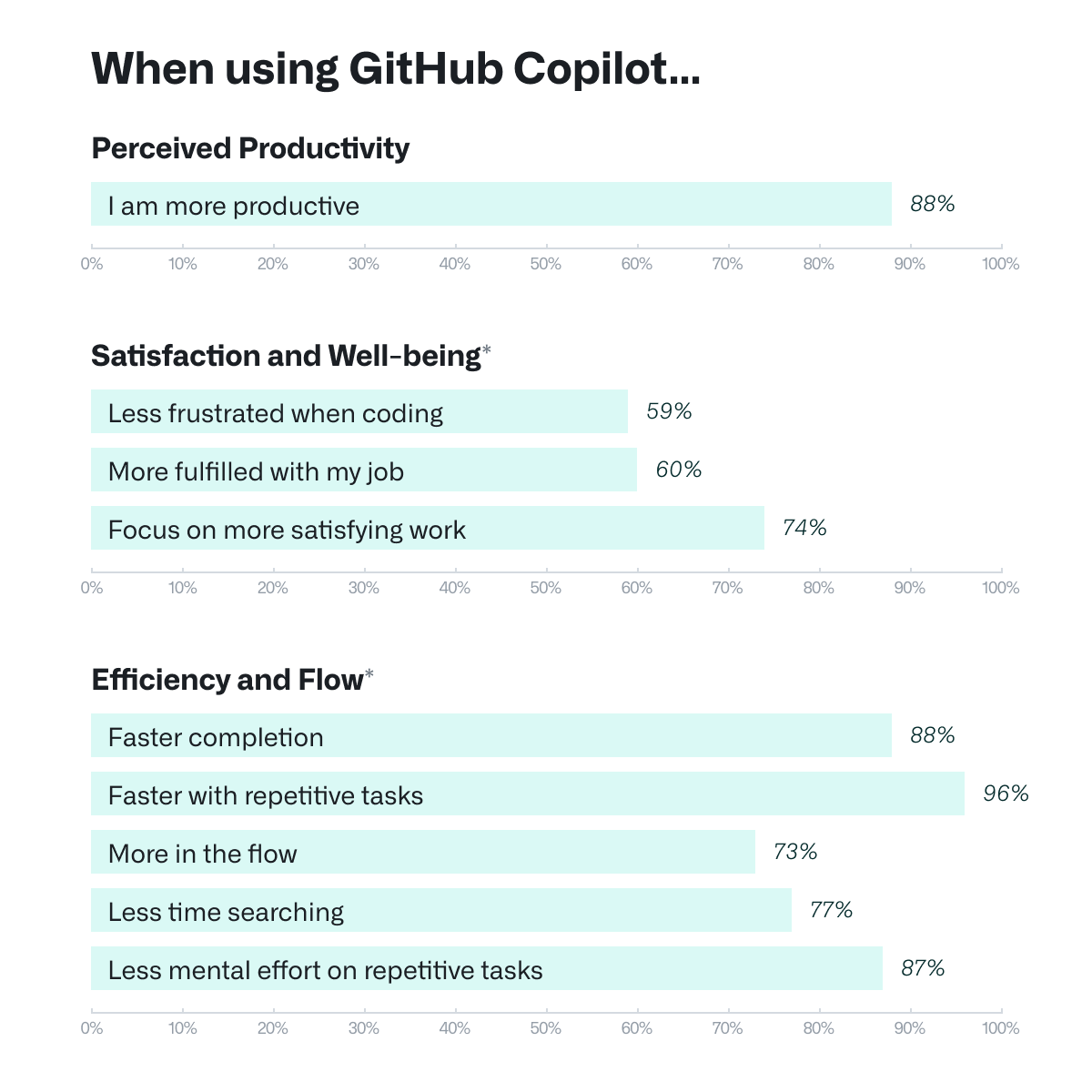
Similar studies are quoted in promotional statements for other similar tools. Amazon uses such data to recommend CodeWhisper, its competitor to GitHub Copilot, stating that developers equipped with AI complete tasks 57% faster and finish tasks 27% more often than programmers without AI assistance.
The GitHub experiment was conducted under artificial conditions: 95 developers were given a typical task—write an HTTP server in JavaScript. However, a similar trend was demonstrated by other studies investigating the usefulness of AI "in the field".
For example, in a 2024 Google report, a study was described on randomly selected company employees (arXiv:2410.12944). It was stated that for the observed employees, the use of AI in their work increased productivity by 21%, albeit with a larger confidence interval. This number was slightly lower than the reported 33% productivity increase in 2023 from Duet AI, another Google tool.
Similar studies exist for GitHub Copilot and Amazon CodeWhisper. For the former, there are several scientific papers showing a significant jump in developer productivity when using AI (arXiv:2409.08379, Harness, Faros). For the latter, testimonies from eyewitnesses are often cited. For example, BT Group reported that in the first four months, Amazon's AI generated over 100,000 lines of code and helped automate 12% of the repetitive tasks of a typical company programmer.
It is important to note that this data does not remain forgotten as quotes from scientific papers or easily dismissible marketing claims. Executives love to talk about the benefits of AI to assure investors of following the global trend of AI implementation wherever possible.
This does not always mean that everything is updated according to the latest data. For example, the annual 2024 shareholder report from Microsoft, authored by company CEO Satya Nadella, cites the same number (55% improvement), which first appeared in the 2022 GitHub study.
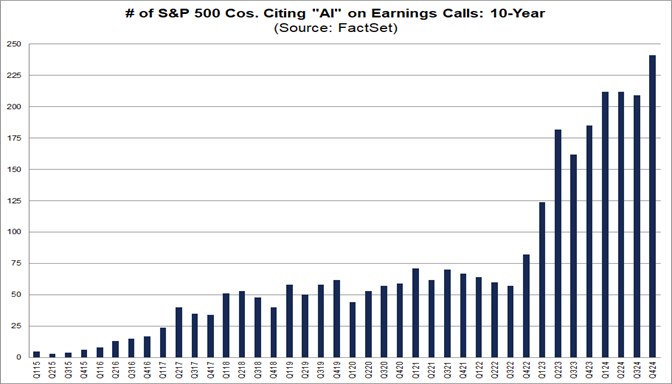
The trend is global. Almost half of the companies on the list of the leading American industries, the S&P 500, mention AI in some form during investor conference calls with financial results mentions. It's not just the tech sector—AI is discussed by public companies in healthcare and finance sectors. Talking about AI implementation is beneficial: a 2025 study found a statistically significant effect on stock prices when ChatGPT was mentioned in reports to the U.S. Securities and Exchange Commission (doi:10.1186/s43093-025-00470-5).
It is natural that such breakthroughs in the development of AI lead to statements about the imminent death or at least a significant reduction in demand for the profession of a programmer. Recently, Mark Zuckerberg even said that middle management will soon be replaced by AI.
In the media, mass layoffs of developers are often associated with replacing humans with artificial intelligence. Even the companies that are making the news are not shy about such statements. On July 9, Bloomberg revealed citing its own sources that Microsoft’s Chief Commercial Officer, Judson Althoff, explained this in an internal presentation.
Microsoft employees were told that AI saved half a billion dollars last year just on call centers and will further increase labor productivity everywhere: from sales departments to software development. This news fits well with recent reports about mass layoffs of developers at Microsoft.
Harsh Reality
Layoffs are unlikely to be related to AI.
It’s easier to talk about correcting the excessive hiring during the global COVID remote work period than about the sudden replacement of humans with AI in code writing. Even now, most major American tech companies have more employees than they did before 2020. For some reason, there has been no sharp decline in the number of programmers, and if there is any stagnation in hiring, it is insignificant.
Some studies report that no significant increase in productivity has been observed. One such report is a 2024 report from Uplevel, a startup measuring developer productivity. The document states that programmers using Copilot introduce 41% more bugs, but overall productivity remains almost unchanged.
Another large-scale study that casts doubt on GitHub's promotional claims was conducted by GitClear in 2024. This analytics company claims to have the largest and most detailed database with structured information on code changes.
GitClear's commit data is even more comprehensive than that of GitHub, GitLab, and Bitbucket. The data is divided not only into additions or deletions, but into 7 different categories (addition, update, deletion, insert/copy, find/replace operation, movement, whitespace manipulation). GitClear had about a billion modified lines, of which 153 million were analyzed.
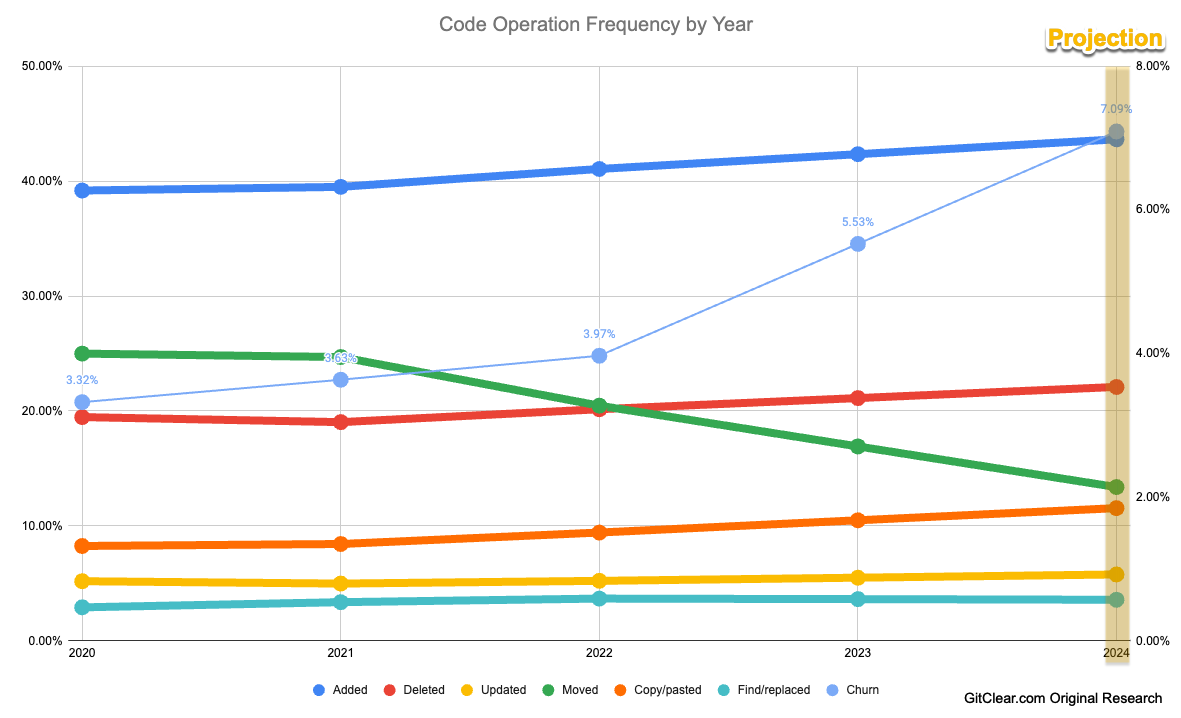
The study suggests restoring the real picture of what is happening through a creative interpretation of statistics. If the share of code that was moved has fallen since 2022, it is due to a decrease in the frequency of code refactoring because of the emergence of ChatGPT and Copilot. Autocompletion tools like Copilot create the temptation to write something from scratch rather than reuse existing code, violating any DRY principles. As it was found, code is increasingly added, not modified.
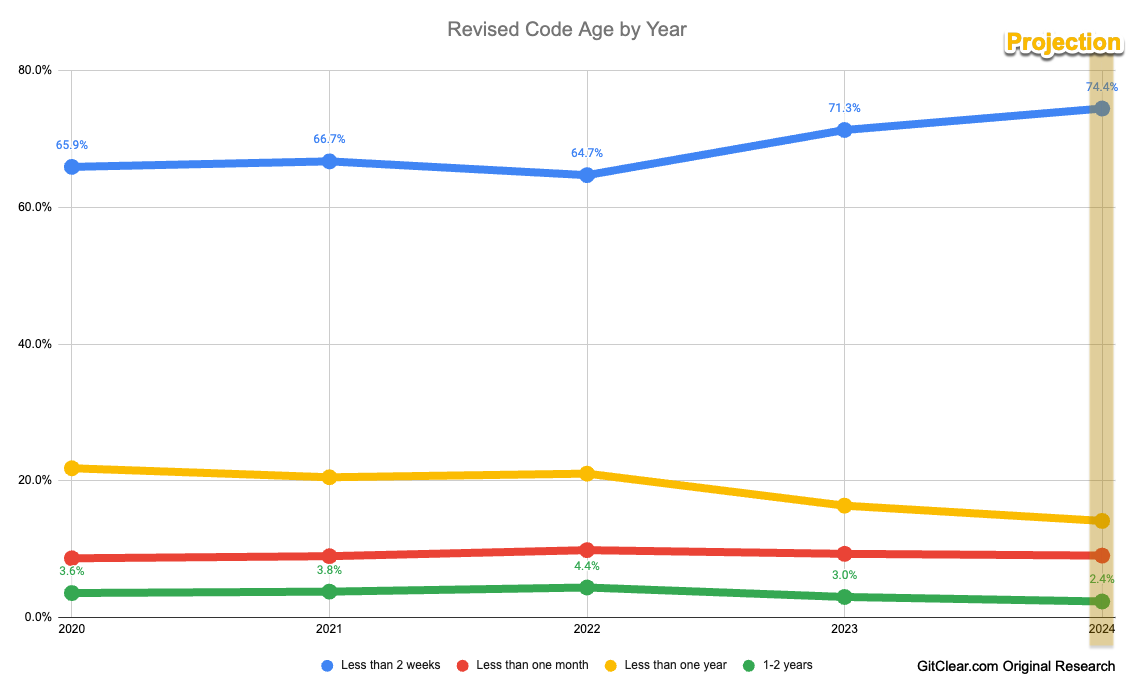
Additionally, the GitClear report assessed how much time passed between adding code and its subsequent update or deletion. The trend is similar: in 2022 and 2023, code remained unchanged less frequently than in 2020 and 2021. In 2023, the share of code that lives at least 1 month without modifications dropped from 25.5% to 19.4%. These cutoffs are not arbitrary. In agile development methodologies, after 2–3 weeks of a sprint, the team conducts a retrospective, where they discuss how to find new uses for code in the next sprint.
Opinions about AI vary. In the 2024 Stackoverflow survey, 43% of respondents say they highly appreciate the accuracy of these smart tools. 31% of respondents are skeptical. At the same time, beginners are more inclined to trust AI than professionals (49% vs. 42%).
METR Study
Model Evaluation & Threat Research (METR) can be seen as a logical development of ARC Evals. The latter was an internal team of the Alignment Research Center, an organization founded by American AI researcher Paul Christiano. In December 2023, METR became an independent entity. Like ARC, METR is a non-profit organization. The head of METR is still Beth Barnes, a former OpenAI employee.
METR’s task is to systematically search for dangerous abilities, not just run LLMs through standard benchmarks to determine their accuracy or speed. For example, the organization conducted a detailed analysis of Claude 3.7 Sonnet and did not find dangerous levels of autonomy in the model. In another case, it succeeded in deceiving the LLM o3.
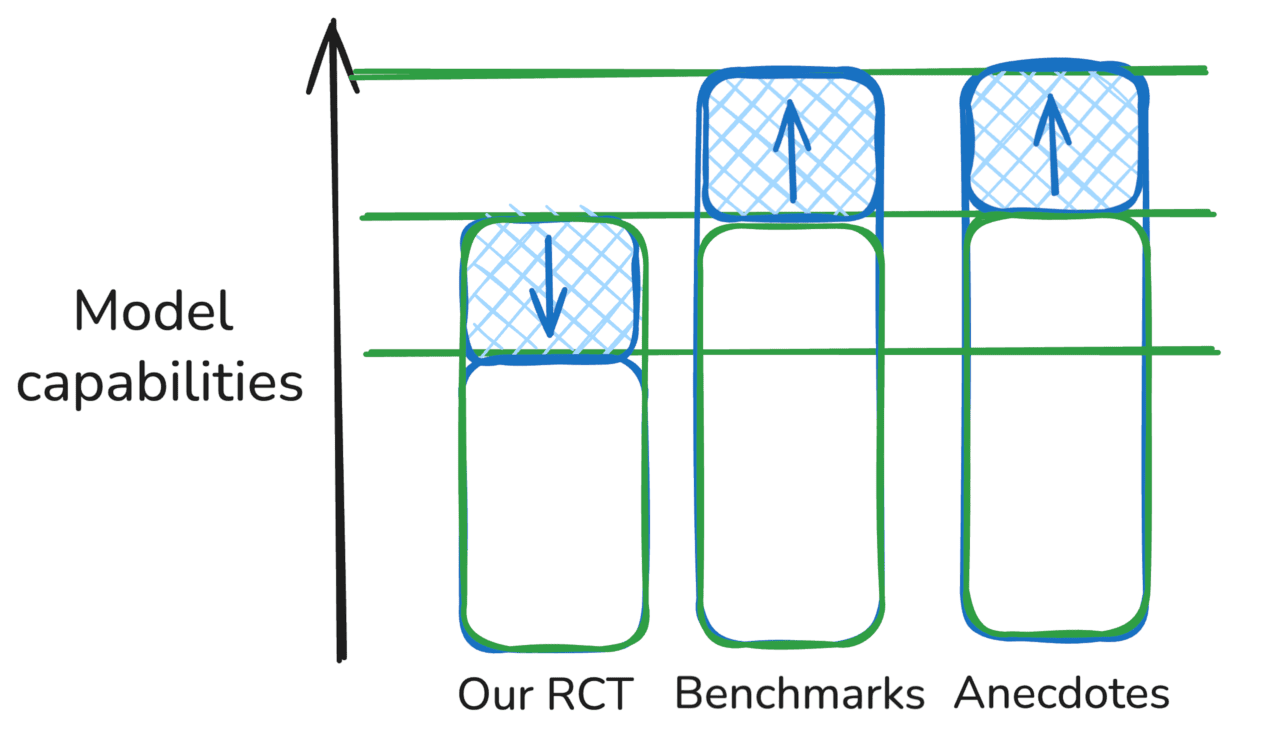
METR still evaluates models and develops its own benchmarks, but not for nice numbers, but for in-depth analysis. In March of this year, the organization presented a study in which it assessed the capabilities of the newest LLMs at the time to perform tasks over extended periods (arXiv:2503.14499). For this, a new metric was introduced: the time horizon for 50% task completion (50%-task-completion time horizon). This refers to the time required for humans to perform tasks that AI can complete with a 50% probability.
As it turned out, for Claude 3.7 Sonnet, the 50% task completion time is 50 minutes — meaning that tasks requiring nearly an hour for a human can be handled by BAI. Comparing the trend, for flagship models, this time doubles every 7 months. Based on this, METR concluded that within 5 years, artificial intelligence systems will be able to solve tasks that require a whole month of human hours.
In general, METR likes to contrast humans with machines. For the 2024 study RE-Bench, various BAIs and human developers were asked to perform programming tasks (https://arxiv.org/abs/2411.15114). It turned out in this benchmark that AI performance does not improve significantly with additional time for a task, although extra hours are greatly beneficial to humans.
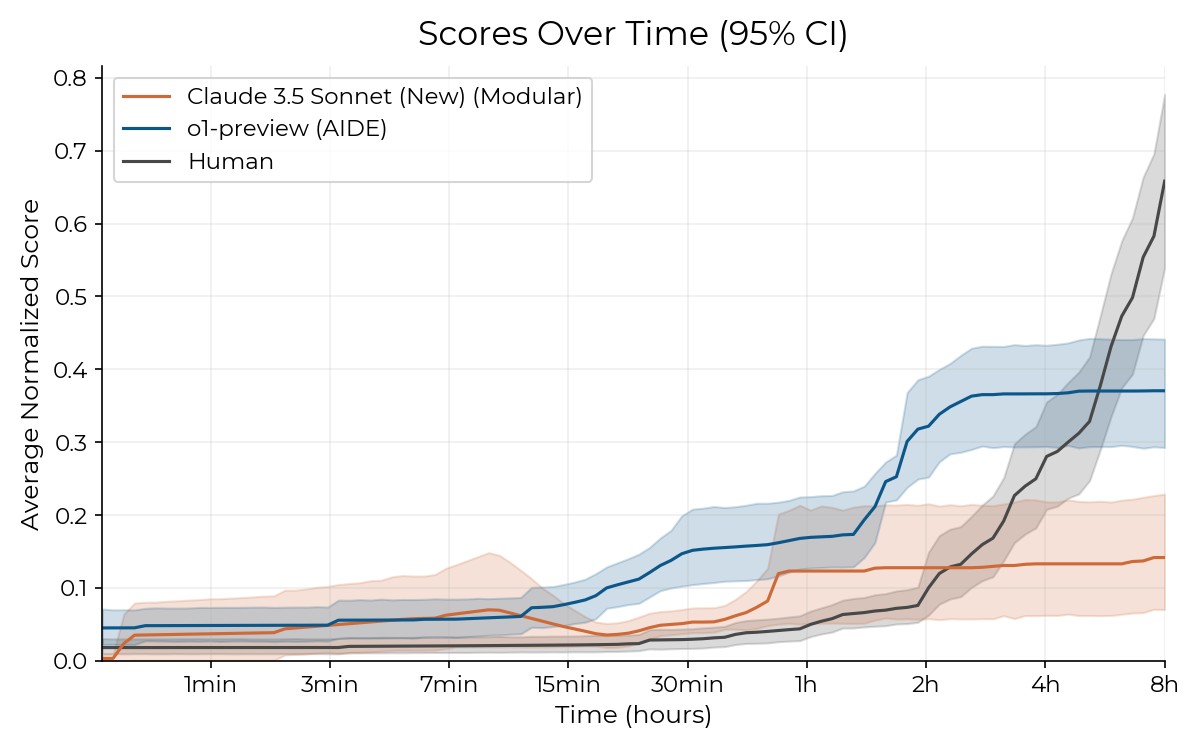
Interestingly, for RE-Bench, many highly representative programmers of good level were found: 43 experts from METR’s professional contacts, job-seekers at METR, and already screened 11 applicants and 7 graduate students from several universities — a total of 61 people. Each participant spent a lot of time — up to 8 hours per attempt at solving a task in RE-Bench. Some solved more than one problem, and from the 61 participants, a total of 71 attempts at solving tasks were accounted for.
Additionally, METR did not skimp on finding professionals for the new study “Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity”, published on July 10. The goal of this experiment was to compare how much AI actually helps a programmer. To do this, 16 participants from large open-source projects were involved.
To form the pool of potential participants, METR's professional contacts, machine learning community (subreddits /r/Python and /r/MachineLearning), and the 250 most popular machine learning repositories on GitHub were used. An important selection criterion was active participation in a large and mature open-source project. In terms of requirements, participants needed to have made at least 5 commits in the last 3 months to a repository with more than 3,000 lines of code and at least 500 stars. METR could waive the last criterion if the project was indeed mature.
As a result of the selection funnel, 20 individuals were chosen from 51 interested parties. A few dropped out for reasons unrelated to the experiment, and the final report includes only 16 participants.
The selected sixteen are high-level developers, typically with a decade of experience or more, although at least one year of professional employment and six months of managing open-source projects were generally requested. The projects they committed to during the experiment turned out to be much more popular than the selection criteria required. On average, the project garnered 23,000 stars, 4.9 thousand forks, 20,000 commits, 1.1 million lines of code, and 710 committers. An incomplete list of repositories (three anonymized) is provided in Table 8 of Appendix G.7 research report.
Participants were well compensated ($150 per hour). By the way, up to 5 hours were spent on onboarding, coordination calls, and post-experiment reviews, which were also included in the paid time. A total of up to 40 hours was paid.
Another line item in the experiment's expenses was 13 Cursor Pro subscriptions ($20 per month). Interestingly, 3 out of the 16 developers already had their own subscription, so nothing was purchased for them. The study compared the speed of work with and without AI assistants, with the Cursor code editor serving as such a tool.
Pro is not the most expensive Cursor plan: Pro+ costs $60, and Ultra is $200 per month.
In the 13 cases where subscriptions were purchased by the researchers, statistics were collected from the Cursor dashboard. From this, it is known, for example, that participants in the experiment preferred the Claude 3.7 Sonnet model in normal mode and thinking, Claude 3.5 Sonnet, and GPT-4o. Most issues were closed in February-March, before the release of Claude 4.0 Opus or Gemini 2.5 Pro, although the latter still accounted for 3% of requests.
Developers were asked to maintain an issue list to measure progress. In response, they provided 246 tasks that participated in the study. Participants were also asked to estimate how long it would take to close an issue without AI and with its help.
Additionally, 34 economists and 54 machine learning experts gave an evaluation of the experiment's progress. They were briefly introduced to the work and asked to predict the outcome. These experts were not paid for their work but were offered a floating (depending on accuracy) reward formula in the form of a stake, where they could win up to $50.
During the experiment, developers closed their issues. With a 50/50 chance, it was decided whether the participant would solve the task entirely independently or with the help of AI. In the first case, the use of any generative AI was prohibited. Importantly, in the second case, if the developer considered AI unnecessary, they were not obliged to use it. The instruction said: "You can use AI as much or as little as you want."
By the way, not everyone was accustomed to the Cursor interface, which resembles VS Code — some had previously worked in Neovim, Pycharm, or other IDEs. If using AI wasn't required to complete the issue, many participants switched back to their preferred code editor. However, this experimental artifact is considered insignificant since no "adjustment" effect to Cursor was observed during the work. Also, no participants complained about a drop in performance due to the unfamiliar IDE during the exit interviews.
Actually, flexibility in the work process was allowed. Participants could, if they wished, work on multiple issues at the same time.
Upon completing the code, the developer would send a pull request. Usually, after that, the reviewer would evaluate the PR, the participant would make changes, and then merge the updated pull request. In this study, all repositories had good code quality and high review standards, so merges rarely contained flaws. After that, the participant would independently log the time spent working on the issue.
The course of the experiment looked exactly like regular work. The key difference was the mandatory screen recording for later analysis and analysis of statistics from the Cursor accounts.

The result of the experiment goes against the opinions of experts and the expectations of the participants themselves. If developers were allowed to use AI, they spent, on average, 19% more time to complete the tasks.
Despite this, the participants themselves, on average, believed that AI would reduce time costs by 24%, and even after the experiment, they claimed a 20% acceleration. Experts overestimated the role of AI even more: they predicted a 38–39% reduction in the time spent.
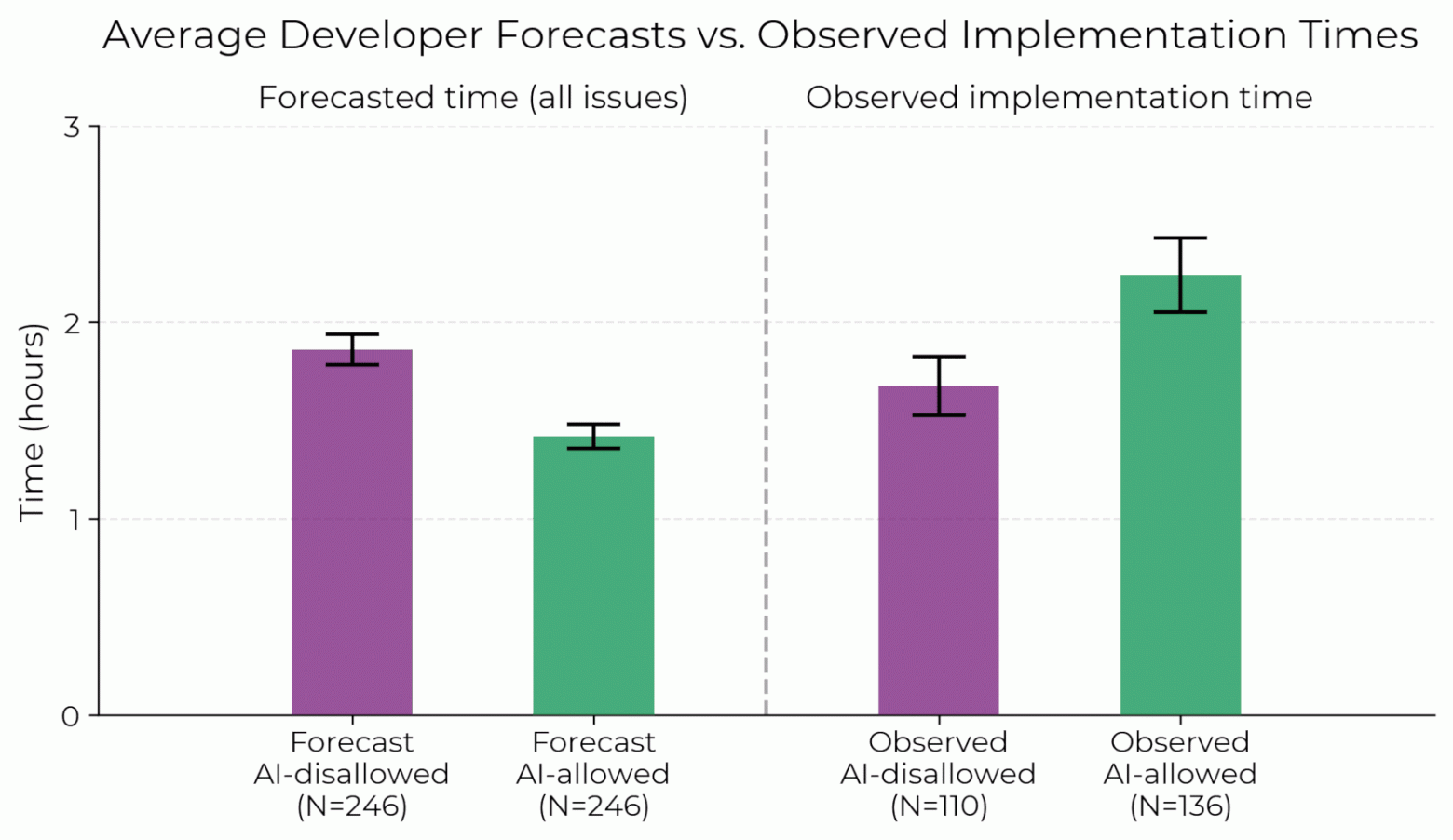
Why does time go by?
The numbers themselves don't mean anything without a clear interpretation. METR conducted a detailed analysis of the results.
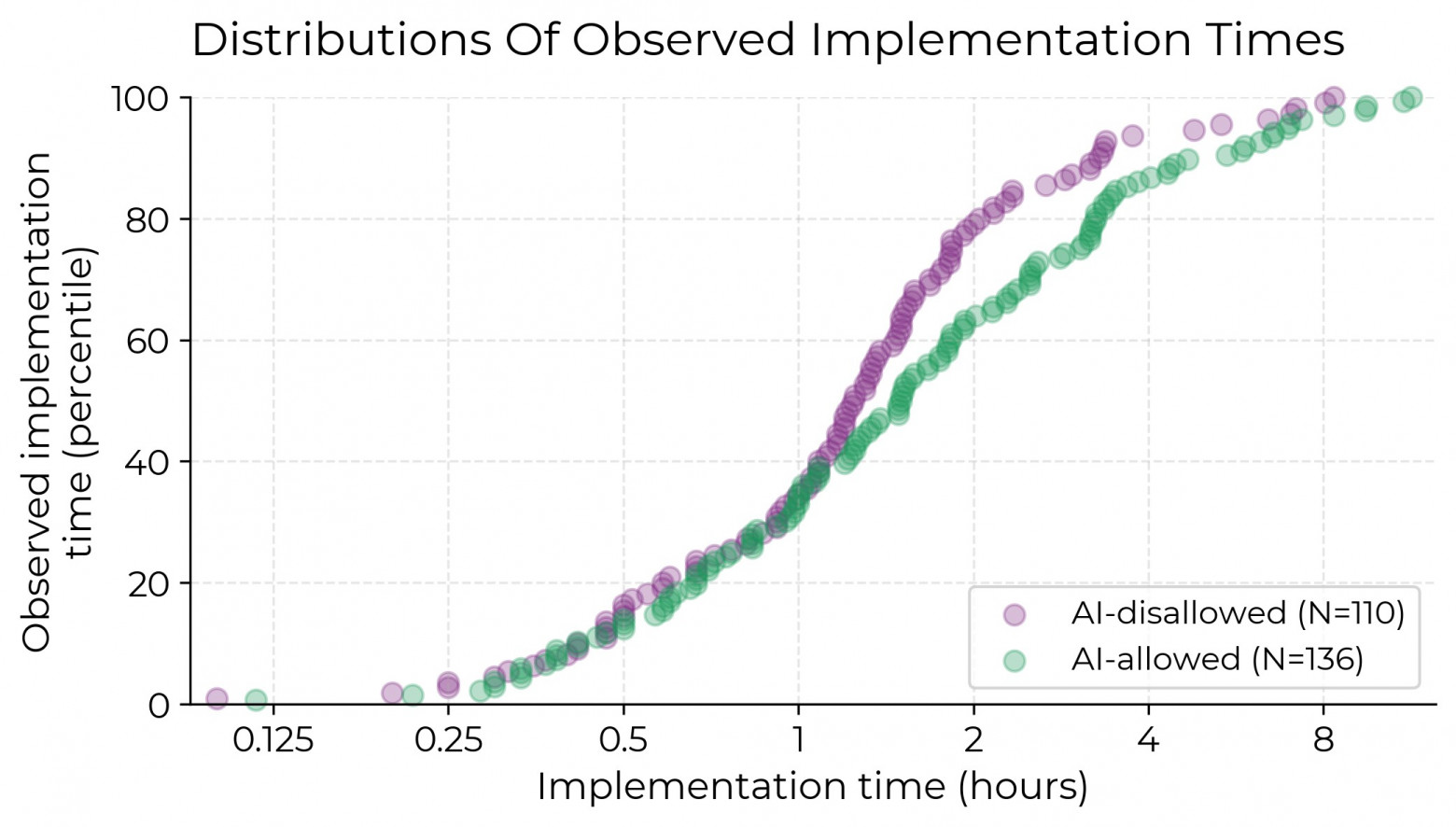
Although there were 246 issues, METR analyzed only 128 video recordings. These amounted to 143 hours of video, part of which revealed violations of the experimental conditions, such as gross (>20% difference) violations of time logging and long (>10%) missing segments. As a result, only 74 videos amounting to 84 hours remained.
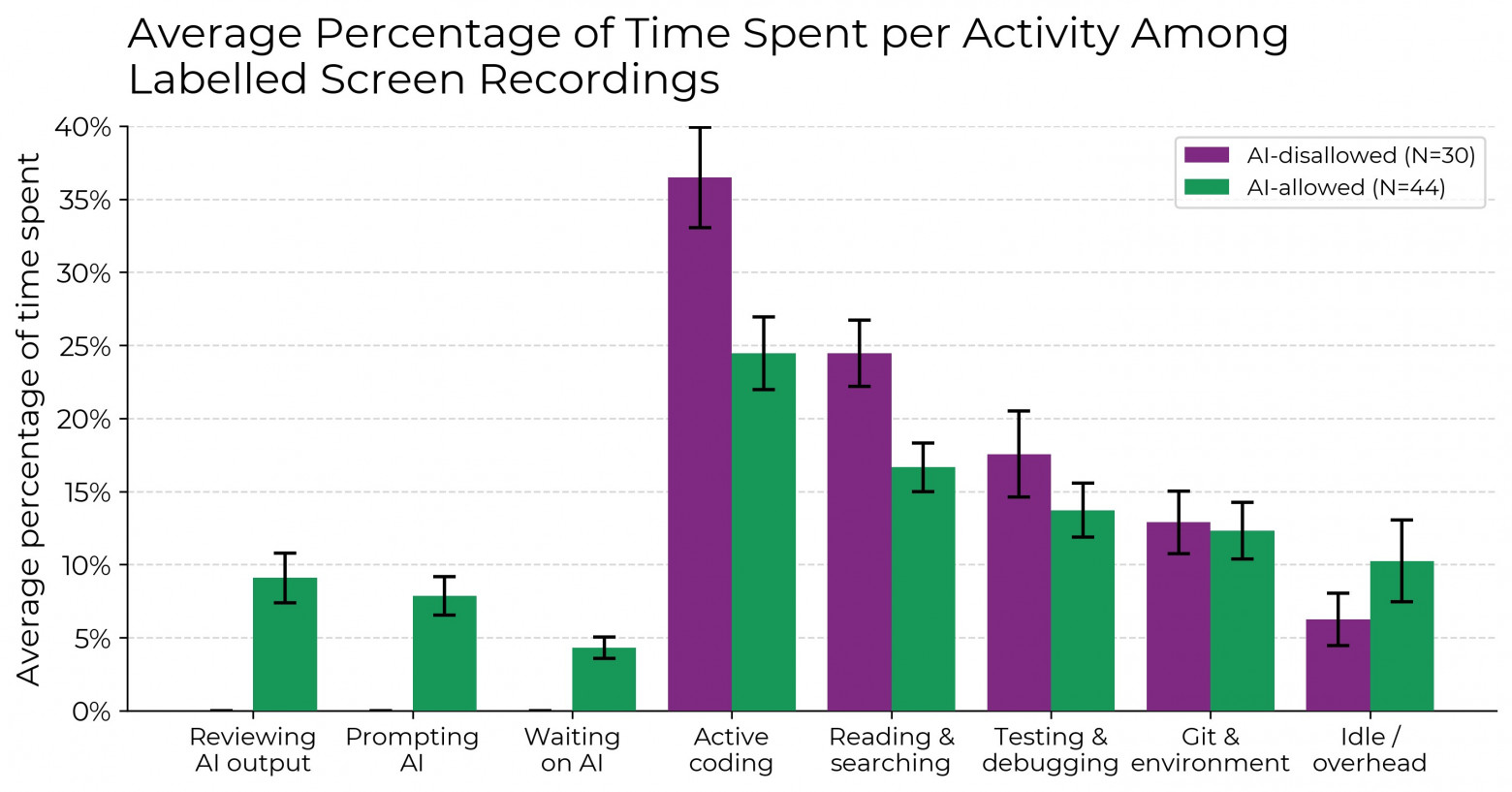
A huge effort was made, which METR outsourced to an unnamed group of people. With a 10-second resolution, each video was manually tagged for main types of activity:
Evaluation of AI system responses;
Prompting the AI system;
Waiting for the AI system's response;
Active coding;
Reading or searching for information;
Testing and debugging code;
Calling Git commands or managing their environment;
Inactivity or doing other work.
It is clear that with the ban on using generative artificial intelligence tools, the time spent using AI is zero. It is unquestionable that if AI is allowed, less time will be spent on other categories. However, unexpectedly, if AI was allowed, participants spent slightly more time apathetically staring at the screen.
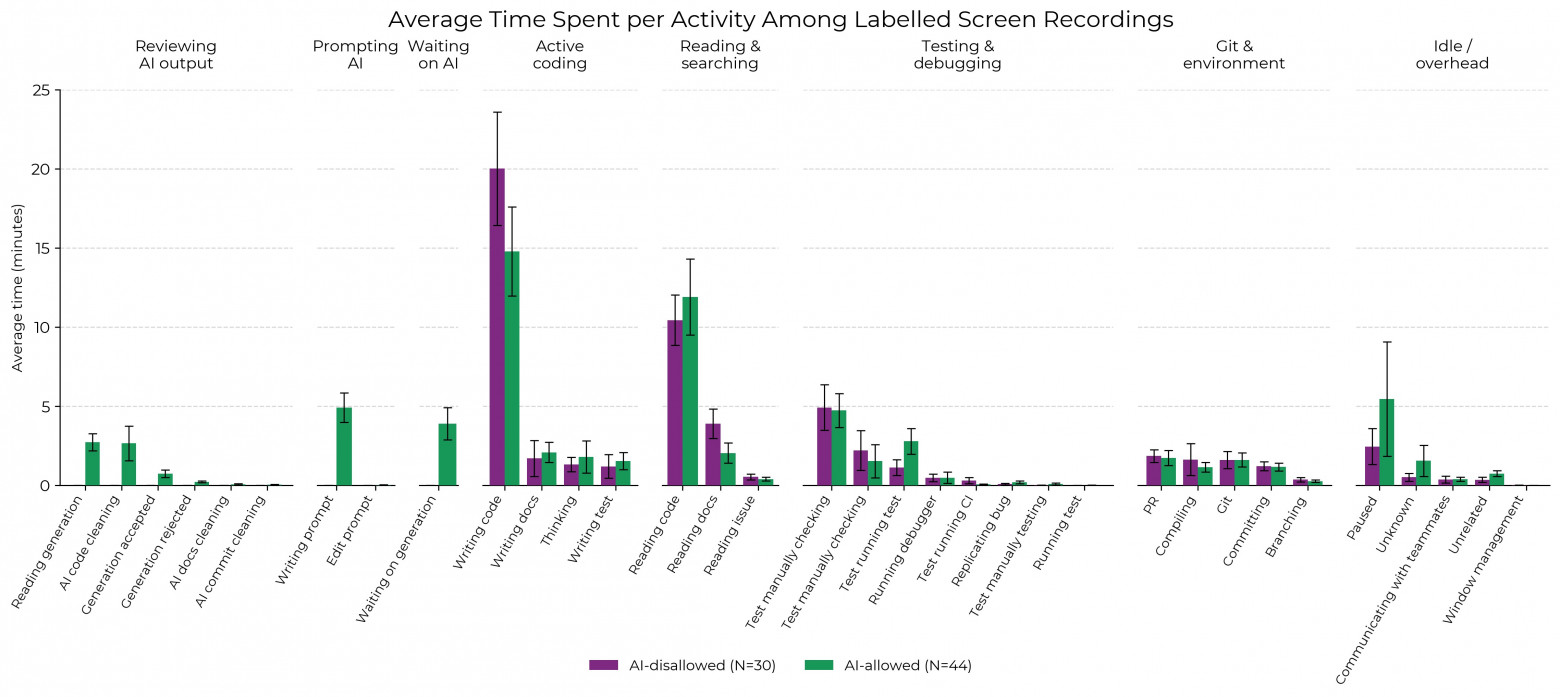
METR attempted to assess why AI slows down developers in this experiment. The study lists 5 reasons for this effect:
Excessive optimism. Even after the first experience of writing code with AI tools, developers overestimated the role of smart tools and continued to rely on them. Formally, participants were allowed to always do everything manually, including measurements using AI. However, developers still relied on the smart functions of Cursor.
High familiarity with the codebase. The developer is well familiar with the repository, which they have been working with for several months. The AI tool simply cannot be as effective.
As the participants admitted during the final discussion, AI helped with unfamiliar issues for the developer: it could generate basic frontend tests, introduce hooks in Git, or surprise with a function that the participant had never encountered before. However, in tasks where the person had developed expertise, the agent was only a hindrance.
The experiment participants have considerable experience in the profession. METR hypothesizes that this is why AI assistance was less beneficial in this case compared to other similar studies.
Large and complex repositories. As the participants shared, AI tools sometimes didn’t just fail to help but introduced errors that required time to fix. Researchers at METR suggest that this is why the results of their experiment differ from previous similar studies.
Low accuracy of AI. From the Cursor dashboard, it is known that participants accepted only 44% of the generated code fragments. This low percentage is illustrated by the story of one participant: after the first encounter with Cursor, they spent over an hour working with AI, after which they gave up and wrote everything themselves.
During the exit interviews, all developers admitted that they often had to correct the generated results. The extent of these corrections varied. Nine out of sixteen claimed the corrections were substantial, while others said it was only necessary to polish the style.
Implied context of the repository. In software development, an internal, undocumented understanding of the codebase inevitably forms. Researchers at METR believe this happened for mature repositories in the experiment.
This is confirmed by quotes from exit interviews, where participants complained about the AI's lack of understanding of specific backward compatibility cases and its wrong choice of where to make changes. One developer even compared the AI tool to a novice contributor.
The research report spans 50 pages, with other factors discussed in detail. METR considers the effect of nine of them unclear and refuses to account for them. These include excessive AI use by some participants (a similar effect is observed for those who used it as usual), unrepresentative task distribution (large issues over 2 hours were requested to be broken into parts, which can be useful for both AI and humans), and task volume expansion with AI (when AI helps, the participant might "add" unnecessary improvements; in reality, such developers slowed down even less).
The experiment participant was assigned a list of issues, where AI could and could not be used. The order of task execution was determined by the developer. One could expect that initially, they might choose "no-AI" issues, and then, when their energy runs out, proceed to tasks where AI could be invoked. On the other hand, the participants did not report any conscious prioritization. Although this effect cannot be completely ruled out, the METR factor is said to be unexamined.
Is it possible that developers continued to resort to BLM because it was more enjoyable and less stressful to write code with it? The feedback is contradictory. Some developers called working with AI less tiring, while others said it was just as tiring. At the same time, 11 out of 16 participants continued using Cursor after the experiment, which hints at some benefit, but the slowdown is not explained.
Reviewers did not notice any deterioration in the quality of pull requests, so it is hard to say there was any additional time spent on reviews. However, the time spent on post-review revisions slightly increased from 9 minutes (without AI) to 15 minutes (with AI).
The slowness of BLM generation cannot explain the 19% difference, as only 4% of the time was spent waiting for a response. Is it possible that the problem lies with Cursor, since typically, an IDE receives no more than a couple thousand tokens from the language model? METR considers this reason unconfirmed, citing similar examples in other studies where acceleration, rather than a decline in productivity, was observed under the same conditions.
Finally, six more factors were identified by the researchers as unrelated to the observed effect. Cursor differs little from its predecessor, VS Code, yet even with a preference for a different development environment, no "habitual" effect was found throughout the experiment. Fraud was excluded through data verification. Criticism of the measurement methods or statistical techniques does not neutralize the discovered effect.
For the integrity of the experiment, developers were required to complete all the issues assigned to them. Is it possible that participants avoided completing difficult tasks that had to be solved manually? Although most completed all the tasks, some developers indeed did not manage to close several issues that needed to be solved without AI assistance. Others failed to complete issues where the use of AI was permitted. However, when comparing all three groups, the same slowdown effect of roughly the same intensity was observed across the board.
With such a thorough analysis of their results, the METR researchers ask not to rush to conclusions. On the project page, the organization reminds that this study, conducted on 16 programmers, does not represent the entire industry. As the report reiterates, the productivity decline effect may be caused by the large size and maturity of the repositories, as well as the high skill level of the developers and their informal knowledge of the codebase. In such conditions, AI suggestions do not improve an already high level of expertise but only interfere.
Not without optimism, METR writes that future language models may be an order of magnitude more advanced. It is possible that someday even experienced software development engineers will not have to waste valuable time checking and correcting code from BLM. Ruben Bloom, one of the study participants, agrees: the developers were greatly impressed by the leap in models like Claude 4.0 Opus, Gemini 2.5 Pro, and o3 that occurred in the past six months.
On the research page, METR reminds us that progress is hard to predict. Five years ago, no one could have expected that primitive language models would be considered as replacements for experienced professionals.
The report "Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity" was published on the METR website. The authors of the study promise to release anonymized experimental data and project code on the organization's GitHub account.
The holding company Meta (1) is an extremist organization, and its activities are banned.










Write comment