
- AI
- A
Homo clickus. How modeling clicking people will be useful for image segmentation
Greetings to all readers!
Recently, our group received pleasant news: our paper describing a model of how people click and tap on images was accepted at the upcoming NeurIPS! It will be useful for testing interactive segmentation models that help automate and speed up the process of human image annotation.
Below, I would like to tell you more about our development.
From Magic Wand to Transformers
Do you remember the moment when Photoshop first appeared on our computers? Among its many tools, there was one truly "magical" function — the "magic wand". With a single mouse click, you could select an entire object or background, which seemed like a real miracle compared to tedious manual selection.
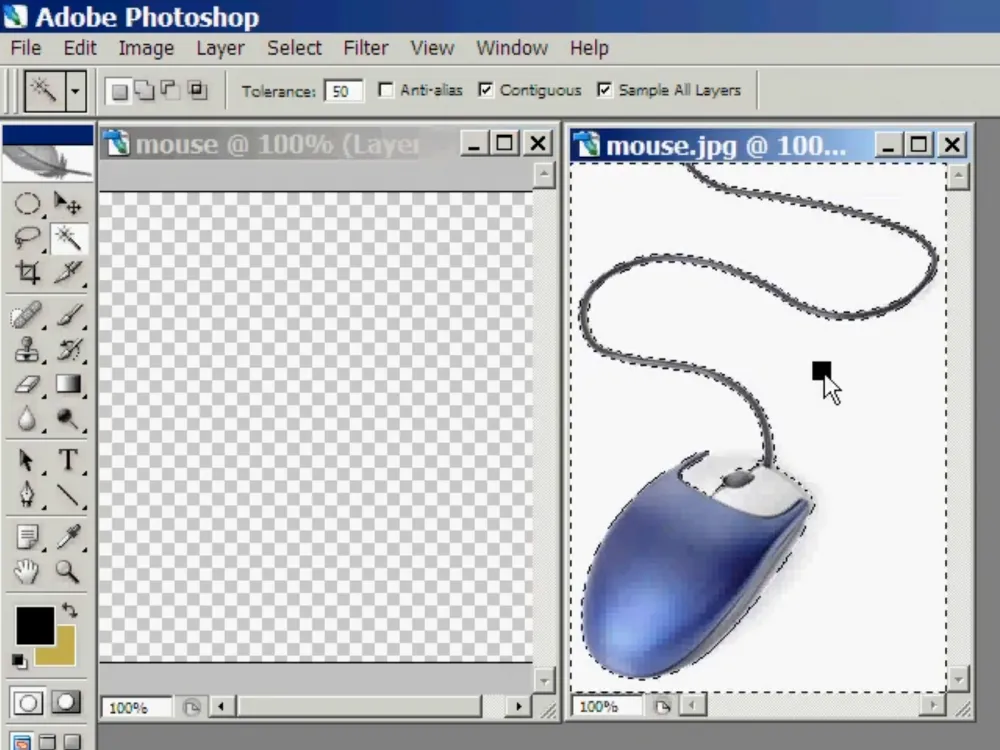
The principle of this tool was simple: the program found pixels similar in color and tone next to the click location and combined them into a shape. This significantly sped up the work, although the result was not always perfect, especially on complex images.
Today, this technology has evolved into what we call interactive segmentation — selecting objects in photos or videos with minimal human involvement. Imagine a smart assistant that only needs a couple of clicks to understand which object you want to select. It analyzes not only color but also shape, texture, context — everything that helps accurately determine the boundaries of the object.
Nowadays, various types of architectures are used to solve this problem, such as convolutional networks or transformers. But how well do modern algorithms understand the real intentions of users? This is the question we answer in our research.
Make SAM
In 2023, Meta [recognized as an extremist organization, activity is prohibited in Russia] introduced a revolutionary method called Segment Anything Model (SAM), which took interactive segmentation to a new level. SAM and similar systems are now used everywhere: from processing medical images to creating special effects in videos.

However, developers of such systems face a serious problem. To improve algorithms and test them correctly, it is necessary to understand how real people interact with them. And it's not that simple.
For example, when a user clicks on a person, the algorithm makes a slight mistake and does not capture the head with the hand. At this point, the user has to make a second click. It was previously assumed that the user always clicks in the center of the largest error area, which we will call the basic strategy. The main testing procedure was based on this assumption.
But several studies have already shown that a person is not a robot - he does not mathematically calculate the ideal point for a click. His attention and actions depend on many factors: what attracts his attention, the convenience of performing the action, how he understands the task, and much more.
We conducted a large-scale study to find out how people actually interact with interactive segmentation methods when they want to select an object. By collecting a dataset of more than 475,000 real clicks from many users, we created a model that can predict the probability of a click in each part of the target or, as we say, the object of interest. This allowed us to develop a new way of testing interactive segmentation methods that much better reflects the real use of the technology by people.
Interaction with interactive segmentation systems
Before we talk about our findings, let's understand how users can interact with interactive segmentation systems in general.
There are several ways to interact in this manner. You can draw a rectangle around the object, draw a line through it, outline it, or even describe the object with words. The simplest and most intuitive way is to click with a mouse (or tap on a smartphone). This is what we focused on.
Before moving on, we need to talk about predicting saliency (or, more colloquially, salience) — the task of determining which parts of an image or video will attract the most human attention at first glance. For example, imagine a street photo with people, cars, and shop signs. By predicting saliency, we will see that a bright shop sign or a person in a red jacket will attract attention faster than a gray building wall in the background.

Data for this task is usually collected using eye trackers that record eye movements. However, conducting such experiments is a complex and costly process. Therefore, some researchers have suggested tracking mouse movements, as this simplifies scaling experiments.
But in the context of interactive segmentation, this approach is not applicable. In attention prediction tasks, observers freely view the image, whereas in our task, the user purposefully interacts with the object they want to highlight. Nevertheless, the data collection methods used in saliency prediction have influenced our research.
Dataset
Armed with this tool, we created a unique dataset of real user clicks for interactive segmentation tasks called RClicks. By combining classic datasets such as GrabCut, Berkeley, DAVIS, COCO-MVal, and TETRIS, we collected over 475,000 user clicks.
To collect the dataset, we developed a special web interface for data collection and used it in Yandex Tasks (for those who don't know, it's a crowdsourcing platform). In each task, users were shown an image and the corresponding segmentation mask, then the image was shown again and they were asked to click on the target object.
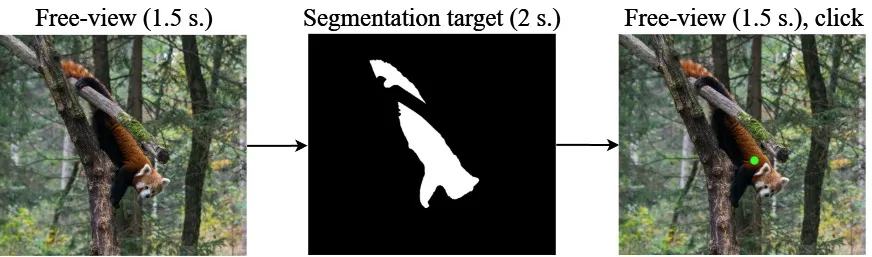
Initially, we showed a white mask on a black background to indicate the object of interest. But we quickly noticed that people were pointing to the center of this white mask and not taking into account the surrounding context and the texture of the object itself. So we realized that the interface could lead to a bias in the distribution of clicks.
Therefore, we conducted a study to choose the most natural way of interaction. We tested several task display modes:
Text Description: users were offered a text description of the target object.
Object CutOut: the object itself was shown on a gray background in its original position.
Shifted CutOut: the object was displayed on a gray background but shifted to the corner of the screen.
Silhouette Mask: a black and white mask of the object was shown in its original position.
Highlighted Instance: the object was highlighted with a colored frame on the original image.
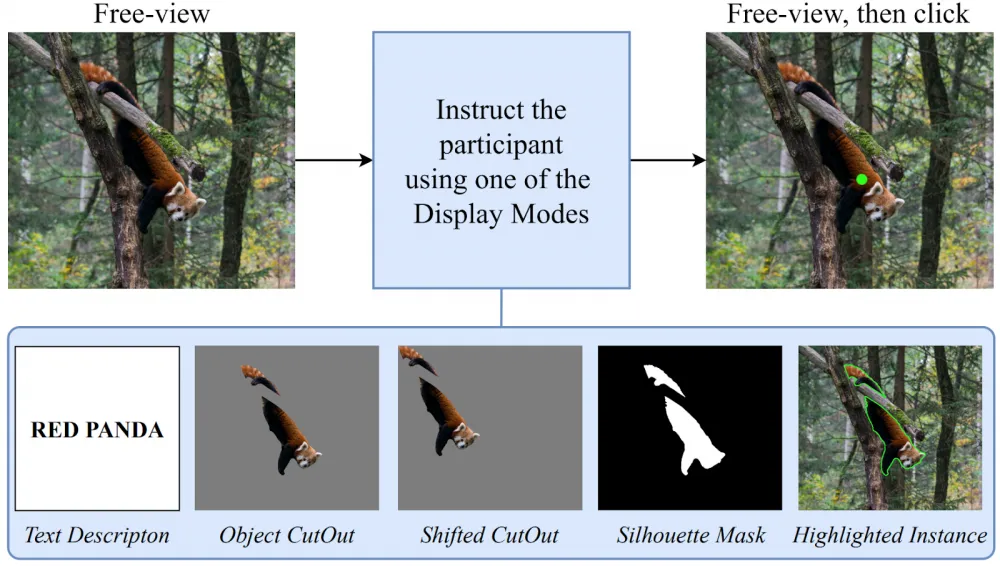
At the beginning of the study, we assumed that the least biased way of displaying an image corresponds to how people imagine in their heads what they want to highlight. The closest to this is Text Description. But we can't annotate all examples this way because on the second click it can be difficult to explain in text where it was mistakenly highlighted and where it wasn't, as well as when there are many similar objects in the image. So we decided to find the closest way to Text Description - it turned out to be Object CutOut.

Using Object CutOut, we collected user clicks on both computers and mobile devices. To increase the reliability of the data, we introduced checks: for example, only those clicks that fell within the boundaries of the object or were not further than a certain distance from its border were taken into account.
But we didn't stop there. When using interactive segmentation tools in practice, users often have to correct errors from the first round of interaction. Therefore, we simulated subsequent rounds using modern interactive segmentation methods — SAM, SimpleClick, and RITM. We applied these methods to the images and clicks from the first round, obtained masks with certain errors, and asked users to click on the areas of these errors to correct them.
As a result, we collected a large dataset that includes not only the first clicks but also their actions to correct the first click. After collecting it, we decided to create a model that would predict these clicks for us. This is needed, for example, for data that does not have collected clicks, but we really want to test interactive segmentation models on them.
Click Simulation and Clickability Model
So, having human click data, we wondered how we could simulate them. Remember, we mentioned the saliency prediction task earlier? Since it is possible to predict a human attention map from an image, we decided that it is also possible to predict where a person will click, knowing the image and the object of interest mask.
Similar to the saliency prediction task, we formulate the task of modeling user clicks as a probabilistic task. The main features of the model:
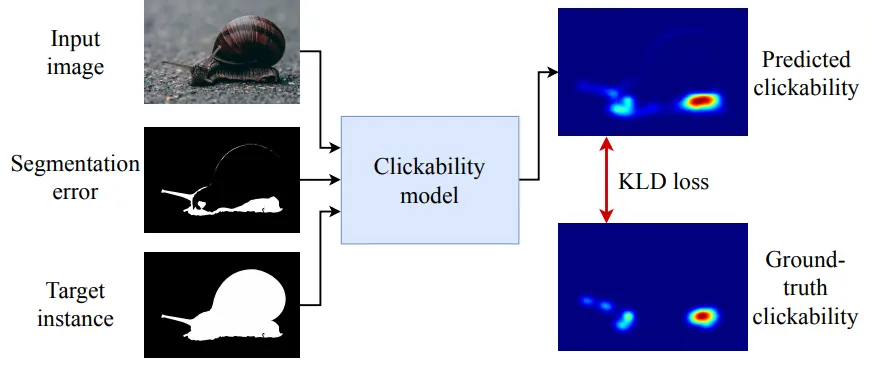
Input data: the original image, the target object mask, and the segmentation error mask (where the previous result was incorrect) are fed to the input.
Prediction: the model outputs the probability that the user will click on each specific point of the image.
Architecture: we used the modern SegNeXt architecture, which has proven itself well in segmentation tasks.
In the following figure, you can see the full architecture of our model:
Creating a Dataset for Training
We needed to determine how to properly use the collected clicks for training our model. Here, special clickability maps, which show the probability of a click at each point of the image, came in handy. The process of creating such maps includes several steps:
Map initialization: create an initial map with zero values.
Adding clicks: in places where the user clicked, increase the map value to one.
Smoothing: apply Gaussian blur to the map.
Considering the error mask: multiply the map values obtained in the previous step by the smoothed error mask to focus on areas that require correction.
Normalization: divide each map value by the sum of all values.
Thus, each clickability map reflects not only the probable click positions but also takes into account the context of segmentation errors.
Comparison with Baselines
From the very beginning, we needed models to compare our method with. We chose three methods as baselines:
Uniform distribution on the object of interest. The model assumes that the probability of a click at any point of the object is the same.
Distribution obtained using distance transform. The model is based on the assumption that users click more often closer to the center of the object.
Saliency map prediction. Since we need to condition on the object of interest somehow, we feed the model an image of the object on a gray background. The idea is that the user is more likely to click where they intuitively look first.
Next, there is an image with the visualization of all models, including ours.
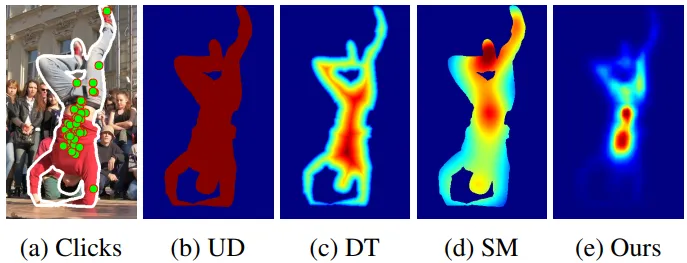
The next step was to compare the proposed baseline models with our model trained on TETRIS train (a part of TETRIS consisting of image-mask pairs) using the corresponding metrics. More about the metrics — under the cut:
Hidden text
PDE — the probability of true clicks in the clickability map and NSS from saliency benchmarks.
NSS — a metric for evaluating the quality of saliency map predictions. It measures how well the predicted saliency map matches the actual human gaze fixation points.
WD — Wasserstein distance, a metric that measures the distance between two probability distributions.
PL1 — the average pairwise L1 distance between generated clicks and real ones.
KS — the percentage of pairs where the Kolmogorov-Smirnov test hypothesis that the two groups of points are generated from the same distribution is not rejected.
Below is the comparison result on TETRIS val.:
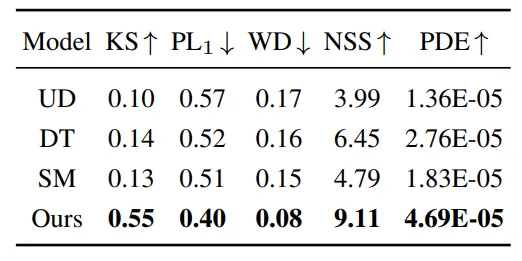
As you can see, we are beating all baselines here with a good margin.
In the figure below, you can see examples of model predictions of clicks and probability density, as well as compare them with real clicks:
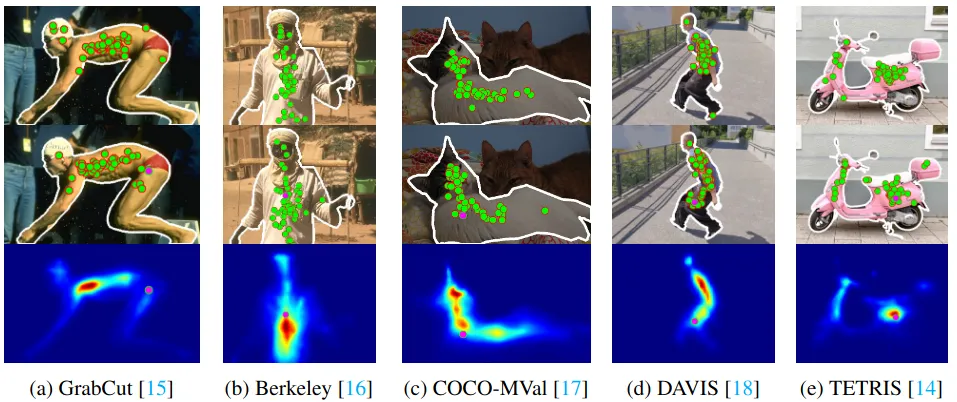
In most cases, baseline strategy clicks are close to the mode of the user distribution (see (b) and (e)), but in some cases, they can be far from the mode (e.g., (a), (d)) or not cover all modes of the distribution (e.g., (c), (e)).
Benchmark
Finally, we come to the most interesting part of our narrative: how using our clickability model can make testing interactive segmentation methods closer to how people behave in real life.
Since our model returns object probability densities, we can introduce the concept of Click Groups. To do this, we sort all our probabilities and divide them into 10 groups so that the sum of each group is equal to 10%, but the average probability in earlier groups is lower than in later ones. We interpret these groups as reflecting different user strategies and habits when choosing a point to click.
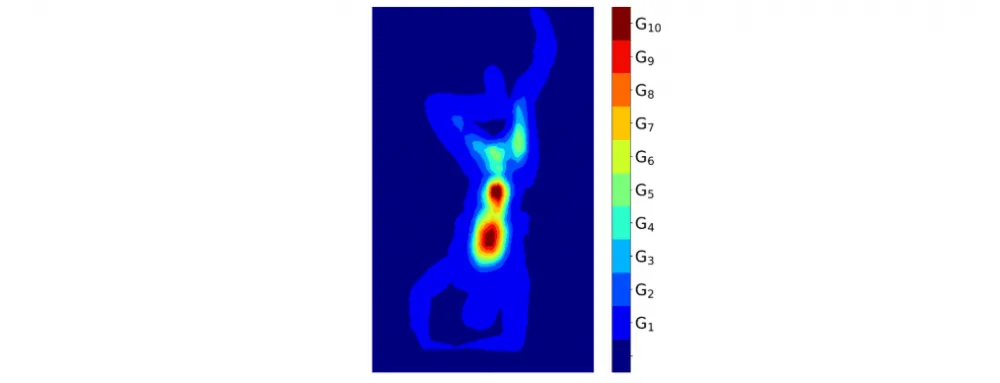
We modified the classic test protocol for interactive segmentation methods by replacing the basic click placement strategy with sampling from different groups.
One of the classic metrics for evaluating interactive segmentation methods, Number of Clicks (NoC), allows us to evaluate the time in clicks needed to reach 90% IoU.
Hidden text
Intersection over Union (IoU) or Jaccard index evaluates the intersection of the true and predicted areas, divided by their total area.
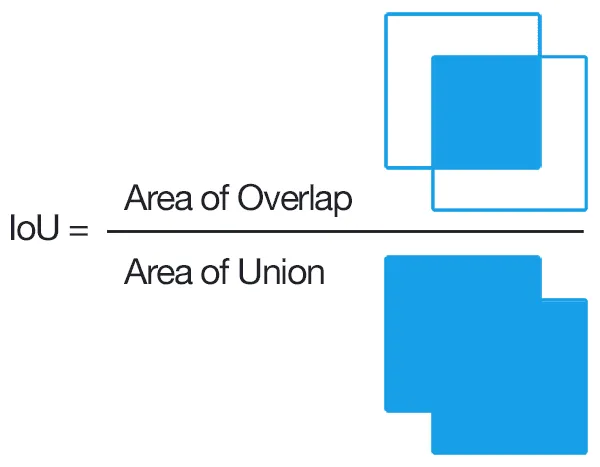
Based on it, we introduce 3 new metrics:
1) Sample NoC
We replace the basic click placement strategy with sampling from the same group for each subsequent click. Thus, for one instance, we get 10 values for each group. Then these 10 values are averaged by groups, and then by instances. This metric allows us to estimate how much time (in clicks) an average person will spend on highlighting an average object.
2) ∆SB
This metric calculates the relative increase in Sample NoC compared to NoC using the basic strategy. That is, we are interested in this metric as a metric of overfitting interactive segmentation methods to the basic click placement strategy. We want there to be no difference, or it to be minimal.
3) ∆GR
This metric calculates the relative increase in time (in clicks) to highlight an object when sampling clicks from group G1 over group G10. The essence of this metric is how much the speed of object highlighting will differ for people belonging to two different groups. Ideally, we want there to be no difference.
The standard deviation of Sample NoC, ∆SB, ∆GR can be considered robustness metrics, while the average Sample NoC can be considered an efficiency metric.
Next, we present a shortened version of the table with results. The names of the datasets used are written at the top. The first 3 columns are the method name, the method backbone, the data on which the method was trained.
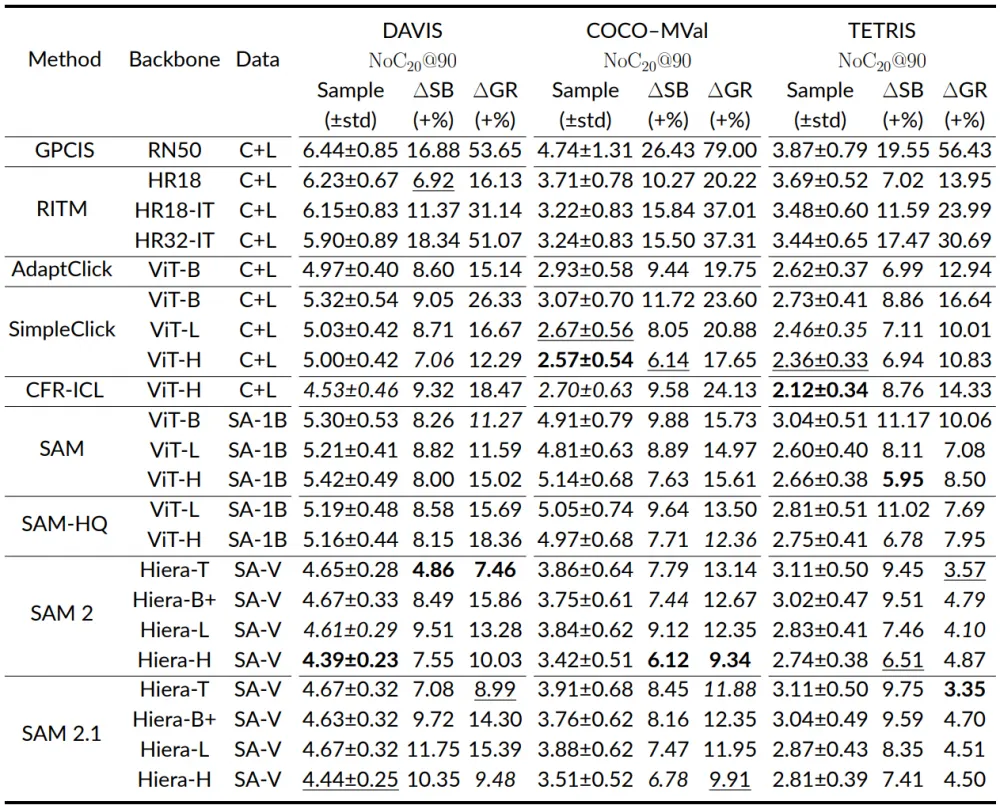
According to the values of Sample NoC and ∆GR, the best annotation time was achieved by SAM 2 Hiera‑H (on DAVIS), CFR‑ICL (on TETRIS), and SimpleClick ViT‑H (on COCO‑MVal). The latter two methods are less reliable compared to SAM-like methods, which work more stably in different click groups.
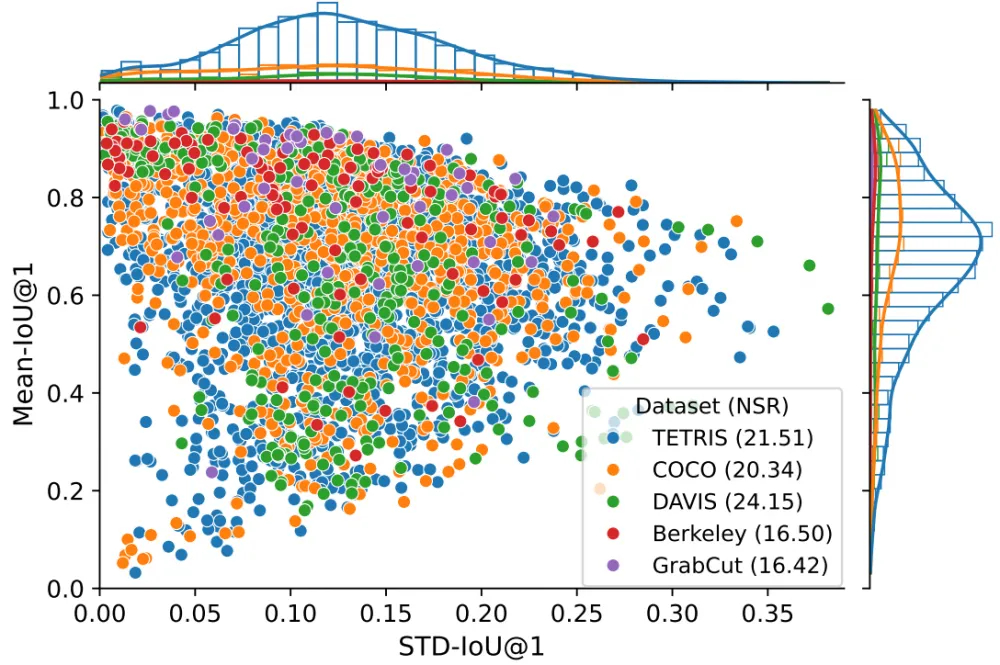
We also used the first clicks of real people to determine the complexity of annotating datasets and individual instances. To do this, we took each click, used it for inference of each interactive segmentation method we have. We measured the mean and standard deviation of IoU and calculated the Noise to Signal ratio (NSR) as the ratio of the standard deviation to the mean. The higher it is, the more unstable the methods behave on a given instance. Then we averaged the NSR across datasets: the dataset with the highest average result is the most difficult.
Below are examples of two images with high NSR. From left to right are masks averaged over clicks obtained by different methods: RITM, SimpleClick, SAM, SAM‑HQ.

Next is a scatter plot visualization. If you want to find the most difficult instances (it makes sense to look at them when you have trained a new method for analyzing difficult cases), you should choose instances from the lower right corner.
Conclusions
During the experiments, we formulated several important observations that will be useful primarily to developers of interactive segmentation methods:
According to ∆SB, the baseline strategy underestimates the actual annotation time by from 5% to 29%.
Then, according to ∆GR, the annotation time of users from different groups varies from 3% to 79%.
Currently, there is no segmentation method that is optimal in terms of both efficiency and robustness across all datasets. Therefore, developers should choose a method according to their requirements.
According to the averaged NSR, we identified the most difficult dataset for annotation — it is DAVIS with an NSR of 24.15.
How could all this be applied in practice? Firstly, during the training of interactive segmentation methods, NSR can be used to identify the most difficult examples from the training set.
In addition, our approach can be used to estimate the time (and therefore the cost) of annotating a new dataset. To do this, you can annotate a small portion of the data and then run our benchmark on this subset. This will provide a more realistic estimate of the time required to annotate the entire dataset, calculate the required number of annotators, the volume of their work, and the cost of annotation.
Finally, using the results obtained on the subset, it will be possible to choose the optimal annotation method for a specific dataset.
Impressions
In conclusion, I would like to highlight a few points that I remembered during the work.
Firstly, it was not obvious that saliency prediction models would not be suitable for simulating clicks and would be worse than our model, as it seemed that the assumption "where the gaze is attracted, there you click" was quite logical.
Secondly, it was very unexpected when it was not immediately possible to collect clicks normally, we had to think about how to correctly indicate to people the object that needs to be highlighted.
Thirdly, when we trained the model, we had to come up with how to properly use it to test interactive segmentation methods. Initially, there was no concept of click groups, we sampled from the entire distribution, and when the concept of groups appeared, we were very afraid that the Sample NoC would not converge. But they converged, which was also very pleasant, as we understood that in theory they should converge, but it was not a fact that this would be the case in practice.
Fourthly, I really liked the idea of NSR for assessing the complexity of instances and datasets itself.
And of course, it was very joyful when our article was accepted at NeurIPS 2024. I really want to see how our model will be used by developers of future segmenters!
On this note, I conclude, have a nice day everyone!
A more technically complete analysis can be read in the article itself, code and data can be found on github.
Thanks to AIRI science writer Marat Khamaev for helping to write the article, as well as my colleagues: Vlad Shakhuro, Denis Shepelev, and Andrey Moskalenko.









Write comment