- AI
- A
BirdCLEF+ 2025: Overview of the competition and key decisions of the top-5 teams
BirdCLEF+ 2025 is the next edition of the annual competition by the Cornell Lab of Ornithology on wildlife sound recognition. This year, participants were tasked with predicting the target animal from short audio snippets, balancing model quality and hardware constraints.
Competition Description
Here is the full post with description
Data
– Volume: 12 GB of audio recordings of birds, insects, amphibians, and reptiles.
– Sources: xeno-canto.org, iNaturalist, Colombian Sound Archive (CSA), with the first two being pure crowdsourcing, and the labeling is "dirty":
some samples have long comments from a Colombian naturalist in Spanish;
a fly enters the microphone and buzzes for 40 seconds out of a 50-second bird recording;
the bird recording cuts off with a loud "plop", followed by 90 seconds of complete silence.
Labeling
The main label — target animal species.
The secondary label — other audible species.
Coordinates, author of the recording, and source.
Quality assessment (only for xeno-canto).
Train/Test Split
– Train: full audio files.
– Test: 5-second clips.
For example, from 30-second and 20-second recordings, 10 test samples are created: the first 6 with the label of the first recording, the remaining 4 with the label of the second.
Metric
Macro-ROC-AUC: sorting probabilities within each class and averaging without considering frequency.
Hardware Restrictions
90 minutes CPU-only.
Trend: in 2022 and 2021 — 9 hours CPU/GPU, in 2023–2024 — 120 minutes CPU, and in 2025 — 90 minutes.
5th place: "secret technique" of manual processing
Built on manual preprocessing
This is the "secret technique" that everyone is too lazy to do. The data is useful to sift through/listen to manually.
Silero for detecting human voice fragments: then manually cut out all the "human" sections.
For classes with low frequency (<30 samples), we listened to all recordings and removed "silence" and noise.
For the train, we took the first 30 seconds of the recording (for rare classes, 60 seconds), and where there were fewer than 20 samples, we upsampled to "fill out" the training.
Models: a stack of EfficientNets (4 × v2_s, 3 × v2_b3, 4 × b3_ns, 2 × b0_ns).
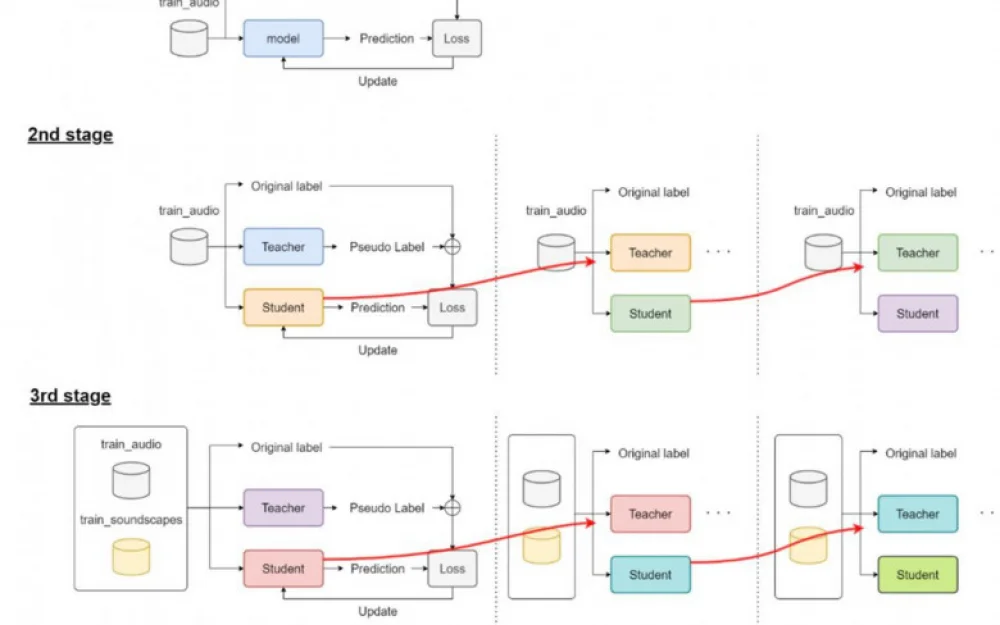
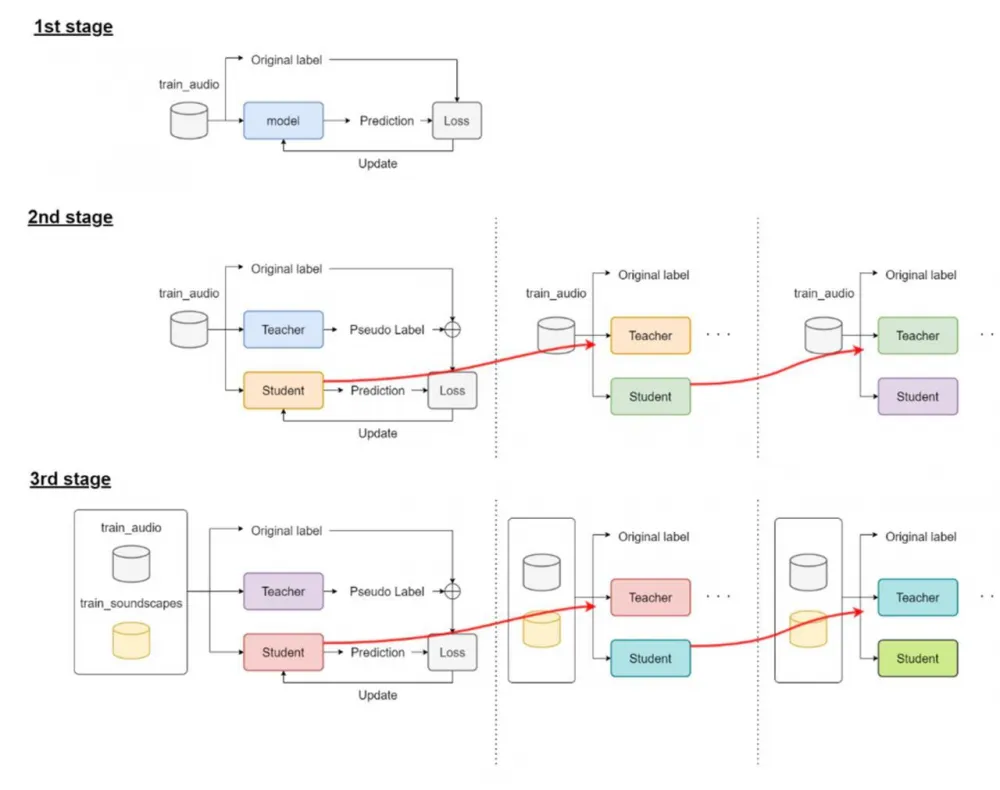
Three-stage training (FocalLoss, Adam, Cosine Annealing + warmup):
Only main data and main target.
Pseudolabels and two-stage self-distillation.
All data: 50% labeled (main labels + pseudolabels), 50% unlabeled (only pseudolabels), plus two iterations of self-distillation.
4th place: when simplicity wins
Sometimes simplicity wins. Since we are evaluated on AUC at BirdCLEF, it makes sense to optimize it directly.
SoftAUCLoss — implemented class SoftAUCLoss(nn.Module), which computes pairwise differences and log-loss, resistant to overfitting, but supporting soft labels.
Semi-supervised learning: first, 10 models were trained on the labeled portion, generated pseudo-labels for the unlabeled part, then trained a new round on the combined dataset.
Abandoned self-distillation and complex schemes—"it didn't work."
3rd place: Spectrogram, Model Soup, and Augmentations
Data: supplemented 2025 with 80% of 2023 data and added 112 new classes (20% kept for validation). Pseudo-labeled the unlabeled part.
Models: "zoo" with two types of spectrograms (tf_efficientnet_b0_ns, v2_b3, v2_s.in21k, mnasnet_100, spnasnet_100).
Techniques:
Sampled random segments instead of the correct 5-second slice.
Added human voice for augmentation.
FocalLoss and Model Soup (averaging checkpoint weights for stability without heavy ensembles).
Post-processing with power adjustment: boosted the top n confident predictions, lowering others.
2nd place: Xeno Bug and Proven Recipes
Past competition experience plays a significant role, especially if you remember interesting bugs.
Data: previous competitions + Xeno Archive bug (maximum of 500 samples per class).
Preprocessing: first 7 seconds of the file, randomly cut out 5 seconds.
Architectures: tf_efficientnetv2_s + RAdam, eca_nfnet_l0 + AdamW, 50 epochs, Focal+BCE, Cosine LR.
Sample_weights to compensate for imbalance:
pythonCopyEditsample_weights = ( all_primary_labels.value_counts() / all_primary_labels.value_counts().sum() ) ** (-0.5)CopyEdit
sample_weights = ( all_primary_labels.value_counts() / all_primary_labels.value_counts().sum() ) ** (-0.5)Key boosts:
Pretraining on the entire Xeno Archive (0.84 → 0.87).
Pseudo-labeling in two rounds (0.87 → 0.91).
TTA with 2.5-second left/right shifts (0.91 → 0.922).
Winner: Nikita Babich
Nikita dominated the competition—never once seen below second place.
Data:
– +5,489 bird entries from Xeno Archive;
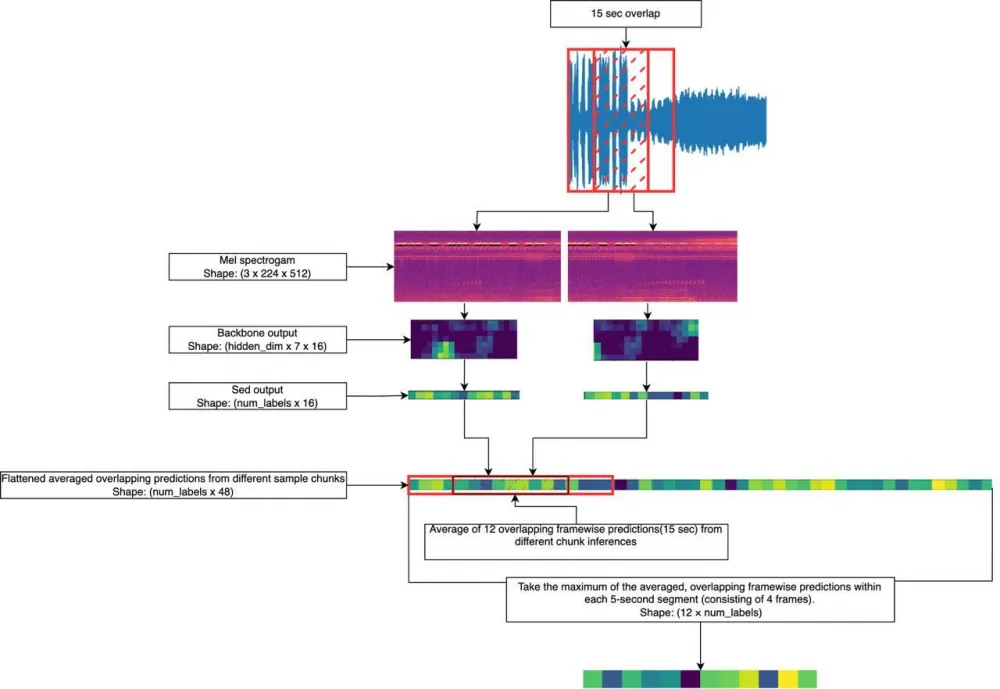
– +17,197 insect and amphibian entries for enhancing models on "other" classes.SED models (Sound Event Detection): precise frame boundaries for events, bridging per-sample to per-frame annotation.
Validation: "No normal validation found, so Nikita validated on LB."
Multi-stage training:
Baseline (Cross-Entropy, AdamW, Cosine, EfficientNet-0 + RegNetY-8) — 0.872.
Pseudo-labeling I + MixUp + StochasticDepth — 0.872 → 0.898.
Power Scaling + pseudo-labeling II (4 rounds) — 0.898 → 0.930.
Separate pipeline for insects and amphibians — 0.930 → 0.933.
Final ensemble: EfficientNet-l0, B4, B3; RegNetY-016; RegNetY-008; EfficientNet-B0 for amphibians/insects.
Key ideas for myself
PowerTransform for pseudo-labels to go through multiple rounds.
SED as a way to refine annotations on pseudo-labels.
Thank you for your attention!
If you'd like to be the first to learn about new competition breakdowns and insights from the machine learning world on Kaggle, as you've probably guessed—I'm inviting you to my Telegram channel: t.me/pseudolabeling









Write comment