- Security
- A
Breaking CityHash64, MurmurHash2/3, wyhash and more…
Hash functions are incredibly beautiful mathematical objects. They can map arbitrary data to a small range of fixed-size output data in such a way that the mapping is deterministic, yet appears random. This "deterministic randomness" is incredibly useful for a wide range of applications, such as hash tables, checksums, Monte Carlo algorithms, distributed algorithms without communication, and so on.
In this article, we will look at the dark side of hash functions: situations where things go wrong. Fortunately, this essentially never happens in real life due to bad input data (at least in the case of good hash functions). However, besides programs, there are also people, and not all of them are peaceful, so we should turn to the field of computer security for answers. I will briefly explain the basics of hash function security and then show how easy it is to break this security for some popular non-cryptographic hash functions.
As a teaser, I will explain how to generate thousands of similar strings in a second:
cityhash64("orlp-cityhash64-D-:K5yx*zkgaaaaa") == 1337
murmurhash2("orlp-murmurhash64-bkiaaa&JInaNcZ") == 1337
murmurhash3("orlp-murmurhash3_x86_32-haaaPa*+") == 1337
farmhash64("orlp-farmhash64-/v^CqdPvziuheaaa") == 1337I will also show how to create very specific pairs of strings that can be concatenated arbitrarily so that when concatenating k strings, any of the 2k combinations will have the same hash regardless of the seed used for the hash function:
a = "xx0rlpx!xxsXъВ"
b = "xxsXъВxx0rlpx!"
murmurhash2(a + a, seed) == murmurhash2(a + b, seed)
murmurhash2(a + a, seed) == murmurhash2(b + a, seed)
murmurhash2(a + a, seed) == murmurhash2(b + b, seed)
a = "!&orlpՓ"
b = "yǏglp$X"
murmurhash3(a + a, seed) == murmurhash3(a + b, seed)
murmurhash3(a + a, seed) == murmurhash3(b + a, seed)
murmurhash3(a + a, seed) == murmurhash3(b + b, seed)Basics of Hash Function Security
Hash functions play a critical role in computer security. They are used not only for verifying messages over secure channels but also for identifying updates from trusted sources and known viruses. Virtually any signature scheme starts with a hash function.
If a hash function does not behave randomly, we can break the security constructions described above. Therefore, in cryptographic hash functions, the aspect of randomness is taken very seriously. An ideal hash function should choose its result completely randomly for each input, remembering this choice for future calls. This is called a random oracle.
The problem is that a random oracle requires a true random number generator and, more problematically, an infinite memory bank accessible from anywhere in the world. Therefore, we approximate it using deterministic hash functions. They compute their outputs by essentially "shuffling" their inputs very well so that they cannot be reversed.
To measure how well a particular function approximates a random oracle, cryptographers have devised various properties that a random oracle should have. Here are the three most important and well-known properties that a secure cryptographic hash function should satisfy:
Resistance to finding the first preimage. For a constant c, it should be difficult to find such input data m that h(m)=c.
Resistance to finding the second preimage. For input data m1, it should be difficult to find other input data m2 such that h(m1)=h(m2).
Collision resistance. It should be difficult to find such input data m1,m2 such that h(m1)=h(m2).
It is worth noting that collision resistance implies resistance to finding the second preimage, which in turn implies resistance to finding the first preimage. Conversely, an attack on finding the first preimage breaks all three properties.
In general, we consider one of these properties broken if there is a way to create a collision or preimage faster than brute-forcing random input data (also known as a brute force attack). However, there are degrees of breakability, as some methods are only several orders of magnitude faster than brute force. This may seem serious, but even if a method requires 2110 steps instead of 2128, both methods are still infeasible on modern computer power.
Previously, a common hash function was MD5, and SHA-1 is still actively used today. Although both were once considered cryptographically secure, today generating MD5 collisions on a modern computer takes less than a second. In 2017, a team of researchers from CWI and Google announced the discovery of the first SHA-1 collision. However, as far as I know, neither MD5 nor SHA-1 have practical attacks for finding the first and second preimage, only theoretical ones.
Non-cryptographic hash functions
Cryptographically secure hash functions usually have a small problem: they are slow. Modern hash functions like BLAKE3 partially solve it by actively vectorizing the hash using SIMD instructions and parallelizing it across multiple threads, but to achieve such speeds they still require large amounts of input data.
One of the use cases for hash functions is generating a secret key based on a password: key derivation function. Unlike regular hash functions, here low speed actually becomes a security measure to protect against password guessing. Modern functions like Argon2 also intentionally use a lot of memory to protect against specialized hardware, such as ASIC or FPGA.
For many tasks, the use of secure hash functions is not necessary, and people often prefer increased hashing speed, especially when many small hashes need to be computed, for example, in a hash table. Let's find out what popular hash function implementations use as a hash for strings:
C++: существует множество реализаций стандартной библиотеки; в 64-битном
clang13.0.0 на Apple M1 применяетсяCityHash64. В настоящее время вlibstdc++применяетсяMurmurHash64A— разновидность Murmur2 для 64-битных платформ.Java: OpenJDK использует невероятно простой хэш-алгоритм, который, по сути, просто вычисляет
h = 31 * h + cдля каждого символаc.PHP: движок Zend, по сути, использует тот же алгоритм, что и Java, но с беззнаковыми integer и
33в качестве множителя.Nim: раньше он использовал
MurmurHash3_x86_32. Похоже, на момент написания статьи по умолчанию применяется farmhash.Zig: по умолчанию использует
wyhashс0в качестве seed.Javascript: в V8 используется специализированный слабый строковый хэш со случайно инициализируемым seed.
Есть и другие проекты, в которых по умолчанию применяются более сильные хэши:
If hardware acceleration is available on x86-64, Go uses a hash based on AES. Although it is created in a specialized way and probably does not have full cryptographic security, it would take too much effort and probably knowledge that I do not have to break it.
If acceleration is not available, an algorithm inspired by wyhash is used.
In Python and Rust, SipHash is used by default — a cryptographically secure pseudorandom function. Essentially, it is a hash function in which a secret key can be used during hashing, unlike hashes like SHA-2, where everyone knows all the information used.
This last concept is actually very important, at least for protection against HashDoS in hash tables. Even if the hash function is completely secure for all its outputs, hash tables further reduce the size of the data to just a few bits to find the desired information. For a static hash function with no randomness, it is possible to create large lists of hashes leading to collisions after reduction by simple brute force. But for non-cryptographic hashes, as we have seen, brute force is often not required and collisions can be generated at high speed for all outputs if they are not randomized by a random seed.
Interlude: Inverting Operations
Before we start breaking some of the hash functions mentioned above, I need to explain a basic technique that I will often use: inverting operations. We first encountered it in elementary school, where we were given problems like 2+x=10. This is how we learned that subtraction is the inverse operation of addition, meaning we can find x by calculating 10−2=8.
Most operations with integer registers are also reversible, despite the fact that in the case of overflow, integers are divided with a remainder by 2w. Let's consider a few operations:
Addition can be reversed using subtraction. That is,
x += ycan be reversed usingx -= y. Everything is quite obvious.Multiplication by a constant c is not reversible by division. It will not work in case of overflow. Instead, we calculate the modular inverse for c. This is an integer c−1 such that c⋅c−1≡1(modm). Thus, multiplication by c can be reversed by simply multiplying by c−1.
This constant exists if and only if c is coprime with the divisor m; for us, this means that c must be odd, since m=2n. For example, multiplication by 2 is irreversible because it is equivalent to a left bit shift by one position, permanently losing the most significant bit.
Without going into too much detail, here is a Python code that calculates the modular inverse for an integer using the extended Euclidean algorithm, which calculates such x,y that

Then since c is coprime, we find gcd(c,m)=1 (gcd is the greatest common divisor), and this means that
that is, x=c−1.
def egcd(a, b): if a == 0: return (b, 0, 1) g, y, x = egcd(b % a, a) return (g, x - (b // a) * y, y) def modinv(c, m): g, x, y = egcd(c, m) assert g == 1, "c, m must be coprime" return x % mUsing this code, we can reverse multiplication by modulus:
>>> modinv(17, 2**32) 4042322161 >>> 42 * 17 * 4042322161 % 2**32 42Magic!
XOR can be reversed using ... XOR. It is a self-inverse operation. That is,
x ^= ycan be reversed usingx ^= y.Bit shifts cannot be reversed, but two operations often used in hash functions involving bit shifts can be reversed. The first is cyclic shift (bit rotation) by a constant. It is best explained visually, for example, a cyclic shift of an 8-bit word to the left by three positions, where each bit is denoted by a letter:
abcdefghi defghiabcThe formula for a cyclic shift to the right by
kpositions is(x >> k) | (x << (w - k)), wherewis the width of the integer type. The inverse operation is a cyclic shift to the left, which simply reverses the direction of both shifts. Alternatively, the inverse for a cyclic shift to the right bykpositions is another cyclic shift to the right byw-kpositions.Another operation often used in hash functions is xorshift. This is an operation of one of two types, where k>0:
x ^= x << k // Left xorshift. x ^= x >> k // Right xorshift.Their reversal method is completely analogous, so I will consider the left xorshift.
It is important to note here that the lower k bits are not affected by xorshift at all. Thus, by repeating the operation, we will restore the lower 2k bits, as XOR will reverse itself for the next k bits. Let's look at the resulting value to understand how to proceed further:
v0 = (x << k) ^ x // Apply the first inversion step v1 = v0 ^ (v0 << k). v1 = (x << 2*k) ^ (x << k) ^ (x << k) ^ x // Simplify using self-inversion (x << k) ^ (x << k) = 0. v1 = (x << 2*k) ^ xFrom this, we can derive the following equality:
Armed with this knowledge, we can start attacking.
Breaking CityHash64
Let's take a look at the source code of
CityHash64(part of it) fromlibcxx, which is used for hashing strings on 64-bit platforms:The C++ standard library code undergoes a process of "uglification", adding underscores before all identifiers. This is because such identifiers are reserved by the standard for use in the standard library, and therefore will not be replaced by macros from standard-compliant code. For the sake of your sanity, I have removed them from the code.
static const uint64_t mul = 0x9ddfea08eb382d69ULL; static const uint64_t k0 = 0xc3a5c85c97cb3127ULL; static const uint64_t k1 = 0xb492b66fbe98f273ULL; static const uint64_t k2 = 0x9ae16a3b2f90404fULL; static const uint64_t k3 = 0xc949d7c7509e6557ULL; templateT loadword(const void* p) { T r; std::memcpy(&r, p, sizeof(r)); return r; } uint64_t rotate(uint64_t val, int shift) { if (shift == 0) return val; return (val >> shift) | (val << (64 - shift)); } uint64_t hash_len_16(uint64_t u, uint64_t v) { uint64_t x = u ^ v; x *= mul; x ^= x >> 47; uint64_t y = v ^ x; y *= mul; y ^= y >> 47; y *= mul; return y; } uint64_t hash_len_17_to_32(const char *s, uint64_t len) { const uint64_t a = loadword (s) * k1; const uint64_t b = loadword (s + 8); const uint64_t c = loadword (s + len - 8) * k2; const uint64_t d = loadword (s + len - 16) * k0; return hash_len_16( rotate(a - b, 43) + rotate(c, 30) + d, a + rotate(b ^ k3, 20) - c + len ); } To break this code, let's assume that we always pass input data of length 32. Then the implementation will always call
hash_len_17_to_32, and we will have full control overa,b,c, anddby changing the input data.Note that
dis used only once, in the last expression, so it becomes the main target for the hash attack. We will choosea,b, andcarbitrarily, and then solve the equation for the variabledto compute the desired hash.Using the
modinvfunction shown above, we first compute the necessary modular inverses formulandk0:>>> 0x9ddfea08eb382d69 * 0xdc56e6f5090b32d9 % 2**64 1 >>> 0xc3a5c85c97cb3127 * 0x81bc9c5aa9c72e97 % 2**64 1Also note that in this case xorshift is easily reversible, since
x ^= x >> 47is simply the inverse of itself. Having prepared all the components, we can reverse the function step by step.First, we load
a,b, andcas in the hash function, and computeuint64_t v = a + rotate(b ^ k3, 20) - c + len;that is, the second parameter of
hash_len_16. Then, starting from our desired return valuehash_len_16(u, v), we move backwards step by step, reversing each operation to find the function argumentuthat will give us the targethash. When we find such a uniqueu, we will compute the required inputd. Putting it all together:static const uint64_t mul_inv = 0xdc56e6f5090b32d9ULL; static const uint64_t k0_inv = 0x81bc9c5aa9c72e97ULL; void cityhash64_preimage32(uint64_t hash, char *s) { const uint64_t len = 32; const uint64_t a = loadword(s) * k1; const uint64_t b = loadword (s + 8); const uint64_t c = loadword (s + len - 8) * k2; uint64_t v = a + rotate(b ^ k3, 20) - c + len; // Reverse hash_len_16(u, v). The original operation, inverted // at each step, is shown on the right; note that this is the // reverse order of hash_len_16. uint64_t y = hash; // return y; y *= mul_inv; // y *= mul; y ^= y >> 47; // y ^= y >> 47; y *= mul_inv; // y *= mul; uint64_t x = y ^ v; // uint64_t y = v ^ x; x ^= x >> 47; // x ^= x >> 47; x *= mul_inv; // x *= mul; uint64_t u = x ^ v; // uint64_t x = u ^ v; // Find loadword (s + len - 16). uint64_t d = u - rotate(a - b, 43) - rotate(c, 30); d *= k0_inv; std::memcpy(s + len - 16, &d, sizeof(d)); } The probability that a random
uint64_tforms 8 printable ASCII bytes is (94/256)8 ≈ 0.033. Not great, butcityhash64_preimage32is so fast that needing to repeat it about three thousand times to get an all-ASCII result isn't too bad.For example, all of the following 10 strings hash to
1337when using CityHash64, generated using this code:I noticed that in real use there are variants of CityHash64 with slight differences. I decided to attack the variant included in
libc++, so this should work, for example, for itsstd::hash. Also in the article we will consider a little-endian machine, on a big-endian machine depending on the cache implementation the situation may be different.orlp-cityhash64-D-:K5yx*zkgaaaaa orlp-cityhash64-TXb7;1j&btkaaaaa orlp-cityhash64-+/LM$0 ;msnaaaaa orlp-cityhash64-u'f&>I'~mtnaaaaa orlp-cityhash64-pEEv.LyGcnpaaaaa orlp-cityhash64-v~~bm@,Vahtaaaaa orlp-cityhash64-RxHr_&~{miuaaaaa orlp-cityhash64-is_$34#>uavaaaaa orlp-cityhash64-$*~l\{S!zoyaaaaa orlp-cityhash64-W@^5|3^:gtcbaaaaBreaking MurmurHash2
After attacking
libc++we can't pass bylibstdc++, can we? The default string hash calls the MurmurHash2 implementation with seed0xc70f6907. The hash, simplified to process strings with lengths that are multiples of 8, looks like this:uint64_t murmurhash64a(const char* s, size_t len, uint64_t seed) { const uint64_t mul = 0xc6a4a7935bd1e995ULL; uint64_t hash = seed ^ (len * mul); for (const char* p = s; p != s + len; p += 8) { uint64_t data = loadword(p); data *= mul; data ^= data >> 47; data *= mul; hash ^= data; hash *= mul; } hash ^= hash >> 47; hash *= mul; hash ^= hash >> 47; return hash; } Here we can use the same technique as before. Note that the modular inverse of
0xc6a4a7935bd1e995mod 264 is0x5f7a0ea7e59b19bd. As an example, we can choose the first 24 bytes arbitrarily and find a solution for the last 8 bytes:void murmurhash64a_preimage32(uint64_t hash, char* s, uint64_t seed) { const uint64_t mul = 0xc6a4a7935bd1e995ULL; const uint64_t mulinv = 0x5f7a0ea7e59b19bdULL; // Calculate the hash state for the first 24 bytes in the usual way. uint64_t state = seed ^ (32 * mul); for (const char* p = s; p != s + 24; p += 8) { uint64_t data = loadword(p); data *= mul; data ^= data >> 47; data *= mul; state ^= data; state *= mul; } // Reverse the transformation of the target hash. // return hash; hash ^= hash >> 47; // hash ^= hash >> 47; hash *= mulinv; // hash *= mul; hash ^= hash >> 47; // hash ^= hash >> 47; // Reverse the last iteration for the last 8 bytes. hash *= mulinv; // hash *= mul; uint64_t data = state ^ hash; // hash = hash ^ data; data *= mulinv; // data *= mul; data ^= data >> 47; // data ^= data >> 47; data *= mulinv; // data *= mul; std::memcpy(s + 24, &data, 8); // data = loadword (s); } All ten lines shown below hash in this code using MurmurHash64A with the standard seed
0xc70f6907to1337:orlp-murmurhash64-bhbaaat;SXtgVa orlp-murmurhash64-bkiaaa&JInaNcZ orlp-murmurhash64-ewmaaa(%J+jw>j orlp-murmurhash64-vxpaaag"93\Yj5 orlp-murmurhash64-ehuaaafa`Wp`/| orlp-murmurhash64-yizaaa1x.zQF6r orlp-murmurhash64-lpzaaaZphp&c F orlp-murmurhash64-wsjbaa771rz{z< orlp-murmurhash64-rnkbaazy4X]p>B orlp-murmurhash64-aqnbaaZ~OzP_TpUniversal Collision Attack on MurmurHash64A
In fact, MurmurHash64A is so weak that Jean-Philippe Aumasson, Daniel Bernstein, and Martin Boslet published an attack that creates sets of strings leading to collisions regardless of the random seed used.
As for CityHash64, they also found universal collisions regardless of the seed used. In fact, CityHash64 is much easier to break in this way, as the simple preimage attack presented above, targeting
0as the hash, makes the output completely dependent on the seed, thus creating a universal collision.To understand how this works, let's look at the main loop of MurmurHash64A:
uint64_t data = loadword(p); data *= mul; // Trivially reversible. data ^= data >> 47; // Trivially reversible. data *= mul; // Trivially reversible. state ^= data; state *= mul; We know that we can trivially reverse the operations performed on
dataregardless of the current state, so we could have the following body:state ^= data; state *= mul;Now the hash indeed starts to look quite weak. The authors of the study used a clever trick: they created two strings simultaneously so that they differed by exactly the most significant bit in each 8-byte word. Why the most significant bit?
>>> 1 << 63 9223372036854775808 >>> (1 << 63) * mul % 2**64 9223372036854775808Since
mulis odd, the least significant bit is set. Multiplying1 << 63by it is equivalent to shifting this bit 63 positions to the left, which will again be equal to1 << 63. That is,1 << 63is a fixed point for the operationstate *= mul. It is also worth noting that XOR of the most significant bit is equivalent to addition, since overflow from addition is removed mod 264.So if we have two input strings, one starting with 8-byte
data, and the other starting withdata ^ (1 << 63) == data + (1 << 63)(after performing trivial inversions), we will find that the two states, regardless of the seed, differ by exactly the most significant bit afterstate ^= data. After multiplication, we will find that the two states have the formx * muland(x + (1 << 63)) * mul == x * mul + (1 << 63)... that is, they again differ by exactly the upper bit! Now we return for the next 8 bytes tostate ^= datain our iteration. We can use this moment to cancel the difference in the most significant bit by again passing two 8-byte strings that differ by the most significant bit (after inversion).In fact, we only need to find one pair of such strings that differ by the most significant bit, which we can then repeat twice (in any order) to cancel the difference again. If the data is represented as
uint64_t, then when we choose the first string asx, we can get the second string asx *= mul; // Forward transformation... x ^= x >> 47; // ... x *= mul; // ... x ^= 1 << 63; // Difference in the most significant bit. x *= mulinv; // Backward transformation... x ^= x >> 47; // ... x *= mulinv; // ...I couldn't find a printable ASCII string that would have another printable ASCII string as a pair. But I found the following pair of 8-byte UTF-8 strings, differing by exactly the upper bit after the Murmurhash64A input transformation:
xx0rlpx! xxsXъВBy combining them, we get two 16-byte strings that, when processed by the hashing algorithm, allow us to manipulate the state in a similar way: creating a collision.
xx0rlpx!xxsXъВ xxsXъВxx0rlpx!But it doesn't end there. By concatenating these two strings, we can create 2n different strings with collisions, each of which is 16n long. With the current implementation of
libstdc++, the code shown below will output the same number eight times:std::hashEven if
libstdc++randomized the seed used by MurmurHash64a, string collisions would still occur.Breaking MurmurHash3
Nim
usesused to useMurmurHash3_x86_32, so let's try to break it.While I was procrastinating finishing this article, Nim switched to using farmhash. Pretend it still uses MurmurHash3 so my words make sense. Then I'll break farmhash too.
If we simplify again and only consider strings whose length is a multiple of 4, we get the following code:
uint32_t rotl32(uint32_t x, int r) { return (x << r) | (x >> (32 - r)); } uint32_t murmurhash3_x86_32(const char* s, int len, uint32_t seed) { const uint32_t c1 = 0xcc9e2d51; const uint32_t c2 = 0x1b873593; const uint32_t c3 = 0x85ebca6b; const uint32_t c4 = 0xc2b2ae35; uint32_t h = seed; for (const char* p = s; p != s + len; p += 4) { uint32_t k = loadword(p); k *= c1; k = rotl32(k, 15); k *= c2; h ^= k; h = rotl32(h, 13); h = h * 5 + 0xe6546b64; } h ^= len; h ^= h >> 16; h *= c3; h ^= h >> 13; h *= c4; h ^= h >> 16; return h; } I think you should now understand how to make this function return any values if you know the seed. The inverse of
rotl32(x, r)will berotl32(x, 32-r), and the inverse ofh ^= h >> 16will again be simplyh ^= h >> 16. Only withh ^= h >> 13the situation is a little different: we see here for the first time that the inversion of xorshift requires more than one step:h ^= h >> 13 h ^= h >> 26Let's calculate the modular inverse numbers for the values from
c1toc4, as well as5mod 232. If you want to cheat or check your answer, you can look at the code I used to generate the following ten lines, which when passed toMurmurHash3_x86_32with seed0all hash to 1337:orlp-murmurhash3_x86_32-haaaPa*+ orlp-murmurhash3_x86_32-saaaUW&< orlp-murmurhash3_x86_32-ubaa/!/" orlp-murmurhash3_x86_32-weaare orlp-murmurhash3_x86_32-chaa5@/} orlp-murmurhash3_x86_32-claaM[,5 orlp-murmurhash3_x86_32-fraaIx`N orlp-murmurhash3_x86_32-iwaara
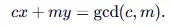
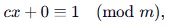
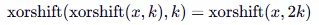







Write comment