- AI
- A
Speculative Inference Algorithms for LLM
In recent years, the quality of LLM models has significantly improved, quantization methods have become better, and graphics cards more powerful. Nevertheless, the quality of generation still directly depends on the size of the weights and, consequently, the computational complexity. In addition, text generation is autoregressive - token by token one at a time, so its complexity depends on the size of the context and the number of generated tokens.
Introduction
But text generation does not always have uniform complexity, just as we often think in ideas, and words are spoken "automatically". In the article, we will discuss algorithms that allow using this non-uniformity for acceleration.
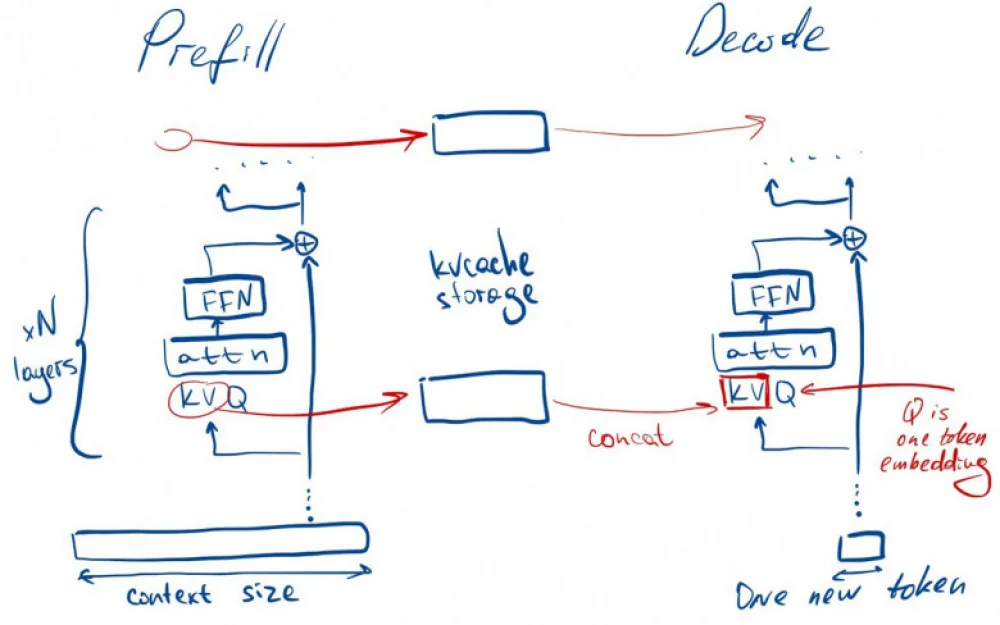
Prefill vs decode
When generating tokens, llm has two stages:
Prefill - context processing and KVCache filling
Compute-bound task (multiplication of large matrices)Decode - generation of new tokens autoregressively: generated a token, added it to the current accumulated prompt, repeated until the required number is generated
Memory-bound task (more KVCache dragging and matrix assembling than multiplying)
There are 2 problems here:
As the context size increases, working with kv-cache becomes inefficient.
Therefore, compression and offloading cache algorithms, as well as more efficient memory management, reducing fragmentation, are relevant. In this direction, it is worth reading about the vllm framework and the PagedAttention device.
I wrote about this in my telegram channel (and much more about neural network inference).As the generation size increases, a lot of forward computations of the base network occur for each new token, which is inefficient. And this leads to the idea of speculation.
Speculation idea
We have one forward for each new token in decode. At the same time, some words are understandable from the context or may not make sense in the context of a specific generation.
Can we skip or significantly simplify the calculations of some tokens?
After all, if we have a "guessed" sequence of tokens that is accepted by our model as a whole (by comparing with the probabilities at the output after the general forward), then we can reduce the number of forward iterations at the decode stage.
Next, we will ideologically consider the most well-known algorithms. Links to articles and code for further consideration under each algorithm. Keep in mind that measurements on your models and tasks may differ, both in terms of speed and "response quality" (whatever you mean by that) compared to those stated in the articles.
Speculative decoding
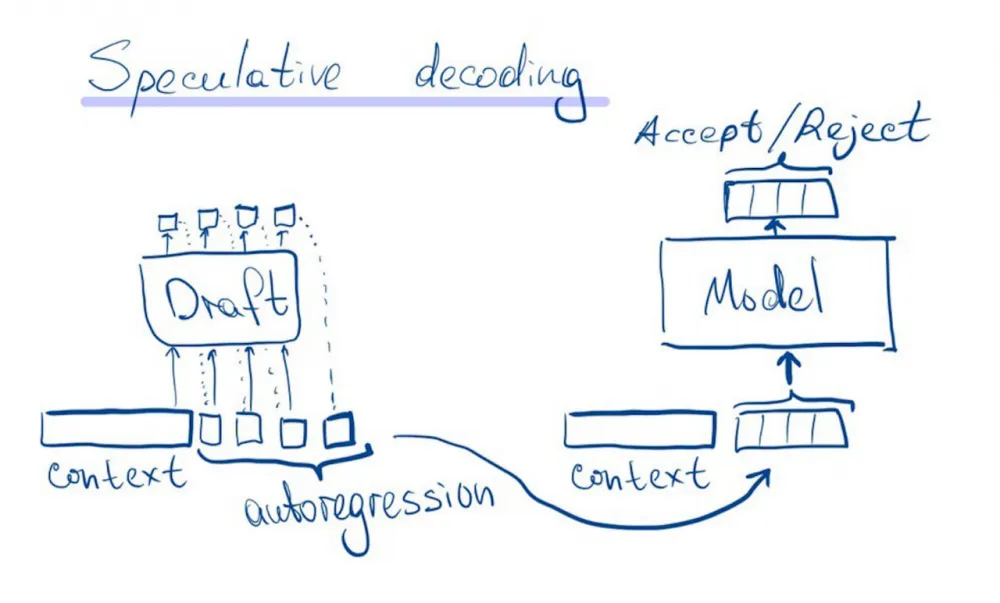
We will autoregressively generate tokens in advance using the draft model. After that, we will conduct new generated tokens in one forward. Thus, for each token, we have the probabilities q(x) for the draft model and p(x) for the same tokens from the main model.
Now, instead of sampling x ∼ p(x):
Sample x ∼ q(x)
If q(x) ≤ p(x) accept speculative token
If q(x) > p(x), then reject it with probability 1 − p(x)/q(x)
In case of rejection, sample x from the distribution norm(max(0, p(x) − q(x)))
The articles show that this method allows obtaining x ∼ p(x).
Fast Inference from Transformers via Speculative Decoding
code: https://github.com/feifeibear/LLMSpeculativeSampling
Accelerating Large Language Model Decoding with Speculative Sampling
code: https://github.com/shreyansh26/Speculative-Sampling
Lookahead decoding
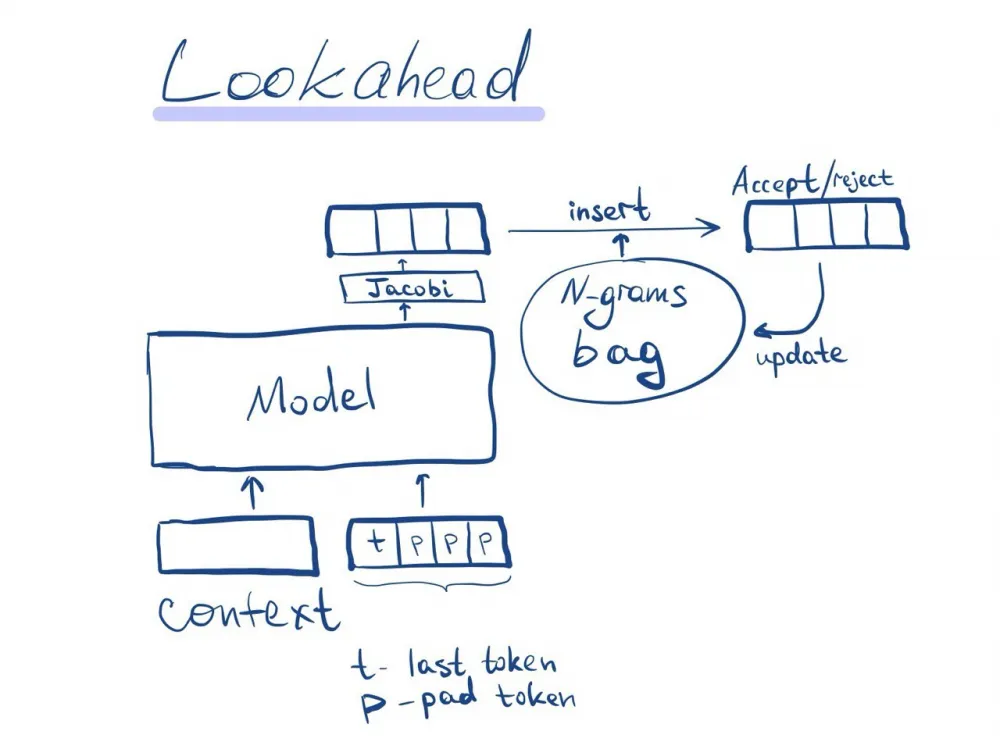
The idea is to use a simple draft model (in the articles below - a system of nonlinear equations is solved). And to increase the stability of this method - to accumulate the acceptance of a sequence of small length in a hash table and substitute them into the output of the draft model.
Moreover, it is possible to check several speculative sequences in advance if the attention matrix is made blocky on the speculative part.
This idea is proposed in the following article. Speculation is done through solving a system of nonlinear equations using the Jacobi method.
Break the Sequential Dependency of LLM Inference Using LOOKAHEAD DECODING
code: https://github.com/hao-ai-lab/LookaheadDecoding
There is an implementation in TensorRT-LLM:
https://github.com/NVIDIA/TensorRT-LLM/blob/main/examples/lookahead/README.md
You can read about the Jacobi method for parallel generation here:
Accelerating Transformer Inference for Translation via Parallel Decoding
code: https://github.com/teelinsan/parallel-decoding
Architectural substitutions (early exit and skip decode)
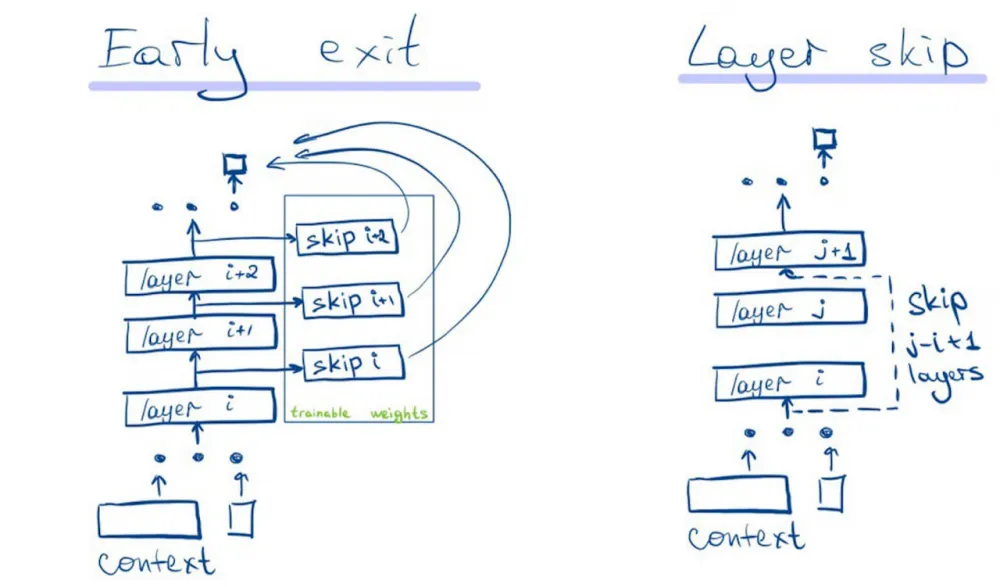
Retraining with the addition of early-exit layers or changing the training process is required. It is possible to fine-tune on pre-trained weights. Implementing this approach will not be fast and will require good competence from the team.
SkipDecode: Autoregressive Skip Decoding with Batching and Caching for Efficient LLM Inference
code: closed 😔
EE-LLM: Large-Scale Training and Inference of Early-Exit Large Language Models with 3D Parallelism
code: https://github.com/pan-x-c/EE-LLM
Multitoken prediction
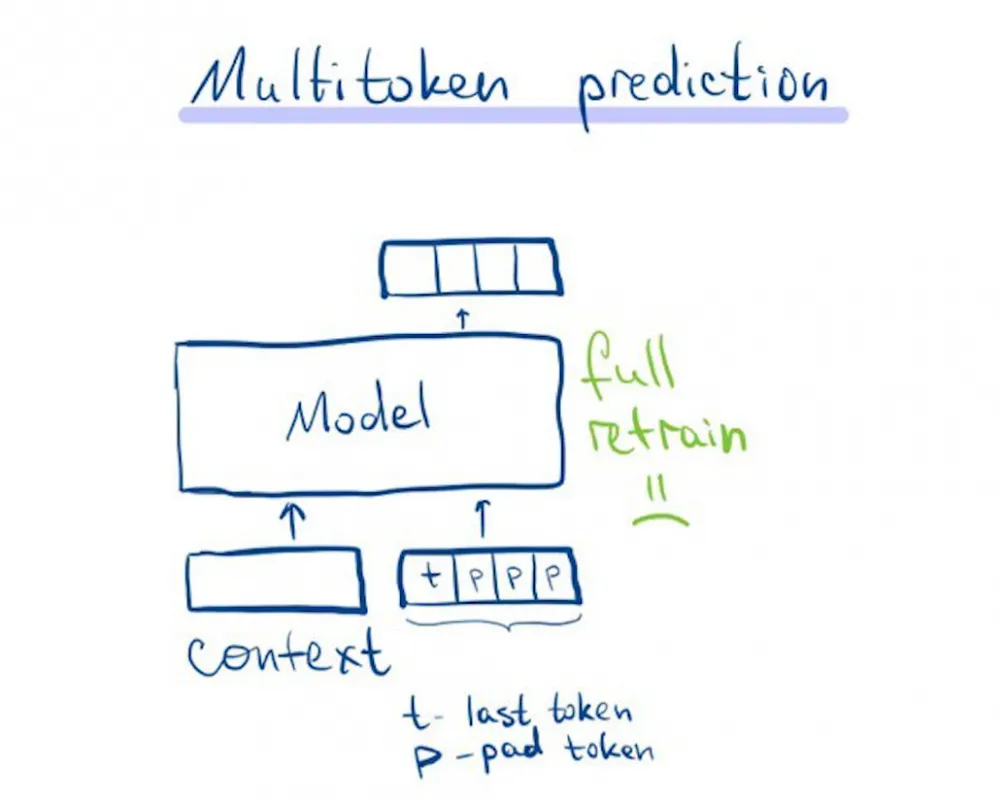
What if the model itself generates several tokens? And we will decide how many of them to accept. This approach requires retraining the entire model, which is not very pleasant.
Better & Faster Large Language Models via Multi-token Prediction
code: none 😔
But the following algorithm generalizes the idea, training only a small number of weights to predict multiple tokens.
Medusa
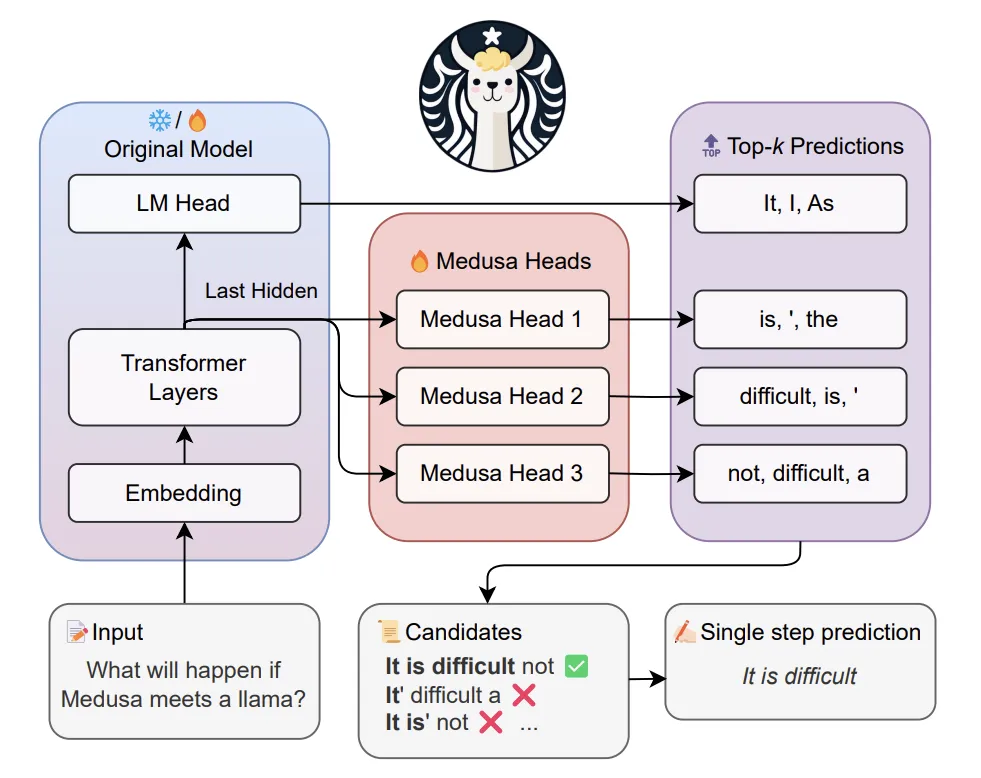
Developing the idea of generating multiple tokens, you can add several heads generating tokens ahead to the LMHead (classification head).
And fine-tune only them, which is much easier and allows you to use open pre-trained models as a basis and any framework for inference.
Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
code: https://github.com/FasterDecoding/Medusa
Eagle
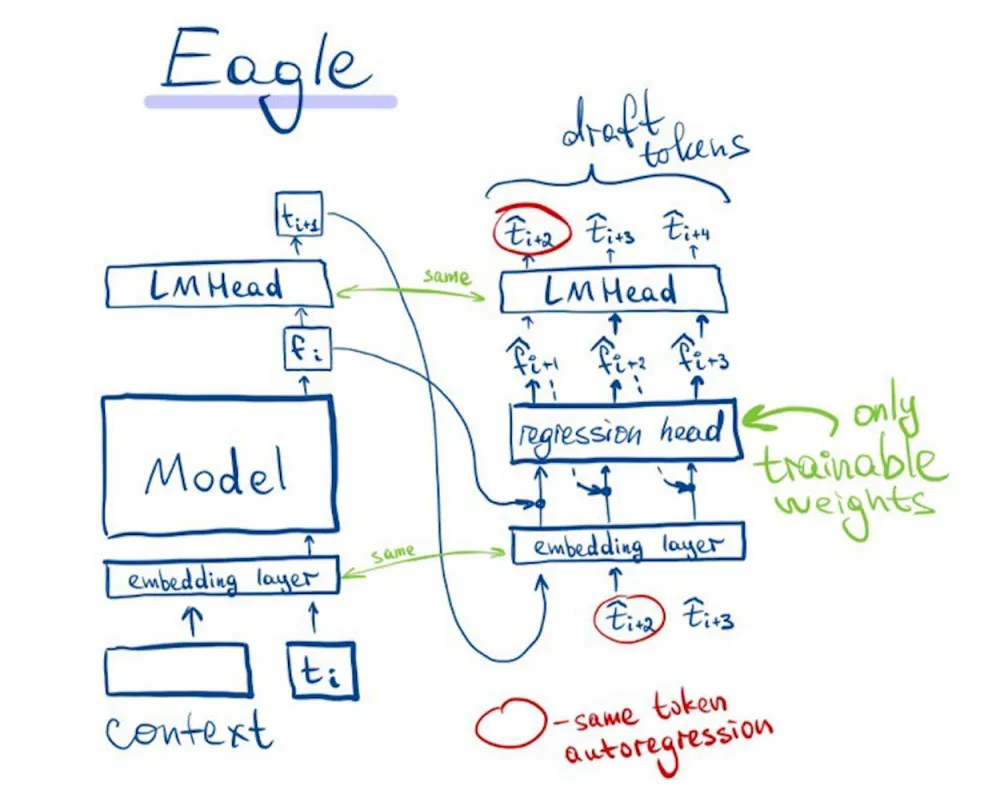
One of the newest speculative generation algorithms. Essentially, it is a neat combination of the idea of speculative decoding with a draft model, approaches with head fine-tuning, and ideas from lookahead.
It works the same way as classic speculative decoding, only the model, in addition to tokens from previous iterations, also accepts feature vectors of these tokens (output values after the model and before LMHead).
The draft model uses the LMHead and token embedding layer from the main model, training only the "body" on a mixture of classification loss and l1 (between feature vectors of the main and draft models). By manipulating the size of the body, you can achieve the optimal ratio of the draft model size and token acceptance by the main model. And the speculative sampling itself is done through tree-search (we generate 2 tokens at each iteration).
EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
code: https://github.com/SafeAILab/EAGLE
Framework support - TensorRT-LLM (https://github.com/NVIDIA/TensorRT-LLM/tree/main/examples/eagle), vLLM (https://github.com/vllm-project/vllm/pull/6830)
What to use?
It will be necessary to try the available algorithms for your tasks, based on faith in them. In addition, if replacing the inference framework is impossible, you will have to choose from what is implemented in it.
Three paths can be distinguished:
Lookahead - you have neither a draft model nor resources for retraining,
Speculative decoding - if there is a draft model and you can load its weights along with the main model. For most open neural networks, there are smaller weights, so the method is easy to use. For example, for a pretrained 70b model, you can try draft models 1b/3b/7b,
Variations of Eagle/Medusa with head training - if there are resources for retraining, availability, and competence of developers. It can be faster than speculative decoding, while the weights of the draft model will be significantly smaller. This will allow more efficient use of video card memory.









Write comment