
- AI
- A
Understanding Debt — the Hidden Cost of AI-Generated Code
“Understanding Debt” is the hidden cost paid by human intelligence and memory due to excessive reliance on AI and automation. This is especially relevant to engineers in the field of agent-based systems development.
When teams actively use AI-powered tools for code generation, certain costs arise that are not reflected in performance metrics. This is especially true when checking all AI-generated code becomes tedious. These costs accumulate gradually, and eventually, they have to be paid — with interest. This is called “comprehension debt” or “cognitive debt”.
Unlike technical debt, which manifests in obvious issues — slow builds, tangled dependencies, growing anxiety every time you touch a particular module — comprehension debt generates false confidence. The code looks clean. Tests pass successfully. The reckoning arrives unnoticed, usually at the worst possible moment.
Margaret-Anne Storey describes a student team that faced this problem in the seventh week: they could no longer make simple changes without breaking something unexpectedly. The real issue wasn’t messy code. The problem was that no one on the team could explain why certain design decisions were made or how different parts of the system were supposed to interact with each other. The theoretical foundation of the system had dissolved into the code.
This is the accumulation of “comprehension debt” in real-time.
I read discussions on Hacker News where engineers tried to solve a structural version of this problem. It wasn’t about the usual dichotomy of optimism and skepticism, but about understanding what a rigorous approach should look like when the bottleneck in software development has changed.
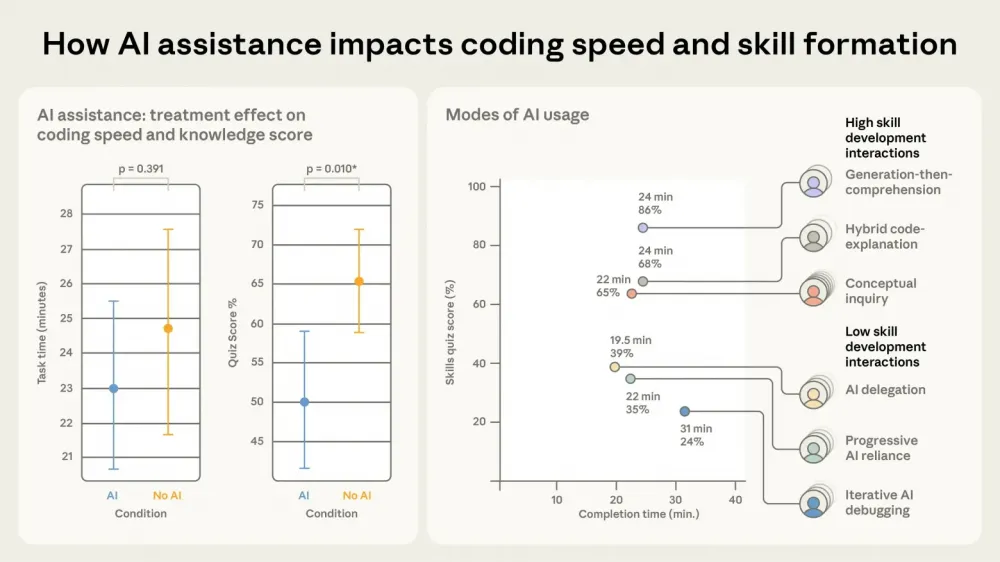
In a recent Anthropic study titled “How AI Affects Skill Formation”, the potential downsides of over-reliance on AI-based coding assistants were highlighted. In a randomized controlled study involving 52 software engineers learning a new library, participants who used AI assistance completed the task in roughly the same time as the control group but scored 17% lower on a subsequent comprehension test (50% vs. 67%). The largest drop was observed in code debugging. Smaller, yet still significant, losses were also noted in concept understanding and code reading. The researchers emphasize that passive delegation (“just make it work”) substantially hinders skill development compared to active, question-driven use of AI. The full article is available on arXiv: https://arxiv.org/abs/2601.20245.
The Problem of Speed Asymmetry
AI generates code much faster than humans can process it. This sounds obvious, but the implications are easy to underestimate.
When a developer on your team writes code, human review has always been a bottleneck, but a productive and educational one. Reading their merge requests forces understanding of the essence. It exposes hidden assumptions, uncovers design decisions that conflict with the system architecture laid out six months ago, and spreads knowledge about what the code actually does among the people responsible for maintaining it.
AI-generated code breaks this feedback loop. The volume is too large. The outputs are syntactically clean, often well-formatted, superficially correct — exactly the signals that historically gave confidence that a merge was safe. But superficial correctness is not systemic correctness. The codebase looks “healthy,” while understanding of the code quietly deteriorates beneath the surface.
I have read an engineer saying that the bottleneck in software development has always been a competent developer who understands the essence of the project. AI does not remove this limitation. It creates the illusion that we have overcome it.
The reverse situation is even worse. When code development was expensive, experienced engineers could review it faster than juniors could write it. AI changes the game: now a junior engineer can generate code faster than a senior can critically evaluate it. The factor that limited development speed and made code review meaningful has been eliminated. What was once a quality criterion has now become a performance problem.
Tests are not a panacea
The desire to rely heavily on deterministic verification — unit tests, integration tests, static analysis, linters, formatters — is quite understandable. I often do this in projects where AI programming agents are actively used. Automate the code review process. Let machines check machines.
It helps. There are strict rules there.
A set of tests capable of covering all observable behavior variants will, in many cases, be more complex than the code it checks. However, complexity that cannot be logically explained does not guarantee safety. And behind this lies a more fundamental problem: it is impossible to write a test for behavior that was not anticipated.
Does anyone write tests to check that elements do not become completely transparent when dragged? Of course not. Such things usually don’t even occur to anyone. These are the errors that slip through unnoticed, not because the test suite is poorly written, but because no one thought to check them.
There is also a specific failure mode worth mentioning. When AI changes the implementation’s behavior and updates hundreds of tests to match the new behavior, the question shifts from “Is this code correct?” to “Were all these changes in the tests necessary, and do I have enough coverage to catch what I didn’t think of?”. Tests cannot answer this question. Only understanding can.
The data is starting to confirm this. Research shows that developers who use AI for “blind” code generation score less than 40% in comprehension tests, while developers using AI for conceptual analysis — asking questions, exploring trade-offs — score over 65%. The tool itself does not destroy comprehension. What destroys comprehension is how the tool is used.
Tests are necessary. But they are not enough.
Specifications do not reflect the full picture
A commonly proposed solution: first, write a detailed specification in natural language. Include it in the merge request. Review the specification, not the code. Assume that the AI has perfectly translated the intention into implementation.
This is as attractive as the cascading methodology once was. First, clearly define the problem, and then start solving it. A clear separation of tasks.
The problem is that translating the specification into working code involves a huge number of implicit decisions — edge cases, data structures, error handling, performance trade-offs, interaction patterns — that no specification could ever fully encompass. Two engineers implementing the same specification will create systems with many observable differences in behavior. Neither implementation is wrong. They are just different. And many of these differences will eventually matter to users in ways no one anticipated.
It’s worth noting another nuance with detailed specifications: a specification detailed enough to fully describe a program is essentially the program itself, just written in a non-executable language. The organizational costs of writing specifications that are detailed enough to replace testing may well exceed the performance gains from using AI to implement them. And that’s before verifying what was actually created.
The deeper problem is that often there simply is no correct specification. Requirements emerge during development. Edge cases are discovered during usage. The assumption that a non-trivial system can be fully described before it is created has been repeatedly tested and proven invalid. AI does not change this. It merely adds a new layer of implicit decisions made without human involvement.
Learn from the mistakes of history
Decades of software quality management in distributed teams under varying conditions and levels of interpersonal communication have produced real, proven methods. These methods do not disappear simply because a model has become a team member.
With the advent of AI, only cost (significantly lower), speed (significantly higher), and interpersonal management overhead (practically zero) change. The need for a specialist with deep knowledge of the system, to maintain a holistic understanding of what the code actually does and why, remains unchanged.
This is an unpleasant redistribution imposed on us by insufficiently meaningful information.
As AI scales, an engineer who truly understands the system becomes increasingly valuable, not less. It is important to be able to immediately identify, by looking at differences in code, which behavioral patterns are the most problematic. It is important to remember why this architectural decision had to be made eight months ago.
It is important to distinguish safe refactoring from imperceptible changes that users depend on. This skill becomes a scarce resource on which the entire system depends.
Gap in measurements
The danger of the understanding debt is that our current measurement system does not account for it.
Task completion speed metrics look flawless. DORA metrics remain stable. The number of merge requests has increased. Code coverage is green.
Performance controllers see speed improvements. They cannot see shortcomings in understanding because none of the ways of measuring organizational performance reflect this aspect. The incentive system is properly optimized for what it measures. What it measures no longer reflects what truly matters.
This is why the debt of understanding is more insidious than technical debt. Technical debt usually represents a conscious trade-off — we choose the shortcut, roughly know what it entails, and can plan a solution. Understanding debt accumulates unnoticed, often without any conscious decision to create it. It is the accumulation of hundreds of checks when the code looked fine, tests passed, and another pull request was in the queue.
The assumption that reviewed code is understood is no longer valid. Engineers approving code they don’t fully understand implicitly approve bad code. Responsibility is distributed unnoticed by everyone.
The regulatory horizon is closer than it appears
Any industry that develops too quickly eventually ends up regulated. The tech industry has been unusually shielded from this dynamic, partly because software failures can often be fixed, and partly because the industry developed faster than regulators could keep up.
This window of opportunity is closing. When AI-generated code operates in healthcare systems, financial infrastructure, and government services, the statement “this was written by AI, and we did not conduct a full review” will not stand up to scrutiny in an incident report, when lives or valuable assets are at stake.
Teams that are currently developing the discipline of understanding — focusing on genuine comprehension rather than just passing tests as a given — will be in a better position when the critical moment arrives than teams that optimized their activities solely for development speed.
The essence of the problem
At present, the right question is not “how do we generate more code?” but “how do we better understand what we create?” to ensure our users consistently receive a high-quality experience.
This approach has practical consequences. It means a crystal-clear definition of what the change should achieve before it is implemented. It means that verification should be considered not as a secondary issue, but as a structural constraint. It means maintaining a systemic mental model that allows identifying AI errors at the architecture level, not line-by-line. And it means an honest definition of the difference between "tests passed" and "I understand what this does and why."
Making code generation cheap does not mean that understanding the code can be easily skipped. The work of understanding is the main task itself.
The translation is performed by AI. But someone still needs to understand what has been created, why it was created this way, and whether these implicit decisions were correct — or are you just delaying the payment of a bill that will eventually have to be paid in full.
Sooner or later, you will have to pay for understanding. This debt quickly accrues interest.
Additional materials:










Write comment