
- Security
- A
Adapting fuzzing to find vulnerabilities
Fuzzing is a very popular software testing technique using random input data. There are a huge number of materials on the web about how to find software defects using it. At the same time, there are almost no articles and presentations in the public domain about how to find vulnerabilities using fuzzing. Perhaps security researchers do not want to share their secrets. All the more interesting to consider this topic in this article.
Fuzzing is a very popular software testing technique using random input data. There are a huge number of materials on the web about how to find software defects using it. At the same time, there are almost no articles and presentations in the public domain about how to find vulnerabilities using fuzzing. Perhaps security researchers do not want to share their secrets. This makes it even more interesting to consider this topic in this article.
I have been researching operating system security and fuzzing for several years. I like this tool because it allows you to delegate the tedious task of writing tests for software to the computer. At the same time, the ways of using fuzzing can vary greatly depending on the goals of its application.
In particular, a developer uses a fuzzer for their code to find all the errors in it. Therefore, the developer usually includes all available error detectors in their project and analyzes all the cases of their triggering that are detected during fuzzing.
A security researcher has different goals:
Unlike a developer, he is not interested in all errors in the code, but specifically looks for vulnerabilities. These are errors that can be triggered by an attacker interacting with the system's attack surface.
Moreover, for a security researcher, errors that can be triggered relatively quickly and reliably in the system are of greater value.
Finally, a security researcher strives to find unique vulnerabilities that his competitors are unlikely to find. It is very frustrating to spend time and effort analyzing a program failure only to find out that someone else has discovered and fixed it.
In this article, I will explain how these features affect the configuration and use of a fuzzer.
To make the article specific, I will consider my favorite kernel fuzzer syzkaller. This is a well-known open project used for dynamic kernel analysis in many operating systems. I have been using it for several years to research Linux kernel security.
Architecture of the syzkaller fuzzer
The diagram shows the architecture of syzkaller — see Fig. 1.
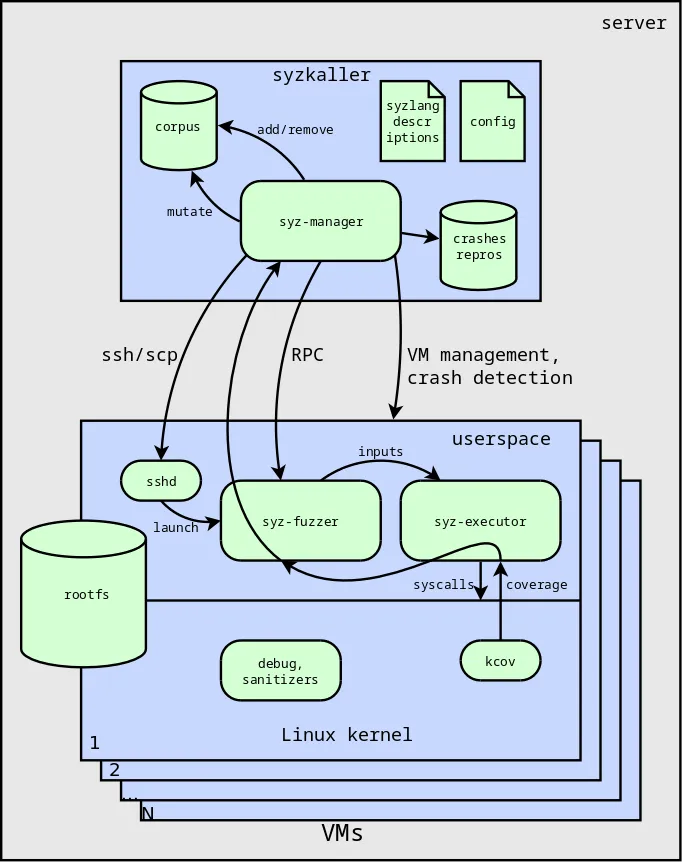
The main part and the core logic of the syzkaller fuzzer is located in the syz-manager component. It is responsible for managing virtual machines during the fuzzing process. The syz-manager also works with a set of programs for kernel testing, called the corpus. It adds new promising programs to the corpus and removes useless ones. These programs are essentially random input data for kernel fuzzing. They are written in a special language called syzlang, which defines the format and arguments of Linux system calls.
If a kernel crash occurs during the fuzzing process, the fuzzer saves this event to the database and tries to generate a minimal reproducer — the shortest combination of system calls that can trigger this error in the kernel.
The kernel fuzzing process itself takes place inside a virtual machine. In its user space, parts of syzkaller execute system calls and collect kernel code coverage metrics as a result of testing. This information is passed to the syz-manager, which uses it to select promising programs for the fuzzing corpus. This is a very effective technology called coverage guided fuzzing.
Also, when fuzzing Linux, kernel error detectors and so-called sanitizers are very important. They are needed to cause the kernel to crash in the event of an abnormal situation. Without them, an error that occurs, such as use-after-free, will not be detected and fuzzing will essentially be useless.
This is the basic architecture of the syzkaller fuzzer. Now let's look at how to adapt it to find vulnerabilities in the Linux kernel.
How to find vulnerabilities in the Linux kernel using fuzzing
Vulnerabilities in the Linux kernel can be divided into two classes:
Vulnerabilities that allow local privilege escalation (LPE). When exploiting such a vulnerability, a local unprivileged user becomes a root user or another user with elevated privileges in the system.
Vulnerabilities leading to remote code execution (RCE) in the kernel. When exploiting such a vulnerability, an attacker interacting with the Linux system over the network achieves arbitrary code execution in the kernel space.
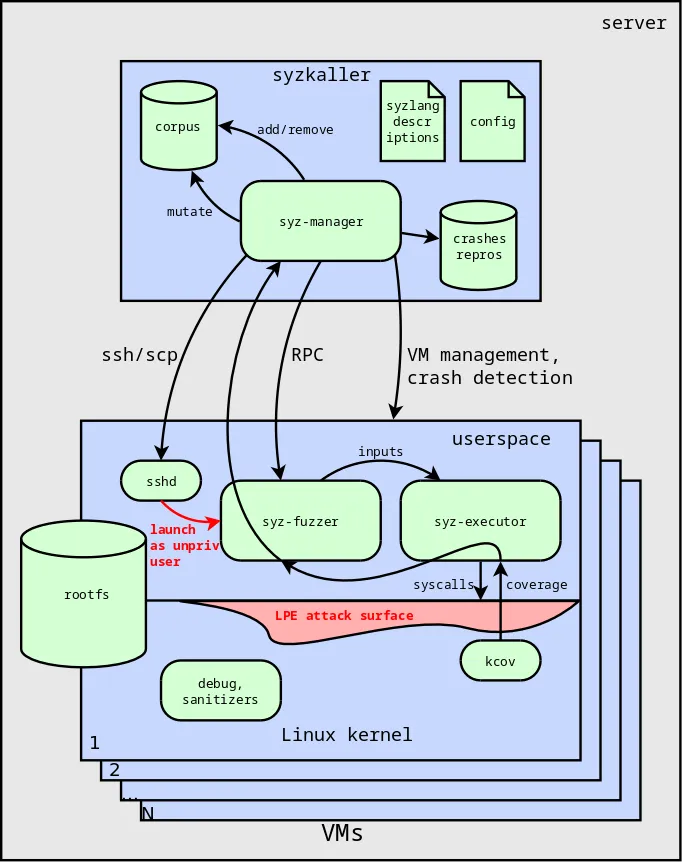
For syzkaller to find only bugs potentially leading to LPE, a single modification is needed — running the fuzzer inside a virtual machine without administrator privileges. In this case, system calls will be executed under the account of an unprivileged user, and only the Linux kernel attack surface will be tested, as shown in the diagram (see Fig. 2).
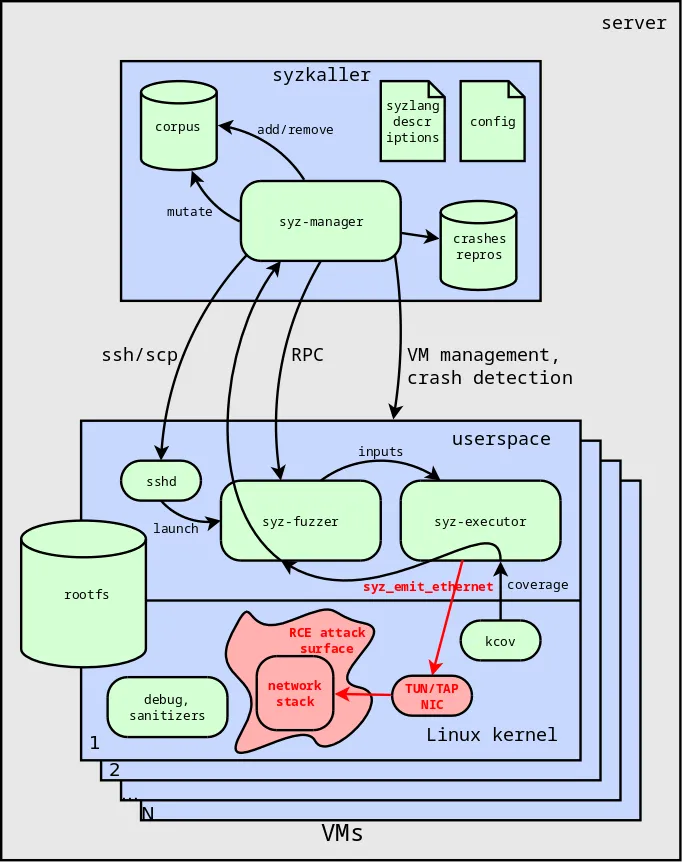
To find bugs potentially leading to RCE, a different approach is needed: fuzzing the Linux kernel's network interfaces. This is detailed in an excellent article by Andrey Konovalov Looking for Remote Code Execution bugs in the Linux kernel. In it, he showed the structure of the TUN/TAP virtual network interface and the special syz_emit_ethernet call, which allows the syzkaller fuzzer to interact with the Linux kernel's network stack.
How to find consistently reproducible vulnerabilities
As mentioned above, for a security researcher, the most valuable errors are those that can be relatively quickly and reliably triggered in the system.
The syz-manager has a certain logic that triggers when a kernel crash is detected. It starts testing the entire large set of system calls that caused the error and gradually finds the minimal reproducer program that leads to the desired effect using the dichotomy method. This process works unstably due to various side effects and race conditions in the kernel. Therefore, when searching for a reproducer, there are often errors of the 1st and 2nd kind.
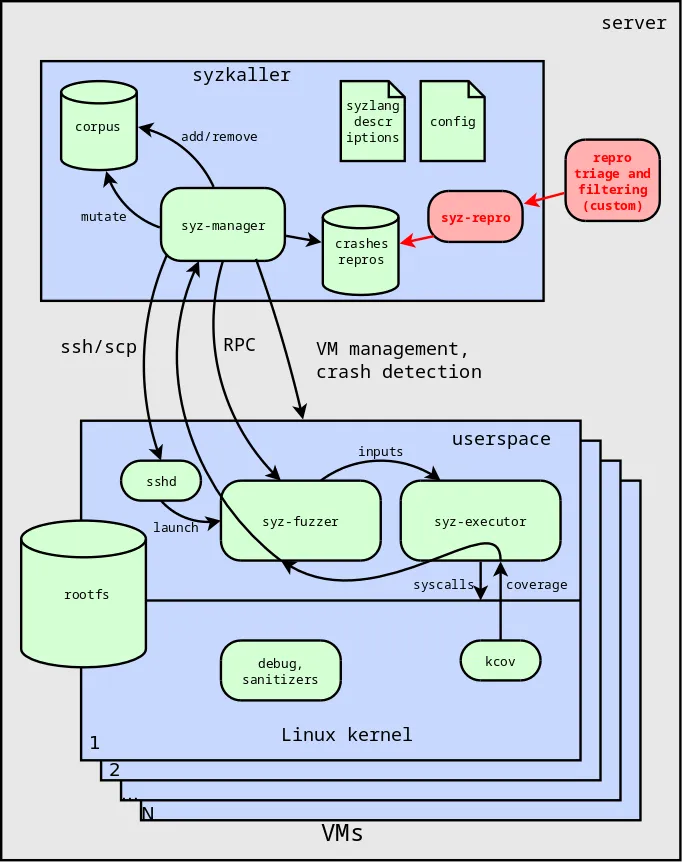
To prevent the security researcher from wasting time and effort on analyzing unstable reproducers, it is worth designing an automatic system for sorting fuzzing results (reflected in the diagram - see Fig. 4). I also developed such automation according to my search criteria. This is easy to do using the syz-repro utility, which allows you to repeat the process of identifying the minimal reproducer several times.
How to find unique vulnerabilities
Let's move on to the most interesting part of the article and consider how to find unique vulnerabilities that other researchers are unlikely to find.
The fact is that it is impossible to find something unique using standard tools that everyone has. Therefore, you need to somehow modify your fuzzing process to find unique vulnerabilities.
In the presented diagram (see Fig. 5), I marked in red and numbered the components of the syzkaller fuzzer and the Linux kernel that need to be modified in order to obtain unique findings.
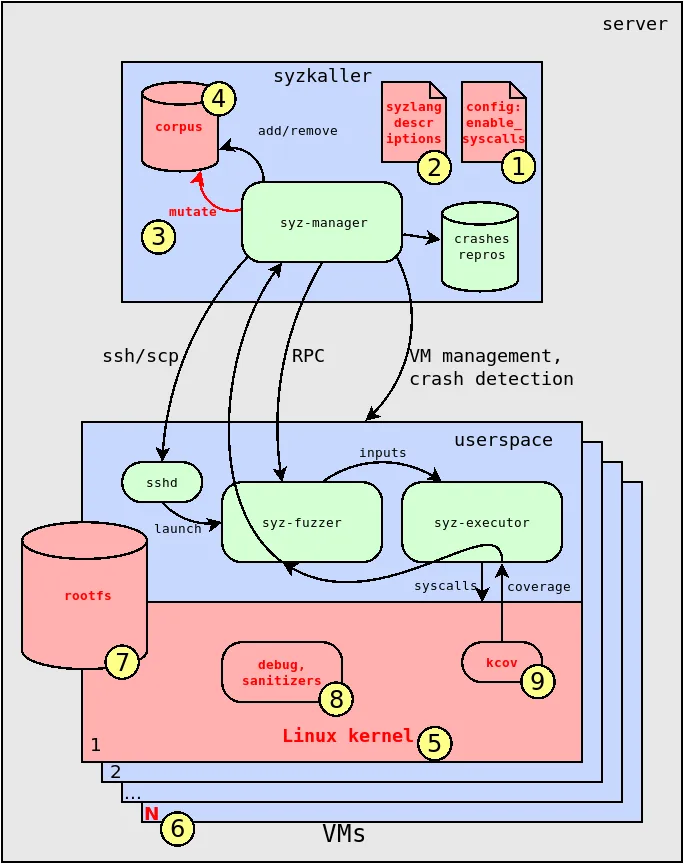
The simplest idea is to limit the allowed Linux system calls that the fuzzer executes. This can be done in the syzkaller configuration. This method can narrow the attack surface that is subject to fuzzing. As a result, syzkaller can go deeper into the kernel code and get more coverage in the subsystem under study.
Another effective way to find undiscovered vulnerabilities is to develop new kernel API descriptions in syzlang. As mentioned above, syzlang is a special language that describes the format and arguments of kernel system calls. Those that are not yet described in syzkaller are not subject to fuzz testing and therefore represent an interesting target. Many vulnerabilities have been found by researchers using this method.
There are many fuzzers for user-space programs, and they compete with each other by improving fuzz corpus mutation mechanisms and applying symbolic execution. This growth area is also relevant for syzkaller: changing the mutation engine affects which code paths in the kernel the fuzzer touches. This can help find unique vulnerabilities. However, such a modification of the fuzzer requires a deep understanding of its structure.
A simpler way to influence the fuzzing process is to start with a specially prepared corpus. Many studies show that programs in the initial corpus (also called seeds) have a significant impact on the fuzzing process.
Let's move on to modifying Linux kernel components. Having the source code available to the researcher makes it possible to perform a remarkable trick - to modify the Linux kernel to make it more convenient for fuzz testing. This is how I found the vulnerability CVE-2019-18683, for which I then developed a prototype exploit, performed responsible disclosure, and developed a patch. This Linux kernel vulnerability was hidden behind a kernel warning, and I found it by modifying the kernel to disable all warnings. Changing the fuzzing target can be very effective in finding new bugs.
Now let's consider the most obvious way to stand out from the competition - using even more computing power. The more servers perform fuzzing, the more virtual machines are running on them, the more kernel crashes they detect. It is important that the researcher has enough strength and time to analyze them.
Another unusual way to find unique bugs in the Linux kernel is to change the rootfs. The virtual machine's file system image does not directly affect the Linux kernel being fuzzed, but sometimes changes in the rootfs can have an unexpected effect and enable additional kernel APIs. This is how I discovered the vulnerability CVE-2017-2636, for which I also managed to develop a prototype exploit and perform responsible disclosure. In that case, I added compiled kernel modules to the VM's file system image, and during fuzzing, the kernel automatically loaded the n_hdlc module, in which a bug was then discovered and analyzed by me.
A rather complex but very effective approach is to refine sanitizers and other error detection tools in the Linux kernel. Some types of errors go unnoticed during fuzzing because they are not tracked by detectors and therefore do not cause a kernel crash. An example is an out-of-bounds access within a kernel object sk_buff, which is a representation of a network packet in the Linux kernel memory. Developing a detector for this class of errors would allow vulnerabilities to be detected during fuzzing that could potentially lead to RCE.
Another approach, common in the development of user-space fuzzers, is directed fuzzing, which limits the amount of code being tested. The same can be done when fuzzing the Linux kernel. To do this, you need to configure the cover_filter in syzkaller or modify the kcov kernel subsystem to collect coverage only for the Linux subsystem in which we are looking for vulnerabilities.
Conclusion
Sharing these ideas, in conclusion, I will tell a short story.
In 2021, I found a vulnerability in the Linux kernel CVE-2021-26708. When researching methods of exploiting it, I needed a special heap-spraying primitive — a kernel object whose size and content could be controlled by an attacker from user space. None of the publicly known exploit primitives were suitable. After long and exhausting reading of the kernel source code, I decided to delegate this task to the computer and use fuzzing to find the desired object. This is how I invented heap spraying using the kernel object msg_msg, which then became very popular in the research community.
Therefore, fuzzing is a wonderful tool that can be useful to a security researcher not only for finding vulnerabilities. At the same time, fuzzing requires the researcher to be willing to risk their time and the computing power of their servers.
Thank you for your attention!







Write comment