
- AI
- A
A little about Chain-of-Thoughts
Main problems of LLM:
Solving complex logical problems (Searching for implicitly given information)
Security (Counteracting hacks and ethical behavior)
Hallucinations (Generating new information that does not correspond to reality)
All problems are complex and mutually overlapping. When solving a complex problem, we expect the model to generate something new, something we don't know and didn't write in the request: that is, the model must generate information that is not presented in the request. When we ask the model to find something, we expect it to write information that is presented in the request. Often a complex problem includes searching for information in the request: here we can see the contradiction that the model faces.
Introduction
OpenAI recently tackled the first problems with a new model. The new model uses the Chain-of-Thoughts technique to solve problems.

At the same time, the company continues to adhere to the principle of a minimalist interface:
The user enters a prompt
The model performs step-by-step actions with it
The user receives a summarized response, which significantly reduces the user's effort. All this is accompanied by a cool animation showing the stages of the model's "thinking": this makes everything more intuitively understandable. Based on several statements, certain conclusions can be drawn:
The internal dialogue will be hidden from the user in the future
Increasing thinking time is considered a benefit (The Thinker says hello), implying deeper and more thorough information processing.
The model does not want to be a polyglot, possibly for token optimization or dataset specialization. However, it works quite well with the Russian language.
The model consumes a huge number of tokens compared to existing ones, and the price bites, not to mention the restriction of access to the API
The model works better with direct and clear instructions

Abstractly speaking, the model contains a loop in which the input data is run. At each stage of the loop, they are enriched with synthetic information. In two stages: in the first, a "certain" instruction is generated, in the second, the model's response is obtained. The model has a certain mechanism for exiting the loop. All or part of the information is summarized. How exactly this model is implemented is unknown to me, but the logic of the process is quite obvious:
The loop can be implemented both inside the model and as an external tool
The instruction can be fixed, selectable, or generated by the model
The model's response can be generated by an internal or external model
The loop can be controlled by both the model and some external tool
Summarization can be controlled by both the internal model and the external one
The five points above are unknown variables that will affect the quality of the final response. The question arises: should all five points be synthesized by the model or not? If not, how many should be synthesized? Should non-synthetic information be added at some stage or not? Should the user see the thought process or not, or partially not?
Regardless of the model's efficiency, and it exists, this approach will have long-term consequences for the entire industry: how much data will be expected from the user, will synthetic data be shown to the user, and so on.
What is a Chain of Thought?
A chain of thought can be implemented, in a certain variant, not only with the expensive o1, but with all existing models.
How?
Let's take a closer look at what is meant.
Structurally, it represents a set of messages that are sequentially sent to the model. The key point: the model's responses are added to this set of messages. In the most standard scenario, the chain is extended each time by the model's response and the user's request. How is this different from just a huge prompt, sent to the model in one go?
This differs from a significant chunk of information sent simultaneously in the following points:
Structuredness: a structure arises instead of a single response.
Step-by-step: interaction stages appear, detailing the interaction with BAM.
Interactivity: each stage can be independently changed. That is, it is the very dialogue that the user conducts with any chat.
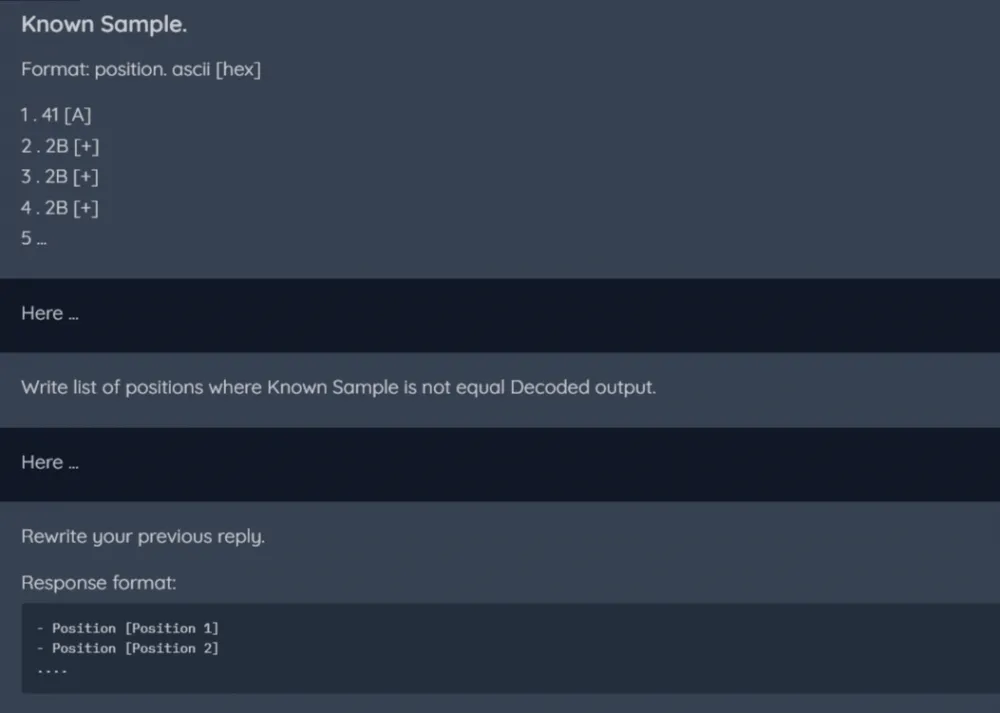
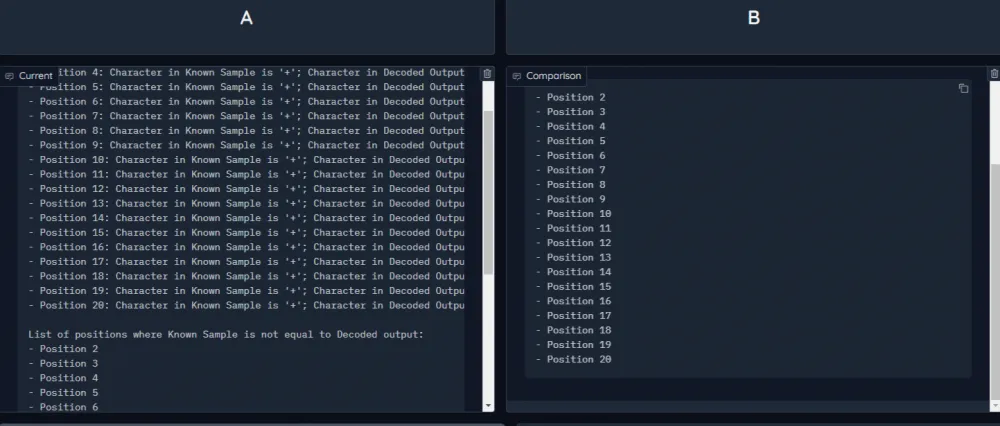
Example message chain:
I have such a problem. How to solve it?
Answer 1
Write me the disadvantages of the solution
Answer 2
Come up with how to overcome the disadvantages
Answer 3
Give me the final solution
Answer 4
It is worth noting that all questions are extremely general and abstract in nature. Individual meaning is added by unique texts describing the user's problem, their situation, their capabilities, etc. By responding to requests with synthesized answers, the model simultaneously adapts to the context of the conversation and deepens the understanding of the problem both for itself and the user.
The chain of thoughts is sent to the model incrementally: first the first question, then the first pair of question-answer and the second question, and so on. The dialogue becomes more complex and accumulates data at each stage. Technically, the Chain of Thoughts is much more token-hungry than a single sheet: it is more expensive and slower (due to the number of tokens to send). It also works poorly with post-sending, because to send the next message you need to wait for the previous one to be received. Therefore, I practically did not use GPT-4 until the appearance of GPT-4o-mini.
Chain of Thoughts can help understand the model better:
Here is my problem. How to solve it? In the second stage, not just the second message will be sent, but the first message, the response to it, and the second message:
Here is my problem. How to solve it?
Model response 1
Instruction to add synthetic data to the model. Data that will help understand "how the model thinks"
Model response 2
Request for the final solution

For the Chain of Thoughts model, it will look like text, marked inside as user requests, its responses, and system instructions (if possible). And it will accept it in increasing amounts.
In this case, the duration of the cycle and the moment of its end will be fixed: they will depend on the number of questions you ask. Additionally, you can independently control the model's work at each stage of the dialogue. Instructions can be both fixed and created with the participation of BYAM.
The Chain of Thoughts should be treated as a method of breaking down the information provided to the model. Any problem you address to the model has certain nuances important specifically for you. These nuances need to be provided to the model so that it can prepare the highest quality response.
This information consists of the following parts:
Your instructions in the Chain of Thought can range from simple requests to complex, multi-level tasks. They may include requests for text creation, data analysis, argument formulation, etc. The main thing here is the clarity and accuracy of your instructions so that the model can correctly understand your requirements.
Your examples play an important role in the Chain of Thought. They help the model understand what kind of answers you expect. These can be both "good" examples that show the desired result, and "bad" ones that help avoid undesirable answers.
In fact, any model can be used to create a Chain of Thought if the context size allows. This is an interesting and multifaceted tool for managing the model. For successful use of the Chain of Thought, it is important to consider the context. This may include previous requests, user information, current circumstances, etc. Finally, the Chain of Thought is a dynamic process. You can add new instructions and examples as needed, adjusting the model's responses and improving the results.









Write comment