
- AI
- A
How to easily add AI to Rust applications: a universal open-source tool
A system developer at Kryptonite IT company wrote an article about a new Rust tool that makes it easier to run machine learning models and integrate them into applications. Next, we publish the text in the first person.
Hello, tekkix! My name is Mikhail Mikhailov. I write in Rust and work as a system developer at the company "Kryptonit". In this article, I want to talk about a new tool in Rust that makes it easier to run machine learning models and integrate them into applications.
This is an efficient and versatile library (called a crate in Rust) with open source code, which we originally wrote for our own needs. With its help, you can run almost any ready-made ML model!
It supports not only professional Nvidia accelerators but also a wide range of consumer graphics cards of different generations (Maxwell, Pascal, Volta, Turing, Ampere, Ada Lovelace).
Just add AI!
Machine learning is everywhere: large language models, generative diffusion models, recommendation systems... Nowadays, it is difficult to find a subject area where someone has not inserted a "machine".
However, despite the wide possibilities of ML, working with it often seems too complicated. We have created a tool that will make working with ML easier for Rust developers. With it, you will see that this process is not only easily accessible but also endows your applications with incredible AI power!
Imagine a developer who does not understand the intricacies of ML but can download a ready-made model. Suppose he needs not just to embed someone else's model into his lightweight project, but to integrate it into an ambitiously high-load pipeline. At the same time, the developer is not ready to suffer—he is not a DevOps! He wants to get a simple and painless deployment. Based on these conditions, we have identified the following requirements for the ideal tool:
support for different model formats;
compatibility with a wide range of graphics cards;
versatility and efficiency;
conciseness and flexibility.
Popular solutions for integrating ML models
Before writing our own tool for efficient model deployment and operation, we analyzed existing solutions. Over time, we realized that none of them suited us for one reason or another.
For example, at first we launched models using bindings to TensorRT and CUDA engines. However, this method required compiling each model for a specific trio of TensorRT, CUDA, and GPU model versions.
As a result, we had to compile, test, and store each model 15 times (and we were still lucky!). I think few people would want to maintain such a zoo of models, and when deploying, guess which animal to pull out of there.
Another popular option is the Deepstream SDK. This is a closed-source product from Nvidia. It allows extremely efficient execution of computer vision (CV) pipelines. The price for performance is its versatility:
it is almost impossible to make changes to the source code;
the product works poorly with unstable video streams, which, together with the first point, leads to terrible pain during implementation;
it only works with video. And we want something omnivorous, ready to digest pictures, audio recordings... almost any models.
For quite a long time, we used infrastructure with a separately raised server on which models were executed. In such conditions, we tried Triton Inference Server and TensorFlow Serving. The second seemed worse to us in terms of versatility and efficiency, so we almost immediately discarded it.
For some time, we were generally satisfied with Triton Inference Server: we liked its flexibility, versatility, and reliability. However, as the load increased, we encountered inefficient data transfer. It goes over the network, which creates two problems:
The first was that the pipeline performance was limited by the internal network bandwidth. The second was deeper: in some scenarios, we had to copy data from the GPU and send it over the network, only to copy it back to the GPU again. This consumed a large percentage of resources and reduced overall performance.
When we got tired of putting up with it, we moved on to creating our own crate — Tritonserver-rs. It was decided to take the best of Triton Inference Server, abandoning the separately allocated server.
Own library in Rust
As a result, a crate was written based on wrappers to the Triton library in C (and to a lesser extent to the CUDA C libraries). It provides asynchronous request-response interaction with models inside a locally raised Triton Inference Server. Essentially, it is an open-source library with Triton C-lib and a couple of features under the hood.
Our tool allows embedding models into Rust applications, achieving high performance and effectively handling increasing loads. It is a versatile solution that supports different model formats (TensorFlow, ONNX, PyTorch, OpenVINO, custom format, and model pipelines).
Tritonserver-rs is versatile and especially convenient for those who build systems using multiple ML models. For example, we use pipelines for speech recognition and transcription systems, object tracking in video and their classification, as well as other typical AI tasks.
Because our crate is powered by Triton Inference Server, we inherit all its advantages:
convenient model configuration format;
single launch for all architectures, GPUs, and model formats out of the box;
working with multiple ML models simultaneously;
Prometheus support.
And thanks to writing a separate crate, we have access to the following features:
explicit server management within the pipeline (setting up automatic restart on error, model swapping on events, etc.);
custom memory management, including the ability to send requests with GPU data;
highly efficient library in Rust.
Suffice it to say that after the introduction of Tritonserver-rs, the speed of our video pipeline increased 4 times. That is, now we need half as many video cards to process the video stream from twice as many cameras.
Of course, there were also some downsides. Like 90% of cool stuff in the ML world, our tool is tailored for Nvidia hardware.
Deploying an AI application in a few minutes
We could talk for a long time about the abstract advantages of our crate, but it's better to analyze one clear example.
Below I will show you how to write an application based on an ML model in 3 simple steps using Tritonserver-rs. Let's create a program that takes an image as input, annotates all objects on it, and classifies them. Under the hood, there will be a standard model for this task YOLOv8.
Step 1
First, you need to collect all the models used and organize them in a specific way. Each model should be in a separate folder. This folder should contain the model config config.pbtxt, as well as various versions of this model.
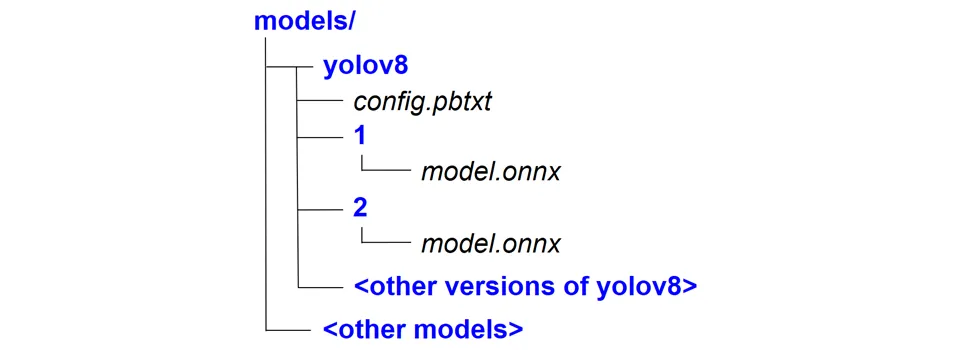
The standard model config looks like this:
name: "yolov8"
platform: "onnxruntime_onnx"
max_batch_size: 8
input [{
name: "IMAGE"
data_type: TYPE_FP32
dims: [3, 1280, 720]
}]
output [{
name: "PREDICTIONS"
data_type: TYPE_FP32
dims: [256]
}]
It specifies the model name, its format, desired optimizations, as well as all model inputs and outputs. The latter is a vector of structures containing the following parameters: the name of the input tensor, the data type, and the dimensions of this tensor.
This is where the complexities end.
Step 2: writing code
Add the crate to Cargo.toml:
[dependencies]
tritonserver-rs = "0.1"Start the local server:
let mut opts = Options::new("/models/")?;
opts.backend_directory("/path/to/backends/")?
.gpu_metrics(true)?;
let server = Server::new(opts).await?;Next, create the input data (in our case: open the image)
let image = image::ImageReader::open("/data/traffic.jpg")?.decode()?;
let input = Buffer::from(image.as_flat_samples_u8().samples);Create a request and attach the input to it.
let mut request = server.create_request("yolov8", 2)?;
request
.add_input("IMAGE", input)?
.add_default_allocator();Asynchronously wait for the model's response.
let response = request.infer_async()?.await?;
let result = response.get_output("PREDICTIONS");Step 3: deployment
As promised, deployment with Tritonserver-rs is extremely simple. Here's what it looks like using docker-compose.yml as an example:
my_app:
image: nvcr.io/nvidia/tritonserver:24.08-py3
volumes:
- ./application:/bin/application
- ./models:/models
- ./traffic.jpg:/data/traffic.jpg
entrypoint: ["/bin/application"]
First of all, you need to choose the version of the Triton server image you need. After that, you need to mount your compiled application, the necessary models, and input data into the image. You can immediately select your application as the entry point. Everything will work when the build starts!
So, in just 5 minutes, we wrote and launched an application with a machine vision system!

At the same time, we needed only 2 things to write the application: a ready-made model and basic knowledge about its inputs and outputs.
Need for speed!
We conducted a performance test of the crate using the example of a video pipeline that includes object detection and tracking. We compared the speed of Tritonserver-rs, Deepstream, and Triton Inference server. The latter was run in two modes. In the first, data was transmitted via grpc from a Rust application. In the second, CUDA pointers were passed directly to the model using a Python library.
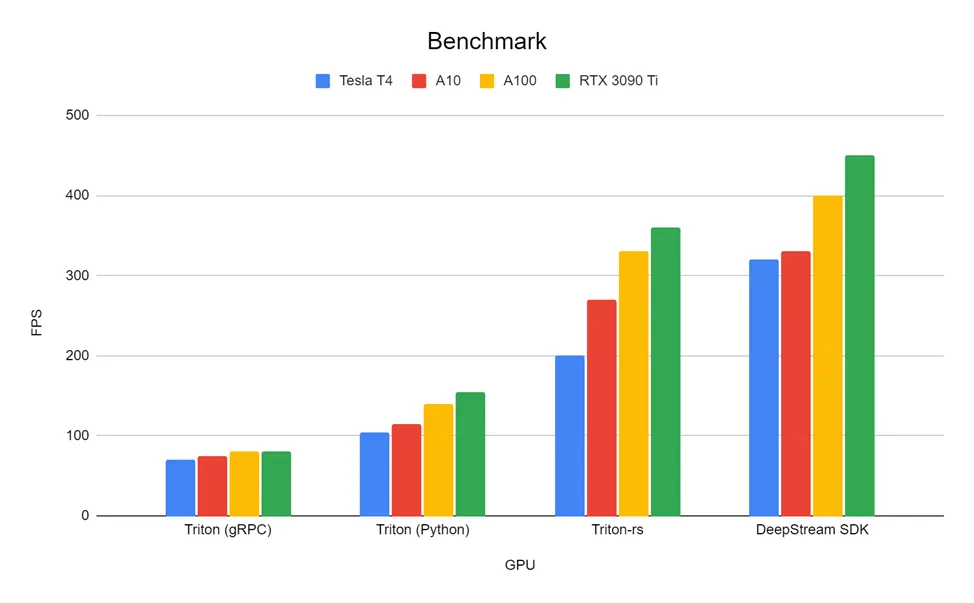
As you can see, our solution significantly outperforms the external Triton Server. Moreover, we are not far behind in speed from Deepstream, which is considered one of the most efficient video analytics tools originally designed for this task.
Due to its high performance, our crate can be safely deployed in production, which we did in our company. Moreover, our solution provides greater flexibility, ease of configuration, and application deployment.
Here is a link to the crate, examples, and documentation. Feel free to use it! If you have any questions, please ask them in the comments.
https://crates.io/crates/tritonserver-rs
https://github.com/3xMike/tritonserver-rs
https://github.com/3xMike/tritonserver-rs/tree/main/examples
https://docs.rs/tritonserver-rs
We are actively looking for new people to join our team — you can view vacancies on the Kryptonite career site.









Write comment