
- AI
- A
How LLMs are changing system architecture: from simple data pipelines to intelligent autonomous agents
At every technical conference lately, the word "agents" is sure to be mentioned. They are presented in different ways: as the next step after RAG, as a silver bullet for solving all problems, and as an absolute replacement for all classic pipelines. And those who do not use agents yet are hopelessly behind progress.
But is this really the case? This article is inspired by Anthropic's vision of applying LLM in processes and building agents, so let's try to figure it all out.
Let's talk about Data Pipelines, LLM Workflows, and LLM Agents, and also compare them with each other.
Anthropic should always be read because the company is at the forefront of LLM development and often sets the direction for the entire industry with its tech reports.
What are LLM agents and when to use them
There is currently some confusion in the definition of "agents". Some call agents only fully autonomous systems that operate independently for a long time and use external tools to perform tasks. Some call it just a sequential call of LLM with different prompts, and if you really need a fancy line in your resume and new stripes on your epaulettes, then any process where an LLM was barbarically stuck in and was not needed there at all becomes an agent.
Anthropic highlights two main architectural approaches:
Workflows — approaches where LLM and tools are used and orchestrated in predefined ways
Agents — approaches where LLM dynamically manage their own processes and use of tools

Since this article is not just a translation, but a more general comparison, I will add another anglicism Data Pipelines, which in its pure meaning does not quite fit into the company of the terms above, but here it will be a generalization of the classic algorithms and processes we are used to, in which there is no LLM at all.
Comparison of approaches and how to choose them
When developing applications, you should always look for the simplest and most reliable solution, and increase complexity only when necessary. "Simplicity" here means predictable behavior, low resource consumption, good manageability, and maintainability of the process. And this automatically makes the use of agents inappropriate, whatever is meant by them.
Agent systems work better in certain situations, but they are slower and more expensive. Therefore, it is important to understand whether such complexity is really needed - agents perform better only where it is necessary to adapt their behavior and flexibly adjust to the situation.
A small example:
Take a typical retail process: every hour we collect data from the cash registers, calculate revenue by category, look for anomalies, and send a report. Can we add an LLM agent here for "smart" analysis of causes and writing recommendations? Of course. But is it necessary? This is a good question, which, as they say, has a big trade-off between cost, responsibility, work for the sake of work, and common sense.
Do not expect agents and LLM in general to instantly solve all tasks, they are tools. An LLM agent will come and put things in order - this is a myth that does not eliminate the need for quality work with your data. Because otherwise it will be like in the meme:
And there is one more important point.
As soon as an LLM appears in our chain – it doesn't matter which one: distilled or quantized, specialized or not – it immediately requires adding protection mechanisms (what they call guardrails) to the input and output, because something we wouldn't want might come out of the model. And it's good if it's just a hallucination, and not a leak of someone else's personal data or strange ideas about the beautiful from someone else's pretrain.
I will provide a comparison table of three approaches (without LLM, with LLM, and agents) and the optimal places for their application. And after that, there will be mostly an author's (not literal) translation of Anthropic's vision on architectures using LLM.
Comparison of Data Pipelines, Workflows, and Agents
Characteristic | Data Pipelines | LLM Workflows | LLM Agents |
|---|---|---|---|
Execution Flow | Predefined and linear | Predefined steps with possible conditions | Dynamic, determined by the model itself |
Decision Making | Based on strict rules and conditions | Based on predefined rules and LLM | Autonomous, based on context and goal |
Error Handling | Queues, retries, try/catch | Predefined error handlers | Self-recovery and finding alternative paths |
Scaling | Horizontal, through parallelism | Vertical (more powerful models) and horizontal | Primarily vertical (improving agent capabilities) |
Monitoring | Performance metrics | Response quality metrics, step execution time | Autonomy metrics, decision quality, resource usage |
Predictability | Highest | Medium | Low |
Flexibility | Low (requires rewriting when changes occur) | Medium (within predefined steps) | High (can adapt to new situations) |
Resource Usage | Predictable, set | Moderate, depends on step complexity | High, unpredictable |
Development Complexity | Any, depends on the task | Medium or high | High |
Debugging | Straightforward, regular log analysis | Possible at each step | Complex, requires special tools |
Development Time | Average | High | Very high |
Data Requirements | Structured | Structured + partially unstructured | Any data types |
Autonomy | None | Partial | High |
Operational Cost | Low to medium | Medium | Very high |
Development Speed | Fast for standard tasks | Medium | Slow |
Reusability in Other Tasks | Low overall, high for similar tasks | Medium | Low (requires adaptation) |
Documentation | Standard technical | Requires step and prompt descriptions | Requires detailed description of capabilities and limitations |
Testing | Any tests | Unit tests + prompt tests | Complex behavior testing |
Versioning | Standard (code + configs) | Code + prompts + models | Complex (including knowledge versions) |
Optimal usage scenarios:
Data Pipelines:
ETL processes
Processing large volumes of structured data
Regular, repetitive tasks
Performance-critical processes
Predictability and security-critical processes
LLM Workflows:
Structured tasks with NLP elements
Processes with predictable steps but requiring more complex context understanding at some of them
Tasks where the balance between automation and control is important
Processes with clear rules and constraints
LLM Agents:
Complex tasks requiring independent decision-making
Research tasks
Tasks with an uncertain number of steps and autonomy in them
Processes requiring adaptation to new situations
Well, then I hand it over to Anthropic with my slight adaptation.
Frameworks for working with agents
There are many frameworks that simplify the implementation of agent systems, including:
LangGraph from LangChain;
AI Agent framework from Amazon Bedrock;
Rivet — a constructor of LLM processes with a graphical interface;
Vellum — a tool with a graphical interface for creating and testing complex workflows.
These frameworks make it easier to get started by simplifying standard low-level tasks such as calling LLM, calling additional tools, and chaining calls together. However, frameworks often create additional layers of abstraction that can hide underlying prompts and responses, complicating debugging. They can also encourage adding complexity where a simpler solution would suffice.
An important recommendation is to start with direct use of the LLM API: many things can be implemented with just a few lines of code. But if you start using something, you should understand more deeply how it works, as incorrect assumptions about what is happening under the hood of the framework are a common cause of errors and lack of expected results.
Architecture analysis
Let's move on to the analysis of architectures offered by researchers, starting from simple ones and ending with everyone's favorite agents.
This is the base — the "LLM with addition" block
The main building block of agent systems is the LLM, supplemented with extensions such as search, tools, and memory.
Ideally, these additions should be immediately built into the desired model (as stated in the original), but, in principle, nothing prevents us from making them on our side if necessary.
In the examples further, we will assume that each LLM call has access to these extended capabilities.
In the case of the basic block, it is recommended to focus on two key aspects: adapting this block to your task and ensuring a well-documented protocol for working with it. Anthropic themselves recently released a ready-made protocol for such cases (Model Context Protocol), which allows integration with the overall ecosystem of third-party tools.
Prompt chaining (Workflow: Prompt chaining)
An approach in which the task is broken down into a sequence of steps, with each LLM call processing the output of the previous one. To ensure that the process is carried out correctly, different checks can be added (see "gate" in the diagram below). And, accordingly, the complexity and length of the chain depend only on our task.
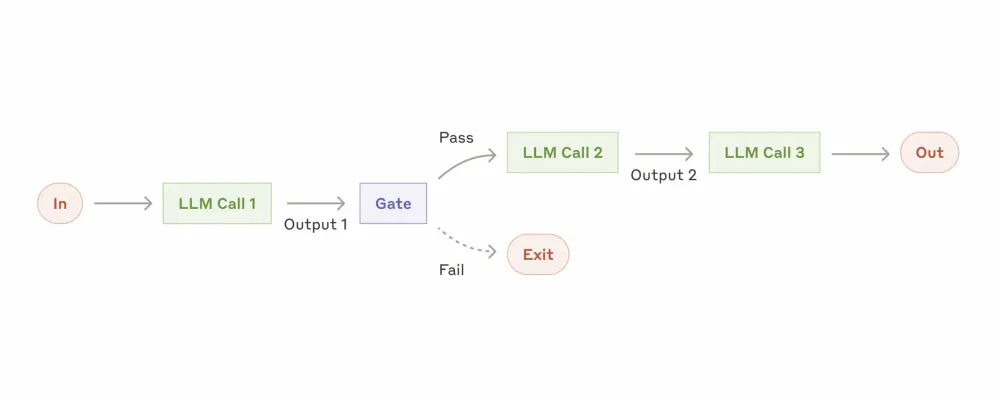
When to use prompt chaining: ideally, when the original task can be easily and clearly broken down into fixed subtasks. The main goal is to sacrifice speed for increased accuracy, assigning the LLM one simple task in each call.
Routing (Workflow: Routing)
The approach in which the input data is first classified and then sent to a more tailored and specialized prompt. That is, instead of processing everything with an LLM, we break down the input tasks by meaning, prepare a prompt for each, and then distribute them as needed.
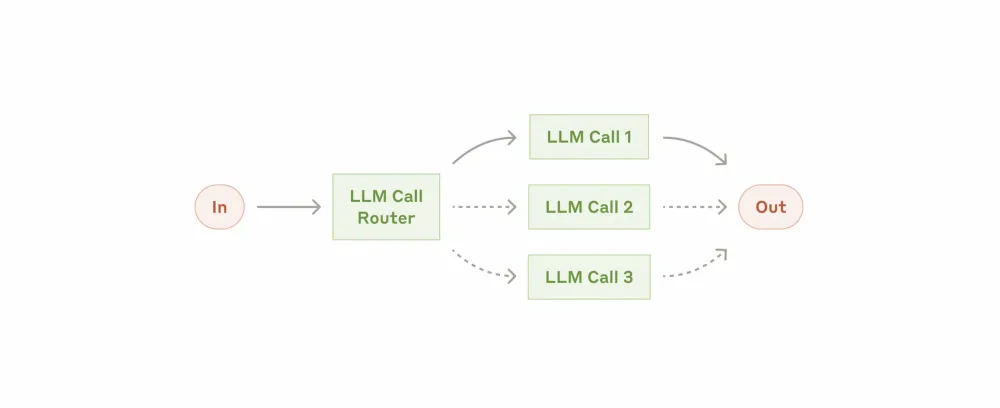
When to use routing: routing works well for tasks where there are clear categories that are better processed separately. It is very critical to correctly determine the required category: this can be done either by the LLM itself or, if possible, by conventional NLP methods.
Examples where routing is useful:
Different types of support requests (general questions, refund requests, mortgage questions, etc.)
Directing simple and unambiguous questions to a lighter LLM, and complex ones to a more powerful one
Workflow: Parallelization
Several LLMs can sometimes work on a task simultaneously, and the final decision is made by combining or aggregating their responses.
In fact, there are two approaches here:
Division: the task is divided into independent subtasks performed in parallel, and then everything is put together
Voting: the task is performed by several requests in parallel, and then a single answer is averaged
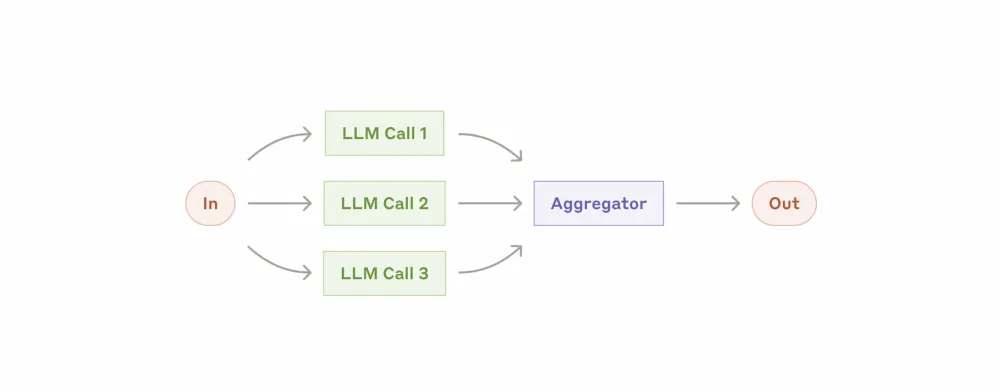
When to use parallelization: the approach is effective when the task can be divided and performed independently in parallel, or when a comprehensive answer is required. For complex tasks with many aspects, language models usually work better when each aspect is processed by a separate model call, as it remains in focus.
Examples where parallelization is useful:
Separation:
Protective mechanisms where one instance of the model processes user requests while another checks it for safety
Evaluation of something by several different parameters simultaneously
Voting:
Code vulnerability checking where several different requests with different prompts check the code
Evaluation of unacceptable content where multiple requests evaluate different aspects or require different threshold values of votes to balance false positives and false negatives
Orchestrator+workers (Workflow: Orchestrator-workers)
In this approach, the LLM dynamically breaks down tasks, delegates them to language model workers, and then synthesizes their results.
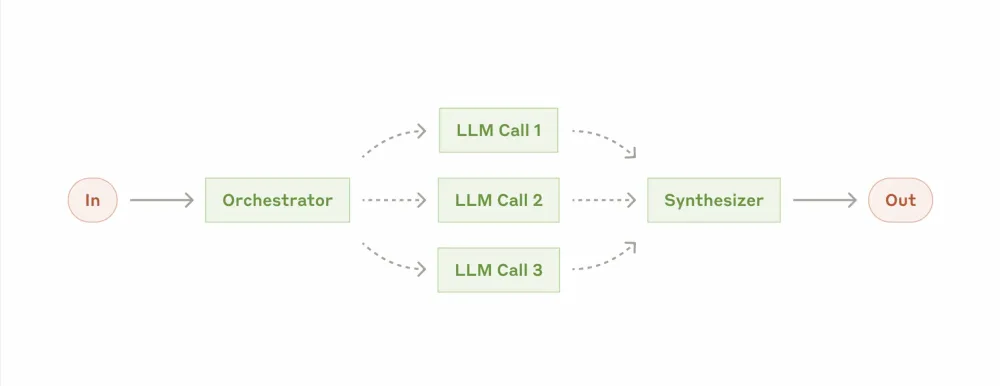
When to use orchestration: although topographically it resembles parallelization, the key difference lies in its flexibility — subtasks are not predefined but determined by the orchestrator based on the specific input request. Therefore, it is well-suited for complex tasks where it is impossible to predict the necessary subtasks in all cases.
Examples where orchestrator-workers are useful:
Writing code that may require changes in multiple files
Search tasks involving gathering and analyzing information from multiple sources
Evaluator and optimizer (Workflow: Evaluator-optimizer)
An approach where the LLM's response is sent to another LLM and until they agree with each other, there will be no final answer. That is, the response of the first LLM is iteratively improved based on feedback (evaluation) from the second until it reaches an acceptable threshold.
This is somewhat remotely similar to GAN, but here there is no competition and no one is trying to deceive anyone, and both roles play for a common result with positive feedback. A much closer analogy is an author and his kind reviewer.
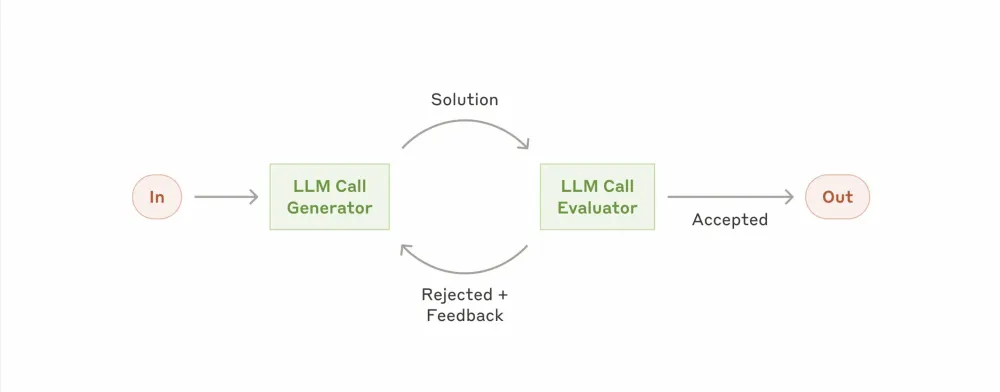
Examples where the evaluator-optimizer is useful:
Improving translation or writing of literary text
Complex search tasks that require multiple rounds of searching and analysis to gather comprehensive information, where the evaluator decides if further searches are needed
Agents
Here we come to what hardcore guys call agents.
Agents are becoming more widespread as language models improve in key capabilities — understanding complex inputs, reasoning and planning, reliable use of tools, and recovery from errors. Agents start their work either with a ready-made command from a human user or with an interactive discussion of the task with them. Once the task becomes clear, agents plan and act independently, referring to the human for additional information if necessary.
During execution, it is critical for agents to get the "true state of affairs" from the environment at each step (e.g., results of tool calls or code execution) to assess their progress. Agents can then pause to get feedback from the human at checkpoints or when encountering obstacles. The work stops either with the successful completion of the task or a certain number of unsuccessful attempts to solve it.
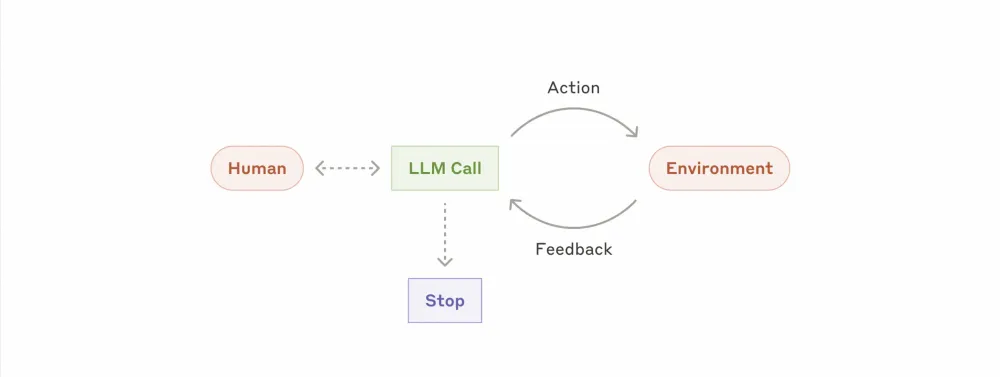
Technically, the agent scheme based on LLM looks like this: these are language models working in a loop with tools and receiving feedback from the environment. However, successful and safe implementation requires regular attention to detail and a deep understanding and elaboration of many aspects: from designing protection and preventing data leaks to creating monitoring, logging, and emergency stop mechanisms.
And therefore, the apparent simplicity of the basic implementation actually hides a lot of problems - as, in fact, always.
When to use agents: agents should be used for open tasks where it is difficult or impossible to predict the required number of steps, and where it is impossible to rigidly fix the sequence of steps. The language model will potentially work for many iterations, and you must have a certain level of trust in its decision making. The autonomy of agents makes them ideal for scaling tasks in trusted environments.
The autonomous nature of agents means higher costs and the possibility of accumulating errors, so it is recommended to use and test them first in a closed loop with all possible protection.
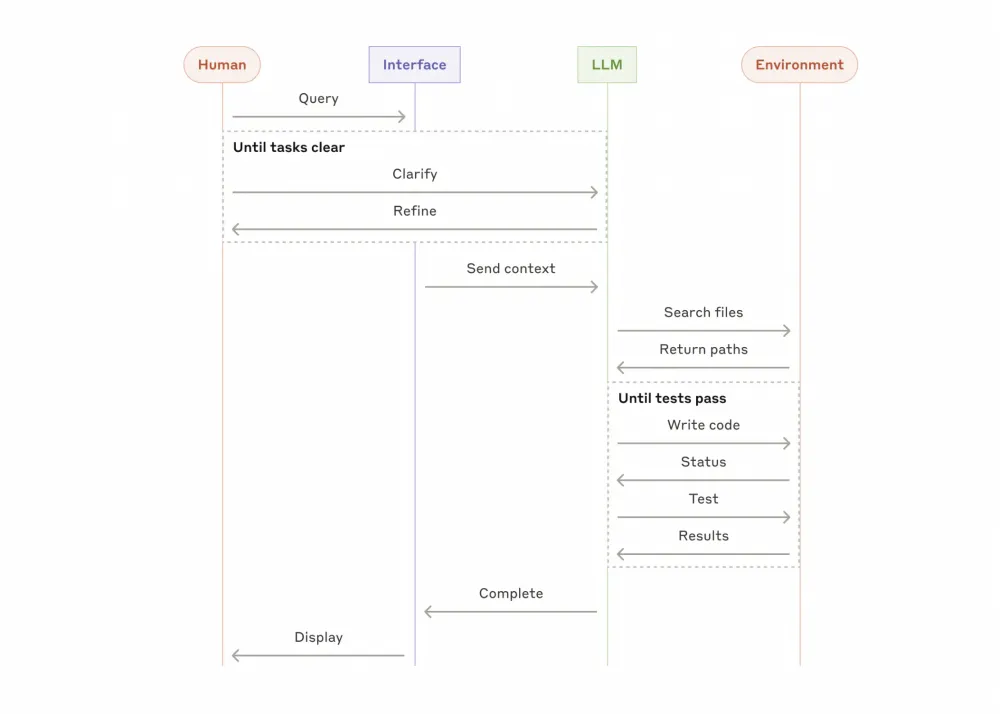
Examples where agents are useful:
A programming agent that can make the necessary changes to a large number of files
A feature with "using a computer" when the agent has access to the computer and the task, and then it tries to find a solution to the task itself
Combining approaches
All these approaches are just an attempt to systematize architectures with LLM and do not imply that this will easily solve the task. In real life, combinations of approaches are often found and something that works well appears only with iterative and regular improvement of the metrics we set.
And yes, the authors are very upset when something simple is tried to be solved in more complex ways.
Conclusions and results
Success lies not in creating the most complex system. Success lies in creating the right system to solve our problem. Agents are not needed where you can do without them. LLMs are not needed where you can do without them.
We start with the simple and gradually improve, adding new levels of complexity only when it is appropriate and when simple solutions definitely do not cope.
And here are the three main principles when building agents:
Maintain simplicity in the architectural design of your agent
Prioritize transparency, clearly showing the agent's planning steps
Thoroughly work out the agent's interaction interface, thoroughly documenting and testing the result
Frameworks can help you get started quickly, but for a production solution, it is worth doing everything at a lower level, and there is nothing wrong with that, as it will allow for greater control and transparency.
The original article also includes two practical examples of agents from the authors themselves: a customer support agent that handles inquiries well, and a code-writing agent, as well as an additional recommendation to carefully consider agent interfaces and test them more frequently.
And taking this opportunity, I would like to end with a joke, saying an additional thank you to the company Anthropic, which allowed me to come up with my family logo (see my surname in the nickname).

Thank you!









Write comment