
- AI
- A
Hallucinations in LLM and methods of combating them
One of the main problems with using large language models in business is that LLMs are prone to hallucinations. How can you trust your customers to a chatbot that can go off the rails and say something inappropriate at any moment? Or how can you trust a corporate AI assistant if it randomly makes up facts?
This is indeed a problem, especially considering that LLMs cannot be fired or held accountable. The nature of AI systems is such that they have no ulterior motive to lie and gain nothing from it, but despite their apparent reasonableness, they are not human, so they cannot be held accountable.
Some believe that Retrieval-Augmented Generation (RAG) is a universal solution, but in fact, this approach only eliminates one of the causes of the problem and does not help with the others. Only a combination of several approaches can yield some results.
However, not all is lost. There are ways to deal with this problem, and let's look at them.
To avoid delving into philosophical debates about what "hallucination" is, let's define the three most common cases:
The model understands the question but gives a wrong answer.
The model does not understand the question and therefore gives a wrong answer.
The question does not have a clear answer, and therefore, if you disagree with the model, it does not make its answer incorrect. For example, the question "Trump or Biden?" — any answer will just be an opinion.
Let's start with the second case. Here are the reasons why the model might misunderstand the question:
The question is incorrect (ambiguous, not clear enough, etc.), and therefore the answer will be incorrect. This is not the model's fault — ask better quality questions.
The model lacks context.
The model poorly understands the language you are using.
Bad luck, or in other words, the probability distribution led the reasoning in a strange direction.
Now let's move on to the first case: why can the model "lie", that is, give factually incorrect and deliberately wrong information, if it understood the question?
The model did not follow all the logical steps to derive the answer.
It lacked context.
The information (context) it has is incorrect.
The model has the correct information, but it got confused.
The model was trained to give wrong answers (for political or other reasons).
Bad luck: the probability distribution led the reasoning in a strange direction.
The model is set up to fantasize (sometimes this may be desirable).
Overfitting or Underfitting: the model was trained in a specific area and tries to apply this logic to another area, which leads to erroneous conclusions.
The model is overloaded with data and loses context.
I will not discuss those aspects that are not a problem of the model, such as bad questions or questions without a correct answer, as well as deliberate training to give false answers. Let's focus on what we can try to solve, step by step.
The model lacks context or information, or the provided information is incorrect or incomplete.
This is where RAG (Retrieval-Augmented Generation) comes to the rescue. RAG, when properly implemented, should provide the model with the necessary context to answer. Here is an article on how to properly implement RAG.
It is important to do this correctly, with all the necessary metadata about the structure and attributes of the data. It is advisable to use methods such as GraphRAG and reranking at the retrieval stage, so that the model receives only relevant context. Otherwise, it may get confused.
It is also extremely important to maintain the relevance of the data you provide to the model and constantly update it, taking into account versioning. If you have data conflicts, which is not uncommon, then the model will start to produce conflicts in the responses. There are methods, such as the Maximum Marginal Relevance Search (MMR) algorithm, which takes into account the relevance and novelty of the information for filtering and reordering. However, this is not a panacea, and it is best to solve this problem at the data storage stage.
Language
Not all models understand different languages equally well. It is always preferable to use English for prompting, as it works best for most models. If you need to use a specific language, you will have to choose a model created for that language.
For example, in the Russian language there are many endings and surnames in which LLama often gets confused. For the Russian language, the best results at the moment are shown by Gigachat from Sber and the open-source Qwen. LLama works, but not perfectly.
The model does not follow all logical steps to get the conclusion.
You can make the model follow a certain reasoning process using techniques such as SelfRAG, Tree of Thought, or SelfCheckGPT. Here is an article about these techniques.
The main idea is to make the model reason step by step and explain/check its conclusions and intermediate steps so that it can detect its errors.
An alternative approach is to use an agent model, where several LLM agents communicate with each other and check the results and each step of reasoning.
The model got confused with the available information or was “unlucky”.
These two problems are caused by the same reason, and this is a more complex case. Models work by stochastically predicting the next token in a sentence. This process is somewhat random, so it is possible that the model will randomly choose an unlikely path and go astray. This is a feature of how LLMs work.
There are several methods to deal with the consequences of their architecture:
MultiQuery — running multiple queries to the LLM for the same user query and then selecting the best one based on a relevance metric, such as Cross Encoder. If you get three very similar answers and one that is very different, the latter is most likely a random hallucination. This method incurs additional costs for additional LLM calls but is a reliable way to avoid random errors.
Lowering the model temperature — setting the temperature parameter to a lower value to reduce the likelihood of choosing less likely paths (i.e., fantasies).
There is another problem that is more difficult to fix. The model stores semantically similar ideas close to each other, and this also happens in vector databases in vector space. If it is asked about facts that have close but irrelevant semantic "neighbors," it may lead the model down the path of least resistance. The model uses, so to speak, associative memory, so its thinking is associative. This way of thinking is not suitable for tasks like chess or mathematics. The model has "fast thinking" as described by Kahneman, but it lacks "slow thinking".
For example, you ask the model how much is 3 + 7, and it answers 37. Why???
It becomes clear when you look at 3 and 7 in vector space: the closest vector to them is 37. The error is obvious here, but in other cases, it may be much less noticeable.
Example:

The answer is incorrect. "Afonso" was the third king of Portugal, not "Alfonso". There was never a king named "Alfonso II" in Portugal. The mother of "Afonso II" was Dulce of Aragon, not Urraca of Castile. From the LLM's point of view, "Alfonso" is almost the same as "Afonso", and "mother" is a direct match. Therefore, if there is no "mother" next to "Afonso" in the vector space, the LLM chooses the combination "Alfonso/mother".
Here is an article that explains this in more detail and suggests possible solutions.
Also, fine-tuning the model on your domain-specific data reduces the likelihood of such errors, as the model is less confused by similar facts in borderline cases.
The model is set to hallucinate
This can be done either through a master prompt or by setting the model's temperature too high. Therefore, to avoid this, you need to:
Instruct the model not to give an answer if it is unsure or does not have the information.
Ensure that nothing in the prompt encourages the model to invent facts, and in general, make the instructions as clear as possible.
Set a lower model temperature.
Underfitting and Overfitting
If you use a model trained in the healthcare domain to solve programming tasks, it will "hallucinate". In other words, it will try to fit a square peg into a round hole because it only knows that approach. The same thing happens if you use a general-purpose model trained on general internet data to solve tasks in a narrow field (say, petrochemistry).
The solution is to use an appropriate model for your field and fine-tune/train it in the relevant area. This will significantly improve accuracy in certain cases. I'm not saying you should always do this, quite the opposite, but in some cases, it may be necessary.
Another example is using a model that is too small (in terms of parameters) to solve your problem. Yes, for certain tasks a large model is not required, but for others it is, and in such cases, you need to choose a model that is at least as large as necessary. Using a model that is too large can be costly, but it will at least work correctly.
The model is overloaded with data and starts to lose context
You might think that the more data, the better — but that's not the case! (Or rather, not quite the case).
The model's context window and attention are limited. Even modern models with context windows of millions of tokens handle this poorly. They start to forget things, ignore data in the middle, and so on.
The solution is to use RAG (Retrieval-Augmented Generation) with proper context size management. You need to pre-select only relevant data, re-rank it, and feed it into the LLM.
Here is my article where some techniques for this are discussed.
Also, some models do not handle long context at all, and at a certain point, the quality of responses starts to decrease with increasing context size, see below:
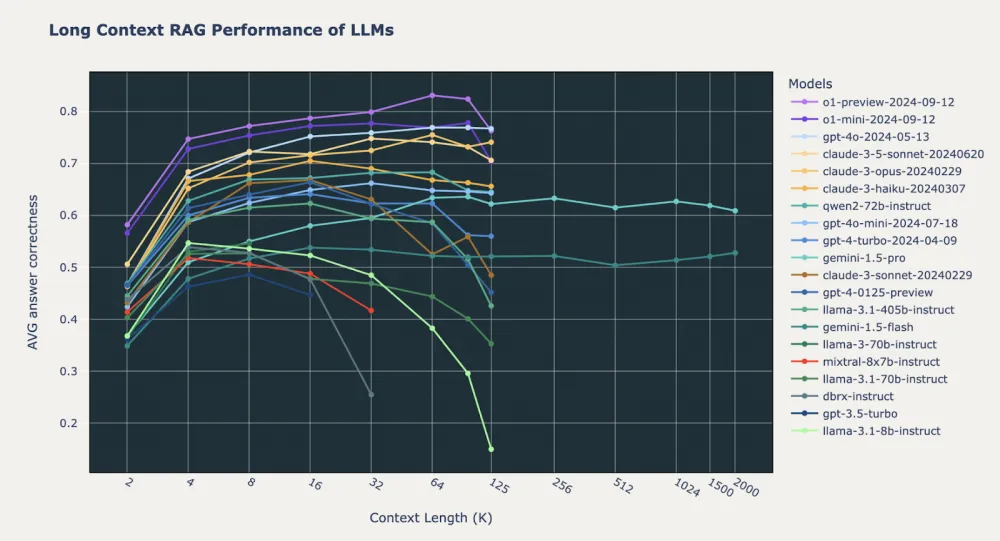
Here is a study on this topic.
Other common techniques
Human in the loop
You can always include a human in the process of checking the model's output. For example, if you are using an LLM for data annotation (which is actually a great idea), you need to use it together with real people who will check the results. Or apply the system in co-pilot mode, where the human makes the final decision. However, all this does not scale well.
Oracles
As an alternative to humans, you can use an automated "oracle" to check the system's results, if possible.
External tools
Certain tasks, such as calculations and mathematics, should be performed outside the LLM using the tools provided by the model. For example, you can use the LLM to generate a query to an SQL or Elasticsearch database, execute this query, and then use the results to form the final response.
What to read next?
Guide to RAG Architecture
Building a Company Knowledge Base and Document Search on LLM and RAG
Advanced RAG
All the best!









Write comment